2D DenseUnet-based脑胶质瘤分割BraTs+论文翻译+代码实现
论文代码:
https://github.com/NYUMedML/DARTS
1、摘要
Quantitative, volumetric analysis of Magnetic Resonance Imaging (MRI) is a fundamental way researchers study the brain in a host of neurological conditions including normal maturation and aging. Despite the availability of open-source brain segmentation software, widespread clinical adoption of volumetric analysis has been hindered due to processing times and reliance on manual corrections. Here, we extend the use of deep learning models from proof-of-concept, as previously reported, to present a comprehensive segmentation of cortical and deep gray matter brain structures matching the standard regions of aseg+aparc included in the commonly used open-source tool, Freesurfer. The work presented here provides a real-life, rapid deep learning-based brain segmentation tool to enable clinical translation as well as research application of quantitative brain segmentation. The advantages of the presented tool include short (∼ 1 minute) processing time and improved segmentation quality. This is the first study to perform quick and accurate segmentation of 102 brain regions based on the surface-based protocol (DMK protocol), widely used by experts in the field. This is also the first work to include an expert reader study to assess the quality of the segmentation obtained using a deep-learning-based model. We show the superior performance of our deep-learning-based models over the traditional segmentation tool, Freesurfer. We refer to the proposed deep learning-based tool as DARTS (DenseUnet-based Automatic Rapid Tool for brain Segmentation). Our tool and trained models are available at https://github.com/NYUMedML/DARTS
磁共振成像(MRI)的定量、容积分析是研究人员在包括正常成熟和老化在内的一系列神经条件下研究大脑的基本方法。尽管有开源的脑分割软件,但由于处理时间和依赖人工校正,体积分析在临床上的广泛应用受到了阻碍。在这里,我们扩展了深度学习模型的使用,从概念证明,如前所述,提出了一个皮质和深灰质脑结构的全面分割,匹配aseg+aparc的标准区域,包括在常用的开源工具Freesurfer中。本文的工作为临床翻译和定量脑分割的研究应用提供了一个真实、快速、基于深度学习的脑分割工具。该工具具有处理时间短(1分钟)和分割质量好等优点。这是第一个基于领域专家广泛使用的基于表面的协议(DMK协议)对102个脑区进行快速准确分割的研究。这也是第一个工作,包括一个专家读者研究,以评估质量的分割获得使用一个深学习为基础的模型。与传统的分割工具Freesurfer相比,我们展示了基于深度学习的模型的优越性能。我们将提出的基于深度学习的工具称为DARTS(基于DenseUnet的自动快速大脑分割工具)。我们的工具和经过培训的模型可以在https://github.com/NYUMedML/DARTS上找到。
1、介绍
Quantitative regional brain volumetrics have been used to study nearly every neurological, developmental and behavioral condition known, from normal aging[40, 9, 42], to schizophrenia[48] to dementia[4, 10, 39, 13, 14], to multiple sclerosis[12, 1] and hydrocephalus [11], just to name a few. Semi-automated segmentation tools have been widely applied for this task, providing measures of whole-brain and regional brain volumes [17],[25]. Segmentation is useful for multiple other research tasks such as coregistration with other imaging modalities (e.g., functional MRI, diffusion MRI, Positron emission tomography) and anatomical localization. Influential research initiatives including the Human Connectome Project [49], Alzheimer’s Dementia Neuroimaging Initiative (ADNI) [41], National Alzheimer’s Coordinating Center (NACC) [2], and the UKBioBank [46] rely on traditional brain segmentation tools to provide quantitative measures to researchers.
定量的区域脑容量已经被用来研究几乎所有已知的神经、发育和行为状态,从正常衰老[40,9,42],到精神分裂[48]到痴呆[4,10,39,13,14],再到多发性硬化[12,1]和脑积水[11],仅举几个例子。半自动分割工具已经广泛应用于这项任务,提供了全脑和区域脑容量的测量[17],[25]。分割对于多个其他研究任务,如与其他成像方式(如功能性磁共振成像、扩散磁共振成像、正电子发射断层成像)和解剖定位,都是有用的。有影响力的研究计划包括人类连接体项目[49]、阿尔茨海默病痴呆症神经成像计划(ADNI)[41]、国家阿尔茨海默病协调中心。协调中心(NACC)[2]和UKBioBank[46]依靠传统的大脑分割工具为研究人员提供定量测量。
Traditional semi-automated methods are based on Markov random fields and apply boundary determination methods to separate cortical gray matter from subcortical white matter. Despite such tools 1) being available through both open source [17] and commercial visualization products for decades, and 2) having clear potential utility, this technology has failed to translate well to routine clinical care, in part due to the need for manual corrections and off-line processing that can take hours even with modern computing capabilities. In the clinical setting, these aspects place significant practical barriers to successful implementation.
传统的半自动方法是基于马尔可夫随机场,应用边界确定方法将皮质灰质与皮质下白质分离。尽管这些工具1)已经通过开源[17]和商业可视化产品提供了几十年,2)具有明显的潜在效用,但这项技术未能很好地转化为常规临床护理,部分原因是需要人工更正和离线处理,即使使用现代计算能力,也可能需要数小时。在临床环境中,这些方面为成功实施设置了重大的实际障碍。
Recent innovations using deep learning for solving problems in computer vision have resulted in a revolution in medical imaging [32]. In particular, there have been novel developments using deep learning for medical imaging segmentation tasks [44, 37, 31, 7].
最近,利用深度学习解决计算机视觉问题的创新已经在医学成像领域引发了一场革命[32]。特别是,在医学影像分割任务中使用深度学习有了新的发展[44,37,31,7]。
Previous efforts applying deep-learning-based models to a brain segmentation task [6, 45, 50, 3, 5, 15] provide proof of concept that segmentation for coarse regions of interest (ROIs) (∼ up to 35 regions) is promising. The major practical limitation of these prior works is incomplete segmentation of the brain into finer anatomic regions which are typically available through traditional tools like Freesurfer. There are substantial challenges in terms of how to approach the segmentation of these finer anatomic regions, relating to the small size of these regions containing relatively few voxels and the resulting class imbalance.
