目标检测入坑指南2:AlexNet神经网络
学了蛮久的目标检测了,但是有好多细节总是忘或者模棱两可,感觉有必要写博客记录一下学习笔记和一些心得,既可以加深印象又可以方便他人。博客内容集成自各大学习资源,所以图片也就不加水印了,需要自取。本专栏会详细记录本人在研究目标检测过程中的所学所感,主要包括:1.目标检测算法解读,如R-CNN系列、YOLO系列;2.论文阅读笔记;3.其它目标检测相关的概念和技巧,如attention机制的应用。由于水平有限,不少地方可能会有不准确甚至错误,也希望大家多多包涵并指正一下!
文章目录
- 一、引言
- 二、创新点
-
- 1. 非线性激活函数ReLU
- 2. 多种避免过拟合的手段
- 3. 多GPU训练
- 4. 局部响应归一化
- 三、网络结构
-
- 1. 卷积层C1
- 2. 卷积层C2
- 3. 卷积层C3和C4
- 4. 卷积层C5
- 5. 全连接层F1和F2
- 6. 全连接层F3
- 四、实例演示

一、引言
目标检测整体的框架是由backbone、neck和head组成的,所以在学习具体的目标检测算法之前,有必要了解一下常见的卷积神经网络结构,这有利于后面学习目标检测算法的backbone部分。AlexNet虽然结构比较简单,但是刚好适合入门,为后续学习打下基础。
AlexNet是由2012年ImageNet竞赛参赛者Hinton(神经网络的坚守者)和他的学生Alex Krizhevsky设计的,该网络在当年赢得了ImageNet图像分类竞赛的冠军,使得CNN成为图像分类的核心算法模型,同时引发了神经网络的应用热潮。
二、创新点
1. 非线性激活函数ReLU
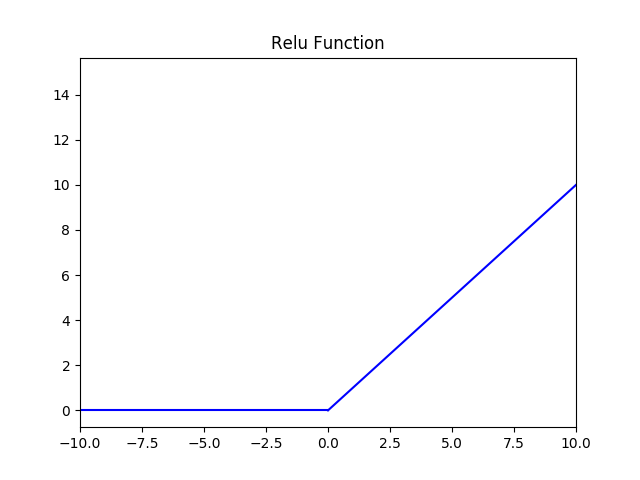
在AlexNet出现之前,人们常常用sigmoid或者tanh作为激活函数。sigmoid函数能够把输入的连续实数压缩到0到1之间,但是当输入值非常小时会出现饱和现象,即这些神经元的梯度非常接近0,因此存在梯度消失问题,此外这个函数不是关于原点对称的,并且计算exp比较耗时。tanh虽然解决了原点对称问题,并且比sigmoid函数更快,但是依旧没有解决梯度消失的问题。ReLU函数解决了部分梯度消失的问题,其表达式为F(x)=max(0, x),即当输入小于0时输出也为0,当输入大于等于0时,输出等于输入。由于ReLU函数的导数始终是1,所以计算量减少了很多,AlexNet的作者也在实验中证明了ReLU的收敛速度要比sigmoid和tanh更快。
2. 多种避免过拟合的手段
AlexNet有超过6千万个参数,纵使ILSVRC比赛有大量训练数据,也难以支撑如此庞大的参数训练,这就会导致严重的过拟合问题。在机器学习中,如果模型过拟合,那么得到的模型基本不能用。具体表现在:模型在训练数据上损失函数小(偏差小),预测准确率高,但是在测试数据上损失函数大(方差大),预测准确率低。AlexNet采用了augmention和dropout的方式来避免过拟合。
首先是数据增强。在图像领域,数据增强是最简单也是最常用的避免过拟合的方法。常见的数据增强操作主要是旋转、平移、翻转、缩放、裁剪等等,再后来目标检测领域又出现了一系列数据增强的技巧,如MixUp、Mosaic,将在后续的博客中介绍。
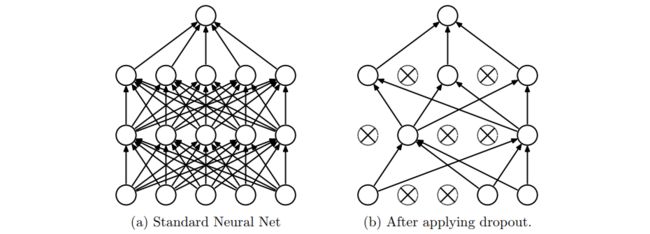
然后是dropout。它可以看作是一种模型平均,即把来自不同模型的估计或者预测通过一定权重进行平均。具体做法就是在每次训练的前向传播阶段,以一定概率(通常是0.5)让某个神经元失活(激活值设置为0)。这样做可以减少神经元之间的相互作用,以免某些神经元只有依赖其他神经元才能发挥作用(或者说某些特征仅在特定特征下才有效果),提升了模型的泛化性。
3. 多GPU训练
单个GPU的memory限制了网络的训练规模,采用多GPU协同训练,可以大大提高AlexNet的训练速度。
4. 局部响应归一化

局部响应归一化(local response normalization,LRN)的思想来源于生物学中的“侧抑制”,是指被激活的神经元抑制相邻的神经元。采用LRN的目的是为了将数据分布调整到合理的范围内,便于计算处理,从而提高泛化能力。虽然ReLU函数对较大的值也有很好的处理效果,但作者还是采用了LRN。下面是论文中给出的公式:
