李宏毅DLHLP.17.BERT and its family.1/2.Introduction and Fine-tune
文章目录
- 介绍
- What is pre-train model
-
- 缘起
- Contextualized Word Embedding
- 趋势
-
- 参数
- Network Architecture
- How to fine-tune
-
- NLP tasks回顾
-
- 输入
- 输出
- How to fine-tune
-
- Adaptor
- Weighted Features
- Why Pre-train Models?
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
目前的预训练模型通常是吃大量的未标注文本,然后从中学习到文本或者文字的表征,输出结果经过finetune后可以用于不同的下游任务。
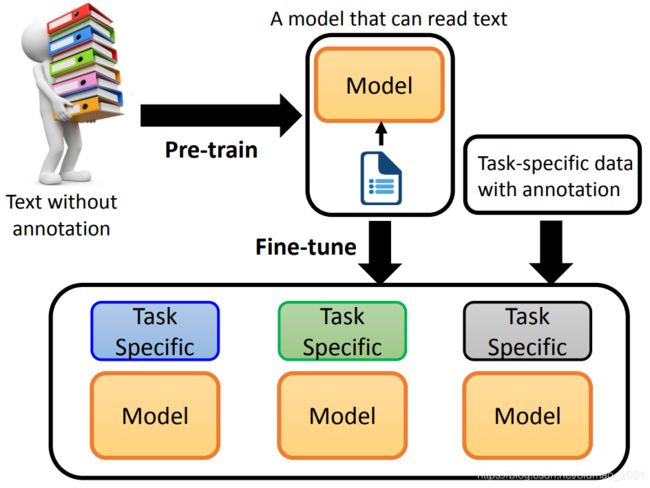
预训练最火的是BERT。
What is pre-train model
缘起
在BERT出现之前,也有预训练模型,这些模型通常是吃一个token吐一个embedding向量。
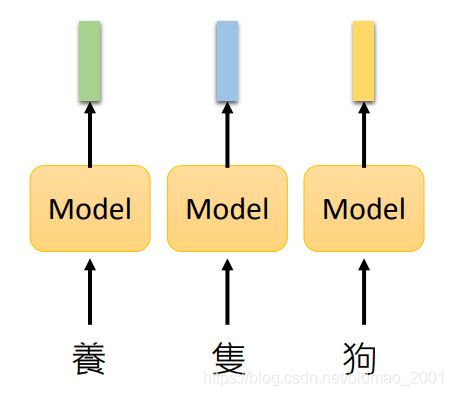
这里其实不用模型也可以,直接用一个表进行查找即可
这个方法有一个缺点:
The token with the same type has the same embedding.
相同token,那么其embedding也相同,这样难以处理多义字,难以根据上下文处理相同文字的不同信息。经典的方法有:Word2vec、GloVe
另外一个缺点:
English word as token.
一来英文单词数量很多,表会很大,而且会有新词出现,那么就会出现很多OOV。因此就提出用吃字母,输出词表征:
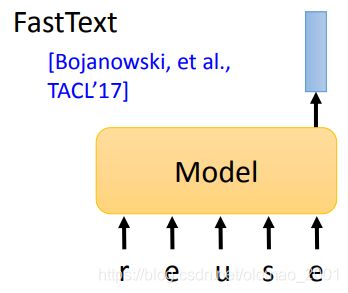
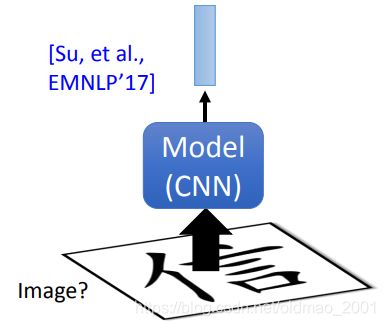
对于中文而言,有人将文字看成文字来处理,这样只能捕获部首偏旁信息,难以获得字意。
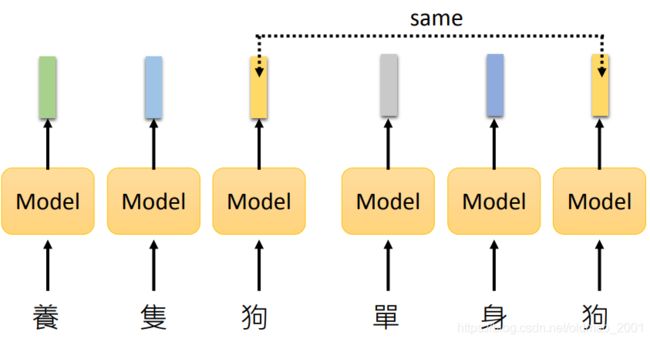
Contextualized Word Embedding
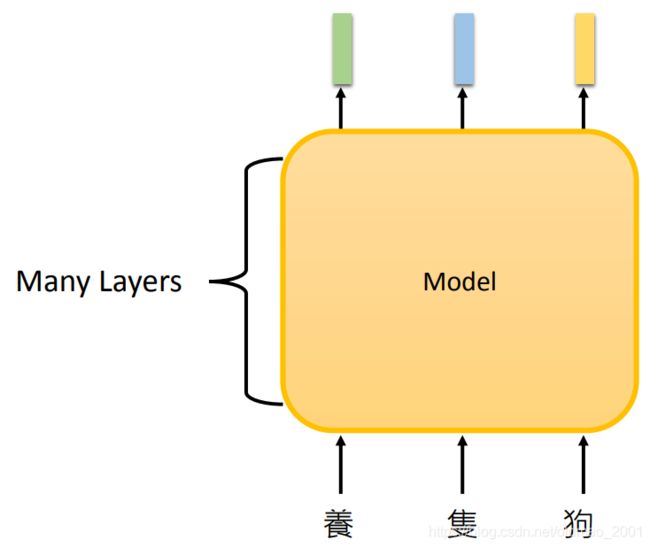
为了解决多义字的embedding问题,一定要结合上下文来理解,因此出现了Contextualized Word Embedding,如下图所示,吃一个句子吐token对应的embedding
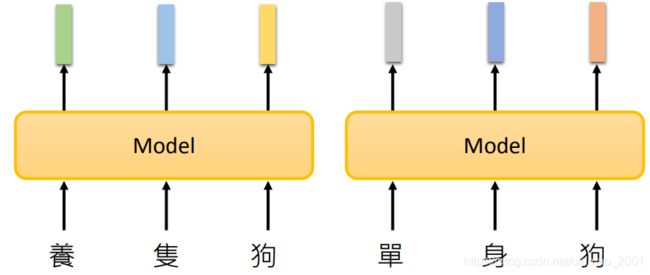
这里的模型通常用的DNN,常见的有:
• LSTM
• Self-attention layers(BERT)
• Tree-based model (较少用,处理逻辑性很强的句子结果比较好,例如数学表达式。)