先前将基于深度学习的模型应用于大脑分割任务[6,45,50,3,5,15]的研究证明了粗感兴趣区域(roi)的分割(最多35个区域)是有前途的。这些先前工作的主要实际限制是不完整地将大脑分割成更精细的解剖区域,这些区域通常可以通过像Freesurfer这样的传统工具获得。在如何分割这些精细的解剖区域方面存在着巨大的挑战,因为这些区域的体积很小,包含的体素相对较少,从而结果种类不平衡。
Here, we extend the use of deep-learning-based models to perform segmentation of a complete set of cortical and subcortical gray matter structures and ventricular ROIs, matching the regions included in the commonly used, standard tool, Freesurfer (aseg+aparc segmentation libraries), to provide a real-life rapid brain segmentation tool. We employ a weighted loss function, weighing each ROI in inverse proportionality to its average size to address the extreme class imbalance. Additionally, we use dense convolutions in the U-net architecture and show that such architecture (called DenseUNet) provides us substantial gains over the baseline U-net model in terms of Dice Score improvement.
在这里,我们扩展了基于深度学习的模型的使用,以执行一整套皮质和皮质下灰质结构和心室roi的分割,匹配常用的标准工具Freesurfer(aseg+aparc分割库)中包含的区域,以提供一个真实的快速脑分割工具。我们采用加权损失函数,将每个投资回报率与其平均规模成反比,以解决极端的类别失衡问题。此外,我们在U-net架构中使用了密集卷积,并表明这种架构(称为DenseUNet)在dice系数得分改进方面比基线U-net模型提供了实质性的收益。
We assess both the quality of segmentation obtained using our deep-learning-based model and time required for segmentation compared against standard Freesurfer segmentation using both quantitative indices as well as expert evaluation. To our knowledge, this is the first report with accompanying source code of a practical tool that can be used both in a research setting to augment standard prior methods as well as in clinical settings to provide fast and accurate quantitative brain measures.
我们使用基于深度学习的模型对分割质量和分割所需时间进行了评估,并与使用定量指标和专家评估的标准自由曲线分割进行了比较。据我们所知,这是第一份报告,附有一个实用工具的源代码,既可以在研究环境中使用,以增强标准先前方法,也可以在临床环境中使用,以提供快速和准确的定量大脑测量。
2、相关工作
2.1 大脑分割的相关工具
Many different brain segmentation tools such as Freesurfer [17], STAPLE [52] and PICSL [51] are currently used by neuroimaging researchers and radiologists. All of these tools are based on atlas registration via nonrigid registration methods, which are computationally expensive during inference. Of the tools mentioned above, Freesurfer is one of the most commonly used tools. Freesurfer is based on topological surface mappings to detect gray/white matter boundaries followed by nonlinear atlas registration and nonlinear spherical surface registration for each sub-cortical segment. Each step involves an iterative algorithm, and the surface registration is based on inference on Markov Random Fields (MRF) initially trained over manually labeled datasets[17, 43]. Despite the surface registration method being spatially non-stationary, due to 1) non-convex nature of the model, 2) subject- and pathology-specific histological factors that impacts intensity normalization, and 3) iterative process for finding optimal segmentation, Freesurfer creates different results under different initialization settings, even for the same scan. It is known that Freesurfer outputs different results if the previous scans of the patient are taken into account [43]. First released in 2006, Freesurfer has been used innumerable times by researchers, saving the need to perform complete manual segmentation of brain MRIs, which was the prior standard; however, the methodology employed by this tool and others like it suffer from some inherent limitations. Specifically, each transformation of Freesurfer on a single brain volume is computationally intensive and the time required to segment a single 3D MRI volume can be on the order of hours. Additionally, the quality of segmentation of such MRF-based models is also lower than the deep-learning-based models which are demonstrated in the reader study performed in this report. Similar limitations plague all of the other traditional tools.
许多不同的大脑分割工具,如Freesurfer[17]、STAPLE[52]和PICSL[51]目前正被神经成像研究人员和放射科医生使用。所有这些工具都是基于atlas的非刚性配准方法,在推理过程中计算量大。在上面提到的工具中,Freesurfer是最常用的工具之一。Freesurfer基于拓扑曲面映射来检测灰质/白质边界,然后对每个亚皮质段进行非线性atlas配准和非线性球面配准。每一步都涉及一个迭代算法,而表面配准是基于最初在人工标记数据集上训练的马尔可夫随机场(MRF)的推断[17,43]。尽管表面配准方法在空间上是非平稳的,因为1)模型的非凸性,2)影响强度标准化的特定于主题和病理的组织学因素,以及3)寻找最佳分割的迭代过程,Freesurfer在不同的初始化设置下创建不同的结果,甚至同样的扫描。众所周知,如果考虑到病人先前的扫描,Freesurfer会输出不同的结果[43]。2006年首次发布的Freesurfer已经被研究人员使用了无数次,省去了对大脑MRIs进行完全手工分割的需要,这是先前的标准;然而,该工具和其他类似工具所采用的方法受到一些固有的限制。具体地说,Freesurfer在单个脑体积上的每次转换都是计算密集型的,分割单个3D MRI体积所需的时间可以是几个小时。此外,这种基于MRF的模型的分割质量也低于本报告中读者研究中展示的基于深度学习的模型。类似的局限性困扰着所有其他传统工具。
2.2 基于深度学习的大脑分割工具/模型
With the advent of deep learning methods for computer vision tasks like classification, object detection, and semantic segmentation, some of the inherent limitations of traditional image processing methods were resolved [30]. Consequently, these techniques were employed in several application domains including segmentation of brain cortical structures. Researchers have approached the task of segmentation of brain both by using 2D slices [53, 36] and 3D volumes as inputs [50, 23, 5, 15]. Despite 3D models naturally utilizing 3D structural information inherent in brain anatomy, it has been shown that such models do not necessarily yield superior results [18, 36]. Additionally, they tend to be computationally more expensive and therefore slower during inference. 3D-based whole volume methods also require a pre-defined number of slices through the brain volume as input and, in practice, the number of slices varies between protocols, making such models potentially less generalizable. Researchers including [23], and [50] have attempted to address the computational cost by training on volumetric patches; however, inference time remains relatively long (DeepNA T requires ∼1-2 hours and SLANT takes ∼15 mins using multiple GPUs). [53] and [36] have performed segmentation using patches from a 2D slice through the brain, offering 3 and 10 segments respectively. But compared with the over 100 segments available via Freesurfer, these few segments limit the tools’ practical utility. In order to take advantage of 3D information while keeping the computational cost low, in QuickNat [45], 2D convolutional neural networks in multiple planes have been trained and combined, but this also requires a complete 3D volume with voxel resolution being 1mm3. To perform such a preprocessing, Freesurfer is needed. Additionally, QuickNat only provides coarse segmentation for ∼ 30 ROIs making it less usable for clinical purposes.