b x , y i = a x , y i / ( k + α ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a x , y j ) 2 ) β \color{red}b_{x,y}^{i}=a_{x,y}^{i}/(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{j})^{2})^{\beta} bx,yi=ax,yi/(k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yj)2)β
其中, a x , y i a_{x,y}^{i} ax,yi表示第i个卷积核在(x, y)处经过卷积、池化、ReLU函数计算后的输出,相当于该卷积核提取的局部特征。N表示这一层的卷积核总数;n表示在同一位置的临近卷积核个数(预先设定);k、α、β都是超参数。
假设在网络的某一层N=20,超参数按照论文设定:n=5、k=2、α=0.0001、β=0.75。第5个卷积核在(x, y)处提取了特征 a x , y 5 a_{x,y}^{5} ax,y5,那么 ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)} ∑j=max(0,i−n/2)min(N−1,i+n/2)就是以第5个卷积核为中心,选取前后各5/2=2个(向下取整,n所指的卷积核个数是包含中心卷积核的)卷积核,所以有下标里的max=3,上标里的min=7,卷积核个数就是3、4、5、6、7。
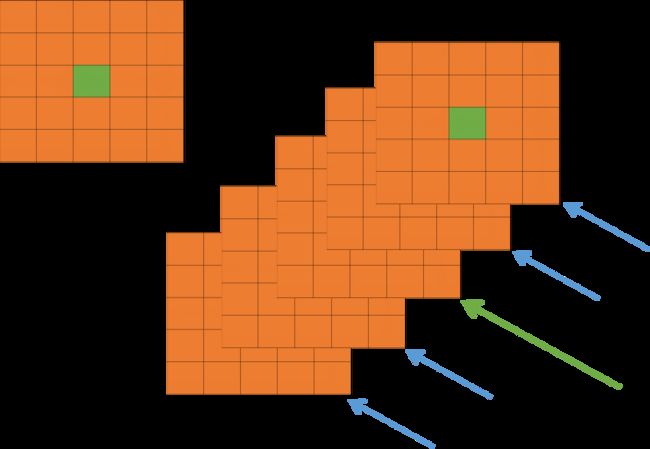
通过上述公式,可以使得每个局部特征都被缩小,相当于进行了范围控制:一旦在某个卷积核周围提取的特征比它自己提取的特征的值大,那么该卷积核提取的特征就会被缩小;相反,如果某个卷积核周围提取的特征比它自己提取的特征的值小,那么该卷积核提取的特征被缩小的比例就会变小,最终的值与周围卷积核提取的特征的值相比就显得比较大了(都是缩小,只是缩小比例不同)。
三、网络结构
AlexNet的网络结构非常简单,就是一系列卷积层的堆叠,最后接几个全连接层。下面以(227, 227, 3)的输入为例,来推导一下每一层的输入输出尺寸,这对于全连接层的设计来说是必不可少的工作。PyTorch中是把通道数放在了图像尺寸前面,但是出于视觉习惯,这里把通道数放在了最后,方便大家理解。

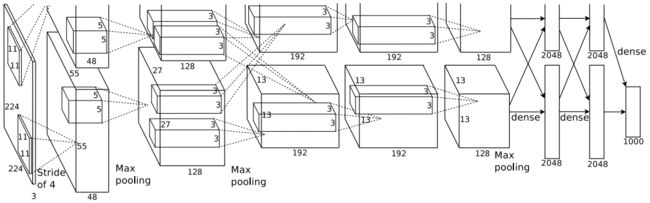
1. 卷积层C1
这一层会有96个11×11×3的卷积核进行特征提取,stride=1,padding=0,卷积后得到的特征图尺寸为(55, 55, 96)。由于上图中使用了双GPU,所以图中每个GPU(分支)处理的卷积核个数都是48个。然后,再使用ReLU函数将值限定在合适的范围,接着用3×3的滤波器进行步长为2的池化操作,得到(27, 27, 96)的特征图,最后进行归一化处理,将结果输入进下面的C2层。
2. 卷积层C2
C2层与C1层是类似的操作步骤,ReLU和池化操作一模一样。这一层会有256个5×5×96的卷积核,stride=1,padding=2,最后会生成(27, 27, 256)的特征图输入进下面的C3层。
3. 卷积层C3和C4
C3层和C4层类似,也都是卷积层,但是和C1层/C2层不同的是,这2层仅仅进行了卷积核ReLU操作,没有后续的池化和归一化操作。C3层的每个GPU都有192个3×3×256的卷积核(所以两个GPU加起来是有384个卷积核的),stride=1,padding=1,这样每个GPU都会得到(13, 13, 192)的特征图。
C4层和C3层的最大区别是,C4层只接受所在GPU的输出,注意看上图中卷积核的映射虚线,C3层是接收了C2层两个GPU的全部输出的。同样,C4层的每个GPU都有192个3×3×256的卷积,stride=1,padding=1,这样每个GPU都会得到(13, 13, 192)的特征图,然后两个层都会用ReLU函数进行处理,最后将结果输给下面的C5层。
4. 卷积层C5