随着用于计算机视觉任务(如分类、目标检测和语义分割)的深度学习方法的出现,传统图像处理方法的一些固有局限性得到了解决[30]。因此,这些技术被应用于多个应用领域,包括大脑皮层2结构的分割。研究人员已经通过使用二维切片(53,36)和三维体积作为输入(50,23,5,15)来完成大脑分割的任务。尽管三维模型自然地利用了大脑解剖学中固有的三维结构信息,但已经证明,这种模型并不一定会产生优越的结果[18,36]。此外,它们往往在计算上更昂贵,因此在推理过程中速度较慢。基于3D的整体体积方法还需要预先定义脑体积的切片数量作为输入,实际上,不同协议之间的切片数量不同,这使得此类模型可能不太通用。包括[23]和[50]在内的研究人员试图通过对体积块的训练来解决计算成本问题;然而,推断时间仍然相对较长(DeepNA T需要1-2小时,使用多个gpu进行倾斜需要15分钟)。[53]和[36]已经使用从二维切片到大脑的补丁进行了分割,分别提供了3个和10个片段。但与Freesurfer提供的100多个片段相比,这几个片段限制了工具的实用性。为了在保持低计算成本的同时充分利用三维信息,QuickNat[45]对多个平面上的二维卷积神经网络进行了训练和组合,但这也需要一个体素分辨率为1m3的完整三维体。要执行这样的预处理,需要Freesurfer。此外,QuickNat只为∼30个roi提供了粗略的分割,这使得它在临床上不太可用。
These prior works like [23] and [50] clearly show the promise that deep learning models can be used for segmenting the brain into anatomic regions; however, in some prior models, the potential benefit in computation derived from using a deep-learning-based approach is negated by the need for slow pre-processing steps (e.g. registration, intensity normalization, conforming in [23] ) or post-processing steps (e.g., Conditional Random Field in [50]) that are required for these tools to operate. These steps increase the computational cost of the complete pipeline and render them slower. In summary, our goal is to provide a tool with high accuracy, short inference time and sufficient brain segments to be useful in current research practice and clinical applications.
这些先前的工作,如[23]和[50]清楚地表明,深度学习模型可以用于将大脑分割成解剖区域;然而,在一些先前的模型中,由于需要缓慢的预处理步骤(如注册、强度),使用基于深度学习的方法在计算方面的潜在益处被否定规范化,符合[23]或后处理步骤(例如,[50]中的条件随机场),这些工具需要操作。这些步骤增加了整个管道的计算成本,并使它们变慢。总之,我们的目标是提供一个高精度、短推理时间和足够的脑段在当前研究实践和临床应用中有用的工具。
Contributions of this work are as follows:
- To the best of our knowledge, this is the first presentation of a truly practical, deep-learning-based brain segmentation tool that can >provide accurate segmentation of over 100 brain structures, matching regions found in aseg+aparc segmentation libraries from one of the leading industry-standard, registration-based tools, Freesurfer.
- Here, we leverage the benefits of using a surface-based approach (specifically DMK protocol) for brain segmentation.
- We impose no additional, registration-based pre-processing or post-processing steps and achieve inference times of ∼1 minute using just a single GPU machine.
- We show an excellent generalization of our model to different MRI scanners and MRI volumetric acquisition protocols.
- In addition to quantitative assessments against Freesurfer segmented data, we also evaluate our model against manually segmented data and perform an expert reader study to assess the quality of our segmentation tool.
这项工作的贡献如下:
- 据我们所知,这是一个真正实用的、基于深度学习的大脑分割工具的首次展示,该工具可以提供100多个大脑结构的精确分割,匹配aseg+aparc分割库中的区域,这些区域来自于领先的行业标准之一,基于注册的工具Freesurfer。
- 在这里,我们利用了使用基于表面的方法(特别是DMK协议)进行大脑分割的好处。
- 我们不需要额外的、基于注册的预处理或后处理步骤,仅使用一台GPU机器就可以实现1分钟的推理时间。
- 我们将我们的模型推广到不同的核磁共振扫描仪和磁共振容积采集协议。
- 除了针对Freesurfer分段数据的定量评估外,我们还针对手动分段数据评估我们的模型,并执行专家读者研究以评估我们的分段工具的质量。
3、方法
3.1数据
The training data comes from the Human Connectome Project (HCP) [19]. Specifically, we used 3D image volumes from a Magnetization Prepared Rapid Acquisition Gradient Echo (MPRAGE) volumetric sequence obtained as part of the HCP protocol. These images were acquired at multiple sites at 3 Tesla (Connectome Skyra scanners; Siemens, Erlangan) with the following parameters: FOV = 224mm x 224mm, resolution = 0.7mm isotropic, TR/TE = 2400/2.14 ms, bandwidth = 210 Hz/pixel. Each MRI volume has a dimension of 256 × 256 × 256. For training the model, a 2-D coronal slice of the MRI volume was used as the input. The coronal plane was selected based on superior performance in our preliminary experiments compared to axial and sagittal. The box-plots for the dice scores of these experiments can be seen in the appendix section (Figures 20, 21, 18, and 19). Freesurfer segmentation results processed for the HCP ([19]) were used as auxiliary ground truth for initial training of the models. These segmentation results had undergone manual inspection for quality control [33]. Further, to fine-tune the model, we used two additional data sources: manually segmented data by [27] and Freesurfer segmented, manually corrected NYU data.
训练数据来自人类连接体项目(HCP)[19]。具体来说,我们使用磁化制备的快速采集梯度回波(MPRAGE)体积序列的3D图像体积作为HCP协议的一部分。这些图像在3台Tesla(Connectome Skyra扫描仪;Siemens,Erlangan)的多个站点上采集,参数如下:FOV=224mm x 224mm,分辨率=0.7mm各向同性,TR/TE=2400/2.14ms,带宽=210hz/像素。每一个磁共振体的尺寸为256×256×256。为了训练模型,我们使用了一个磁共振体积的二维冠状切片作为输入。在我们的初步实验中,冠状面的选择是基于相对于轴向和矢状面的优越性能。这些实验的骰子分数的方框图可以在附录部分看到(图20、21、18和19)。为HCP([19])处理的自由曲面分割结果被用作模型初始训练的辅助地面真值。这些分割结果已经过手动检查以进行质量控制[33]。此外,为了对模型进行微调,我们使用了两个额外的数据源:由[27]手动分割的数据和由Freesurfer分割、手动校正的纽约大学数据。
Initially, we focused on 112 regions per individual 3D brain volume based on Freesurfer (aseg+aparc) labels. Figure 8 and figure 9 show the voxel distribution of the 112 segments in our study, revealing a class imbalance challenge:
only a few regions are large (>60000 voxels) whereas most of the regions are significantly smaller (<20000 voxels). The class imbalance challenge is addressed in section 3.6. The following 10 regions were excluded from the analysis: segments labeled left and right ’unknown’, four brain regions not common to a normal brain: White matter and non-white matter hypointensities and left and right frontal and temporal poles, and segments without widely accepted definitions in the neuroradiology community (left and right bankssts) [27].
最初,我们基于Freesurfer(aseg+aparc)标签对每个3D脑体积的112个区域进行了研究。图8和图9显示了我们研究中112个片段的体素分布,揭示了一个类不平衡的挑战:
少数区域是大的(>60000个体素),而大多数区域是明显较小的(<20000个体素)。第3.6节讨论了班级失衡问题。以下10个区域被排除在分析之外:左侧和右侧标记为“未知”的部分,四个与正常大脑不常见的大脑区域:白质和非白质低强度区以及左侧和右侧额叶和颞叶极,在神经放射学界没有被广泛接受的定义的片段(左和右banksts)[27]。
We randomly divided the cohort into training, validation and (held out) test sets with 60% (667 scans), 20% (222 scans) and 20% (222 scans) ratio. We separated training, validation and held-out test sets according to patients rather than slices to prevent data leakage.
我们将队列随机分为训练组、验证组和(坚持)测试组,各占60%(667次扫描)、20%(222次扫描)和20%(222次扫描)的比例。为了防止数据泄漏,我们将训练、验证和测试集按患者而不是按切片进行分离。
3.2 手动注释的数据集
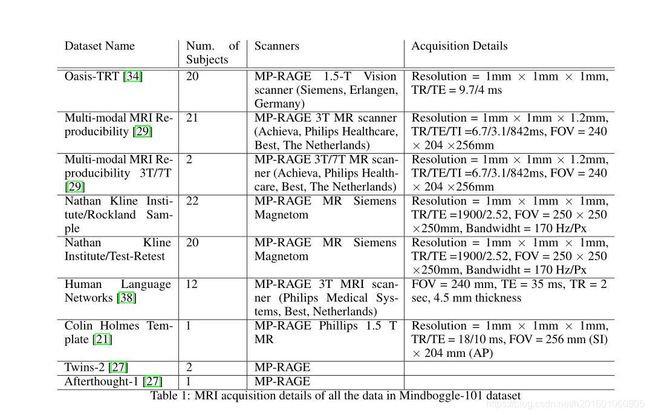
We used Mindboggle-101 [27] manually annotated data to fine-tune and further evaluate our model. The dataset includes manual annotations for all the segments that are present in the Freesurfer aseg+aparc list (except those listed in the previous section). The Mindboggle-101 dataset contains MRI scans of normal individuals from a diverse number and type of MRI scanners ranging in magnetic field strength from 1.5 Tesla to 7 Tesla. Mindboggle-101 contains 101 MRI scans from 101 subjects from multiple open-source studies. The details of the MRI acquisition for each dataset can be found in table 1. These data were also randomly split into training, validation and (held out) test set with the same 60%(60 scans), 20%(21 scans) and 20%(20 scans) ratio, again separated according to patients rather slices to prevent data leakage. The subjects’ ages range from 20 to 61 years.
我们使用mindbogle-101[27]手动注释数据来微调和进一步评估我们的模型。数据集包括Freesurfer aseg+aparc列表中所有段的手动注释(上一节中列出的除外)。Mindboggle-101数据集包含来自不同数量和类型的磁共振扫描仪的正常人的磁共振扫描,磁场强度从1.5特斯拉到7特斯拉不等。mindbogle-101包含101个来自多个开源研究对象的101个MRI扫描。各数据集的MRI采集详情见表1。这些数据也被随机分成训练、验证和(坚持)测试集,其比例分别为60%(60次扫描)、20%(21次扫描)和20%(20次扫描),再次根据患者而不是切片进行分离,以防止数据泄漏。受试者的年龄从20岁到61岁不等。
3.3纽约大学人工矫正数据集
We also use a small internal NYU dataset consisting of 11 patients to train and assess the generalizability of the segmentation model. The description of the NYU dataset is as follows: MPRAGE (FOV=256 × 256 mm2; resolution=1 × 1 × 1 mm3; matrix=256 × 256; sections, 192; TR=2100 ms;TE=3.19 ms; TI=900 ms; bandwidth=260 Hz/pixel). Imaging was performed on 3T Siemens Skyra and Prisma MRI scanner. Each MRI scan in this dataset was first processed using the standard Freesurfer tool and then underwent manual corrections by an expert neuroimager for ground truth segmentation. Here also, we split the data into the train (6 scans), validation (2 scans) and held-out test (3 scans) sets.