C5层又略有区别,它会依次进行卷积、ReLU和池化操作,不进行归一化操作。和C4层一样,这一层的每个GPU都接受本GPU中的C4层输出作为输入,每个GPU有128个3×3×192的卷积核,stride=1,padding=1,生成(13, 13, 128)的特征图,池化操作滤波器的尺寸是2×2,stride=2,最终得到(6, 6, 128)的特征图输入到下面的F1层(两个GPU共256个特征图)。
5. 全连接层F1和F2
从这里开始,后面就都是全连接层了。F1层仍然按GPU进行卷积,每个GPU用2048个6×6×256的卷积核,这意味着每个GPU都会接收C5层里两个GPU的输出。卷积后,每个GPU都会生成(1, 1, 2048)的特征图,再经过ReLU和dropout操作后,两个GPU共输出4096个值。
F2层和F1层的操作步骤一模一样,和F1层进行全连接,最后共输出4096个值。
6. 全连接层F3
F3层只进行全连接操作,一共有1000个神经元,最终输出1000个float值,即为预测结果(ImageNet图像分类比赛共有1000个图像类别)。
四、实例演示
下面的代码里没有用到局部响应归一化操作,而是在每个卷积操作后加上了Batch Normalization(批标准化)操作。此外,没有根据论文中设置2个GPU训练,所以Conv2d方法的参数会稍有变化。具体有什么样的区别会带来什么样的影响,大家可以自己做个对比试一试。
from torch import nn
import torch
class AlexNet(nn.Module):
def __init__(self, dim, num_classes):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=dim, out_channels=96, kernel_size=11, stride=4, padding=0),
nn.BatchNorm2d(96),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(384),
nn.ReLU(inplace=True),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(384),
nn.ReLU(inplace=True),
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2)
)
self.fc = nn.Sequential(
nn.Linear(in_features=9216, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=num_classes)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = x.view(x.size(0), -1)
output = self.fc(x)
return output
可以把以下FlattenLayer加在全连接层容器最前面,来替换掉forward里的x.view,用下面的代码查看各层输出的尺寸:
class FlattenLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x.view(x.size(0), -1)
net = AlexNet(3, 1000)
X = torch.rand(1, 3, 227, 227)
for block in net.children():
X = block(X)
print('output shape: ', X.shape)
得到的输出结果如下:
output shape: torch.Size([1, 96, 27, 27])
output shape: torch.Size([1, 256, 13, 13])
output shape: torch.Size([1, 384, 13, 13])
output shape: torch.Size([1, 384, 13, 13])
output shape: torch.Size([1, 256, 6, 6])
output shape: torch.Size([1, 1000])