我们还使用一个由11名患者组成的纽约大学内部小数据集来训练和评估分割模型的泛化性。纽约大学数据集的描述如下:MPRAGE(FOV=256×256平方毫米;分辨率=1×1×1平方毫米;矩阵=256×256;截面,192;TR=2100毫秒;TE=3.19毫秒;TI=900毫秒;带宽=260赫兹/像素)。在3T西门子Skyra和Prisma磁共振扫描仪上进行成像。该数据集中的每一次核磁共振扫描首先使用标准的Freesurfer工具进行处理,然后由专家神经成像仪进行人工校正,以进行地面真相分割。在这里,我们还将数据分为训练(6次扫描)、验证(2次扫描)和保持测试(3次扫描)集。

3.4数据增强
Differences across MRI scanners and acquisition parameters result in differences in image characteristics such as signal-to-noise, contrast, the sharpness of the acquired volume. In addition, there are between-subject differences arising from subject positioning, etc. To improve the generalizability of our models to a broad array of scanner parameters, one or more of the following augmentation methods was applied to the training data at a random 50% of the training batches: First, gaussian blurring (sigma parameter uniformly drawn from [0.65 to 1.0]) and gamma adjustment (gamma parameter uniformly drawn from [1.6 to 2.4]). Second, input MRI and corresponding target labels were rotated by angle theta where theta is a random number uniformly drawn from [-10 to +10] degrees. Third, input and the corresponding labels were shifted up and sideways by dx and dy pixels, where dx and dy were randomly and uniformly drawn between +25 and -25. The input was then normalized between 0 and 1 using min-max normalization. Data augmentation was used only during training.
不同的核磁共振扫描仪和采集参数导致图像特征的差异,如信噪比、对比度、采集体积的锐度。此外,由于受试者的位置等原因,受试者之间存在差异。为了提高我们的模型对一系列扫描仪参数的通用性,在随机50%的训练批次中,对训练数据应用了以下一种或多种增强方法:,高斯模糊(sigma参数从[0.65到1.0]均匀绘制)和gamma调整(gamma参数从[1.6到2.4]均匀绘制)。第二,输入的磁共振图像和相应的目标标签被旋转角度θ,θ是从[-10到+10]度均匀抽取的随机数。第三,输入和相应的标签被dx和dy像素上下移动,其中dx和dy在+25和-25之间随机均匀地绘制。然后使用最小-最大规格化在0和1之间对输入进行规格化。数据增强仅在训练期间使用。
3.5深度学习模型
The model architecture used for performing the segmentation task is an encoder-decoder style fully convolutional neural network. The architecture is partly inspired by U-Net architecture [44] and partly by [24] and [45]. We term the new architecture as DenseUNet. The DenseUNet has a U-Net like architecture where it has four dense blocks in the encoding path and four dense blocks in the decoding path. The encoding pathway is connected to the decoding pathway using another dense block called the connecting dense block. Each of the encoding dense blocks is connected to the corresponding decoding dense block using skip connections. These skip connections facilitate the gradient flow in the network as well as the transfer of spatial information required for decoding the encoded input. The output from the last decoding dense block is passed through a classification block where the network performs the classification and gives the final output in the form of a separate probability map for each brain structure. The schematic diagram of the entire architecture can be seen in figure 1.
用于执行分割任务的模型结构是一种编码器-解码器式的完全卷积神经网络。该架构的部分灵感来自U-Net架构[44],部分灵感来自[24]和[45]。我们把这座新建筑称为登塞内特。dense U Net具有类似于U-Net的架构,其中在编码路径中有四个密集块,在解码路径中有四个密集块。编码路径使用另一个称为连接密集块的密集块连接到解码路径。每个编码密集块使用跳接连接连接到相应的解码密集块。这些跳跃连接有助于网络中的梯度流以及解码编码输入所需的空间信息的传输。最后解码密集块的输出通过一个分类块,在该分类块中,网络执行分类,并以每个大脑结构的单独概率图的形式给出最终输出。整个体系结构的示意图如图1所示。
We also implemented a vanilla U-Net architecture as described in the original paper [44] which serves as a baseline model. The schematic diagram for the same can be seen in figure 7.
The architectural choice of DenseUNet was also motivated by our empirical results on U-Net. A Dense block has more model capacity compared to standard convolutional block [22]. When larger training data is available, DenseUNet has larger learning and generalization capabilities.
All the parameters of the U-net and DenseUNet were initialized using Xavier initialization [20].
The components of DenseUNet i.e. the encoding dense block, the connecting dense block, the decoding dense block, and the classification block are explained below.
我们还实现了原始论文[44]中描述的普通U-Net架构,该架构用作基线模型。其原理图如图7所示。
我们在U-Net上的实证结果也推动了DenseUNet的架构选择。与标准卷积块相比,密集块具有更多的模型容量[22]。当有更大的训练数据时,DenseUNet具有更大的学习和泛化能力。
U-net和DenseUNet的所有参数都是使用Xavier初始化初始化的[20]。
下面说明DenseUNet的组件,即编码密集块、连接密集块、解码密集块和分类块。
3.5.1 编码密集块
The encoding dense block has four convolution layers. The output of all the previous convolution layers is added to the subsequent convolution layers. These additive connections are termed dense connections, that facilitate the gradient flow and allow the network to learn a better representation of the image [22]. The other common connection type is a concatenated connection. QuickNA T [45] uses concatenate connections to build dense blocks. Though concatenated connections can model additive connections, the model complexity in terms of the number of parameters and number of mathematical operations increases significantly leading to out-of-memory issues while training the model for a large number of segments. Therefore, to avoid out-of-memory issues and to achieve low training and inference times, we choose to use additive dense connections as opposed to concatenating dense connections. The output obtained by adding all the previous convolution layers’ output is followed by batch normalization and Rectifier Linear Unit (ReLU) non-linearity. Each convolution layer has 256 output channels with the filter size being 3 × 3 for all the channels. The output of the encoding dense block is followed by a max-pooling layer with a kernel size of 2 × 2 and a stride of 2. The down-sampled output is fed to the next encoding or connecting dense block.
编码密集块有四个卷积层。所有先前卷积层的输出被添加到随后的卷积层。这些加性连接被称为密集连接,这有助于梯度流,并允许网络学习图像的更好表示[22]。另一种常见的连接类型是串联连接。QuickNA T[45]使用串联连接来构建密集块。虽然串联连接可以对加法连接建模,但在为大量段训练模型时,参数数量和数学运算数量方面的模型复杂性显著增加,导致内存不足问题。因此,为了避免内存不足的问题,并实现较低的训练和推理时间,我们选择使用加法密集连接,而不是串联密集连接。将之前所有卷积层的输出相加得到的输出,然后是批量归一化和整流线性单元(ReLU)非线性。每个卷积层有256个输出通道,所有通道的滤波器尺寸为3×3。编码密集块的输出之后是一个最大池层,其内核大小为2×2,步长为2。下采样输出被送入下一个编码或连接密集块。
3.5.2 连接密集块
he connecting dense block is similar to the encoding dense block and has four convolution layers with dense connections. The only difference is the output of the dense block is not followed by a downsampling layer like a max-pooling layer.
连接密集块类似于编码密集块,具有四个紧密连接的卷积层。唯一的区别是密集块的输出后面没有像max pooling层那样的下采样层。
3.5.3 解码密集块
The decoding dense block is preceded by an upsampling block. The output from the previous decoding or connecting dense block is upsampled using transposed convolution with a filter size of 4 × 4 and stride of 2 and padding of 1. The upsampled output is concatenated with the output from the corresponding encoding dense block. The concatenated output serves as an input to a convolution layer which is followed by batch normalization and ReLU activation. The convolution layer has 256 output channels with a filter size of 3 × 3.
解码密集块之前是一个上采样块。先前解码或连接密集块的输出使用滤波器尺寸为4×4、跨距为2、填充为1的转置卷积进行上采样。上采样输出与对应的编码密集块的输出相连。级联输出用作卷积层的输入,卷积层随后是批处理规范化和ReLU激活。卷积层有256个输出通道,滤波器尺寸为3×3。
3.5.4 分类块
The classification block is a single convolution layer with the number of output channels equal to the number of brain structures to segment (in our case 1121) with a filter size of 1 × 1. The output of the convolution layer is passed through a softmax layer to obtain the probability maps for each of the brain structures we are trying to segment.
分类块是一个单独的卷积层,其输出通道的数目等于要分割的大脑结构的数目(在我们的例子1121中),滤波器的大小为1×1。卷积层的输出通过一个softmax层来获得我们试图分割的每个大脑结构的概率图。
3.6 损失函数
We model the segmentation task as a multi-class classification problem. Here, since we have 112 tissues of interest, this is a 113-class classification problem, where the last class is “background”.
Since the dataset is an imbalanced one, we use a weighted cross-entropy loss and weighted dice loss for our task. The weighted cross entropy loss is defined as:
我们将分割任务建模为一个多类分类问题。在这里,由于我们有112个感兴趣的组织,这是一个113类分类问题,其中最后一个类是“background”。
由于数据集是一个不平衡的数据集,我们使用加权交叉熵损失和加权骰子损失来完成我们的任务。加权交叉熵损失定义为:
W e i g h t e d − C E L = − 1 N ∑ i = 1 N ∑ j = 1 S ω j ( y i j log ( p i j ) ) Weighted{\rm{ - }}CEL = - \frac{1}{N}\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^S {{\omega _j}\left( {{y_{ij}}\log \left( {{p_{ij}}} \right)} \right)} } Weighted−CEL=−N1i=1∑Nj=1∑Sωj(yijlog(pij))
Where wj= Weight of the jth segment and S is the total number of segmentation classes. Here, wj=median freq freq(j) , where, freq(j) is the number of pixels of class j divided by the total number of pixels of images where j is present, and median freq is the median of these frequencies [16]. N = number of pixels in a 2D MRI image (a slice of the MRI volume), pij= probability of pixel i to be belonging to segment j, yij= label of pixel i to be belonging to segment j = 1 or 0.)
其中wj=第j个分段的权重,S是分段类的总数。这里, ω j = m e d i a n f r e q f r e q ( j ) {\omega _j} = \frac{{medianfreq}}{{freq\left( j \right)}} ωj=freq(j)medianfreq,其中,freq(j)是类j的像素数除以存在j的图像的像素总数,中值频率是这些频率的中值[16]。N=2D MRI图像中的像素数(MRI体积的一个切片),pij=像素i属于j段的概率,yij=像素i属于j段的标签=1或0。)
Weighted Dice Loss: The weighted dice score is defined as:
Weights are calculated using the same approach as mentioned for weighted-CEL.
W e i g h t e d − D i c e L o s s = 1 − 2 ∑ j = 1 S ω j ∑ i = 1 N y i j p i j ∑ j = 1 S ω j ∑ i = 1 N y i j + p i j Weighted{\rm{ - }}DiceLoss = 1 - 2\frac{{\sum\nolimits_{j = 1}^S {{\omega _j}} \sum\nolimits_{i = 1}^N {{y_{ij}}{p_{ij}}} }}{{\sum\nolimits_{j = 1}^S {{\omega _j}} \sum\nolimits_{i = 1}^N {{y_{ij}} + {p_{ij}}} }} Weighted−DiceLoss=1−2∑j=1Sωj∑i=1Nyij+pij∑j=1Sωj∑i=1Nyijpij
We experiment with local(using only a specific batch) and global (using the entire train set) estimation of wj. In the local case, wjs were adapted for each batch, and hence the loss function for each batch was slightly different. However, we found that a global wjgave us the best out of sample performance.
We combine the above two losses in a novel way that we term as loss switching. Loss switching is explained in the next
section.
我们对wj的局部(仅使用特定批次)和全局(使用整个训练集)估计进行了实验。在本地情况下,wjs适用于每个批次,因此每个批次的损失函数略有不同。然而,我们发现,一个全局性的wjg为我们提供了最好的样本外性能。
我们以一种新的方式将上述两种损耗结合起来,我们称之为损耗开关。下一节将解释损耗切换。
3.7 Loss switching
In segmentation tasks, the dice score is often reported as the performance metric. A loss function that directly correlates with the dice score is the weighted dice loss [47]. Based on our empirical observation, the network trained with only weighted dice loss was unable to escape local optimum and did not converge. Also, empirically it was seen that the stability of the model, in terms of convergence, decreased as the number of classes and class imbalance increased. We found that weighted cross-entropy loss, on the other hand, did not get stuck in any local optima and learned reasonably good segmentations. As the model’s performance with regard to dice score flattened out, we switched from weighted cross entropy to weighted dice loss, after which the model’s performance further increased by 3-4 % in terms of average dice score. This loss switching mechanism, therefore, is found to be useful to further improve the performance of the model.
在分割任务中,骰子得分通常作为性能指标报告。与骰子得分直接相关的损失函数是加权骰子损失[47]。根据我们的经验观察,仅用加权骰子损失训练的网络无法逃出局部最优,且不收敛。此外,从经验上看,模型在收敛性方面的稳定性随着类数和类不平衡的增加而降低。我们发现加权交叉熵损失,另一方面,没有陷入任何局部最优,并学习了相当好的分割。随着模型在骰子得分方面的性能趋于平稳,我们从加权交叉熵转换为加权骰子损失,之后模型的平均骰子得分进一步提高了3-4%。因此,这种损耗切换机制有助于进一步提高模型的性能。
3.8 评价指标
Dice score (DSC) is employed here as a primary measure of quality of the segmented images. This is a standard measure against which segmentations are judged and provide direct information on similarity against the ground truth labels.
这里使用骰子分数(DSC)作为分割图像质量的主要度量。这是一个标准的度量标准,根据它判断分段,并根据地面真实性标签提供关于相似性的直接信息.
D S C = 2 ∥ P T ∥ 2 2 ∥ P ∥ 2 2 + ∥ T ∥ 2 2 DSC = \frac{{2\left\| {PT} \right\|_2^2}}{{\left\| P \right\|_2^2 + \left\| T \right\|_2^2}} DSC=∥P∥22+∥T∥222∥PT∥22
where P = Predicted Binary Mask, T = True Binary Mask, PT = element-wise product of P and T, ||X||2is the L-2 norm. Dice score can equivalently be interpreted as the ratio of the cardinality of (T ∩ P) with the cardinality of ((T ∪ P) + (T ∩ P)).
其中P=预测的二元掩模,T=真二元掩模,PT=P和T的元素乘积,| | X | | 2是L-2范数。骰子得分可以等价地解释为(T∩P)的基数与(T∪P)+(T∩P)的基数之比。
From the above definition, it can be seen that DSC penalizes both over prediction and under prediction and, hence, is well-suited for segmentation tasks such as the one proposed here and is particularly useful in medical imaging.
从上述定义可以看出,DSC对过预测和欠预测都是不利的,因此,它非常适合于分割任务,例如本文提出的任务,并且在医学成像中特别有用。
3.9训练程序
What follows is a description of the training procedure we employed:
• For training each model, we used Adam Optimizer with reducing the learning rate by a factor of 2 after every 10-15 epochs.
• The model was initially trained on the training set of scans from the HCP dataset with the auxiliary labels until convergence. The trained model was then finetuned using the training set of the manually annotated dataset (Mindboggle-101) and the training set of the in-house NYU dataset.
• We trained the model with the HCP dataset using the loss switching procedure described in section 3.7 whereas, for finetuning, the loss function is simply the weighted dice loss as described in section 3.6.
• All the models are trained using early stopping based on the best dice score on the validation set.
以下是对我们所采用的训练程序的描述:
•对于训练每个模型,我们使用Adam优化器,在每10-15个阶段之后,学习率降低2倍。
•该模型最初是在使用辅助标签的HCP数据集的扫描训练集上进行训练,直到收敛。然后使用手动注释数据集(Mindboggle-101)的训练集和内部纽约大学数据集的训练集对训练模型进行微调。
•我们使用第3.7节中描述的损失切换程序对HCP数据集进行模型训练,而对于微调,损失函数只是第3.6节中描述的加权骰子损失。
•根据验证集上的最佳dice分数,使用提前停止对所有模型进行训练。
4、读者研究方法
4.1读者研究:描述与设置Description and Setup
We perform an expert reader evaluation to measure and compare the deep learning models’ performance with the Freesurfer model. We use HCP held-out test set scans for reader study. On these scans, Freesurfer results have undergone a manual quality control[33]. We also compare the non-finetuned and fine-tuned model with the Freesurfer model with manual QC. Seven regions of interest (ROIs) were selected: L/R Putamen (axial view), L/R Pallidum (axial view), L/R Caudate (axial view), L/R Thalamus (axial view), L/R Lateral V entricles (axial view), L/R Insula (axial view) and L/R Cingulate Gyrus (sagittal view). The basal ganglia and thalamus were selected due to their highly interconnected nature with the remainder of the brain, their involvement in many neurological pathologies, and their ease of distinction from surrounding structures. The insular and cingulate gyri were selected to assess the quality of cortical segmentation in structures best visualized in different planes and also due to the relatively frequent involvement of the insular gyrus in the middle cerebral artery infarctions. The lateral ventricles were selected to assess for quality of segmentation of cerebrospinal fluid structures, which would help identify pathologies affecting cerebrospinal fluid volumes, including intracranial hypotension, hydrocephalus, and cerebral atrophy.
我们使用专家读者评价来衡量和比较深度学习模型与自由曲线模型的表现。我们使用HCP进行测试集扫描来进行读者研究。在这些扫描中,Freesurfer的结果经过了手动质量控制[33]。我们还比较了非微调和微调模型与手动QC的Freesurfer模型。选择7个感兴趣区域(ROI):L/R壳核(轴视图)、L/R苍白球(轴视图)、L/R尾状核(轴视图)、L/R丘脑(轴视图)、L/R侧脑室(轴视图)、L/R岛(轴视图)和L/R扣带回(矢状视图)。基底神经节和丘脑之所以被选中,是因为它们与大脑的其余部分高度相连,它们参与许多神经病理学,并且容易与周围结构区分开来。选择岛状回和扣带回作为评价。
大脑皮层结构的分割最好在不同的平面上显示,这也是由于岛状回在大脑中动脉梗塞中的相对频繁的参与。选择侧脑室来评估脑脊液结构分割的质量,这将有助于确定影响脑脊液容量的病理学,包括颅内低血压、脑积水和脑萎缩。

Three expert readers performed visual inspection and assessment of the segmentation results. There were two attending neuroradiologists with 3 and 5 years of experience and one second-year radiology resident. Each reader was asked to rate 40 different predictions for each ROI (20 in each brain hemisphere) such as shown in figure 2. Readers were blinded to the algorithm used to predict the segmentation and examples were presented in a randomized order. Each prediction presented consisted of a single slice containing a minimum of 40 pixels within the ROI, ensuring that enough of the structure being assessed was present on the given image. A sample slice rated by the readers is shown in figure 2.
三位专家读者对分割结果进行了视觉检查和评估。有两位神经放射科主治医师,分别有3年和5年的经验和一位放射科住院医师。每个读者被要求对每个ROI(每个大脑半球20个)的40个不同预测进行评分,如图2所示。读者对用于预测分割的算法视而不见,并以随机顺序给出了示例。提出的每个预测都由一个在ROI中包含至少40个像素的单层组成,确保在给定的图像上存在足够的被评估的结构。图2显示了由读者评级的示例片段。
Each reader rated each example on a Likert-type scale from 1 to 5 with the following definitions:
- Rating of 1 (Poor): Segmentation has major error(s) in either the major boundary or labeling of areas outside the area of interest. Such segmentation would not yield acceptable quantitative measures.
- Rating of 2 (Fair): Segmentation has >2 areas of error along the major boundary or includes small but nontrivial areas outside the area of interest that would require manual correction before yielding reasonable quantitative measures to be used in research or clinical scenarios.
- Rating of 3 (Good): Segmentation has 1 or 2 area(s) of error along the major boundary that would require manual correction before yielding reasonable quantitative measures to be used in research or clinical scenarios. A good segmentation could have minor/few voxels separate from the volume of interest.
- Rating of 4 (V ery Good): Segmentation has minor, small areas of error along the major boundary that would still yield reasonable quantitative anatomic measures without manual corrections, appropriate for research orclinical use.
- Rating of 5 (Excellent): Segmentation is essentially ideal, has no (or only tiny inconsequential/questionable areas) where manual corrections might be used and would yield highly accurate quantitative anatomic measures, etc. Should have no erroneous areas outside the segment of interest.
1。等级1(差):分割在主要边界或感兴趣区域以外区域的标记中有重大错误。这种分割不会产生可接受的量化指标。
2。评分为2(公平):分割沿着主要边界有2个以上的错误区域,或包括感兴趣区域以外的小但非平凡区域,这些区域在产生用于研究或临床方案的合理量化措施之前需要手动纠正。
三。3级(良好):分割沿着主要边界有1或2个错误区域,在产生用于研究或临床场景的合理定量测量之前,需要手动校正。一个好的分割可以有少量的体素从感兴趣的体积中分离出来。
四。评分4(非常好):分割沿着主要边界有微小的误差区域,在没有人工校正的情况下,仍然可以产生合理的定量解剖学测量,适合研究或临床使用。8点5分。评分为
5(优秀):分割基本上是理想的,没有(或只有微小的无关紧要/有问题的区域)可能使用人工校正,并将产生高度准确的定量解剖测量等,不应在感兴趣的部分之外有错误的区域。
4.2 读者学习:分析
Using the ratings obtained from three readers the following analyses are performed:
使用从三个读者获得的评级进行以下分析:
1.Inter-Reader Reliability (IRR): An IRR analysis is performed using a two-way mixed, consistency, average measures ICC (Inter Class Correlation) [35] to assess the degree of agreement between readers. High ICC indicates that the measurement error introduced due to independent readers is low and hence, the subsequent analysis’ statistical power is not substantially reduced.
2. Comparison of different models: Based on the readers’ ratings, we investigate if there are statistically significant differences between the three methods using paired T-test and Wilcoxon signed-rank test at 95% significance level.
- 读者间可靠性(IRR):采用双向混合一致性平均测量ICC(类间相关性)[35]进行IRR分析,以评估读者之间的一致性程度。较高的ICC表明,由于独立读卡器引入的测量误差较低,因此,后续分析的统计能力没有实质性降低。
- 不同模型的比较:根据读者的评分,在95%显著性水平上,我们采用配对T检验和Wilcoxon符号秩和检验,研究三种方法是否存在统计学上的显著性差异。
后边的懒得翻译了。。。有空有人看我就继续翻译。。。