这里是老师用BERT对十个句子中的【苹】字进行表征后进行相似度计算得到的矩阵可视化结果,前面五个句子中代表的是水果,后面五句代表的是apple公司。

趋势
参数
参数越来越多,模型越来越大和复杂,只有一些大公司才有硬件进行训练。当然也有一些研究将模型变小,减少参数:
Distill BERT [Sanh, et al., NeurIPS workshop’19]
Tiny BERT [Jian, et al., arXiv’19]
Mobile BERT [Sun, et al., ACL’20]
Q8BERT [Zafrir, et al., NeurIPS workshop 2019]
ALBERT [Lan, et al., ICLR’20](最有名)
以下的技术都是减少参数用到的:
Network Compression
• Network Pruning
• Knowledge Distillation
• Parameter Quantization
• Architecture Design
具体可以看综述:
http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
Network Architecture
一个方面是使得模型能够读取超长的sequence,原有的transformer只能读取512长度的sequence,那么修改后的模型可以读一篇文章,甚至一本书。
Transformer-XL: Segment-Level Recurrence with State Reuse[Dai, et al., ACL’19]
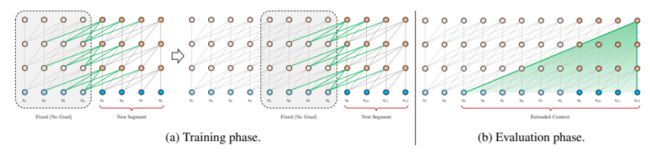
另外一个方向是改进模型,使得self-attention计算的时间复杂度减少Reduce the complexity of selfattention ,原算法的时间复杂度是 O ( n 2 ) O(n^2) O(n2),当sequence很长的时候,效率是很低的。典型的模型有:
• Reformer [Kitaev, et al., ICLR’20]
• Longformer [Beltagy, et al., arXiv’20]
How to fine-tune
在开篇就讲了,pre-train得到的结果要经过finetune才能用到特定的任务上,下面来看下finetune如何做。
先回顾上节提到过的NLP任务:
NLP tasks回顾
输入Input:
one sentence
multiple sentences
输出Output:
one class
class for each token
copy from input
general sequence
输入
如果输入是one sentence,那很简单,直接丢模型里面即可。
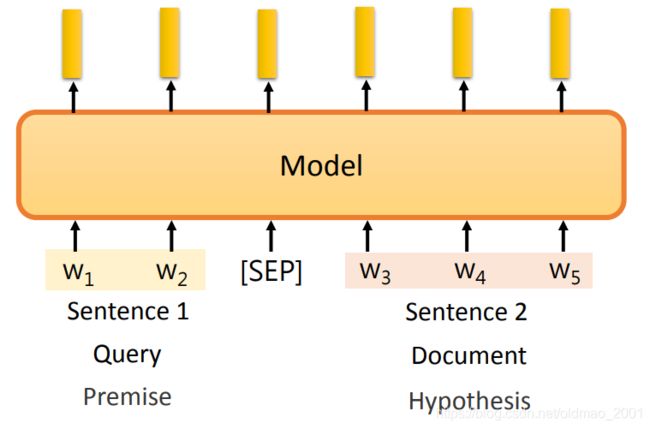
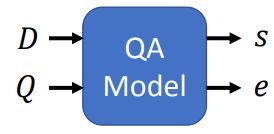
如果是多个句子(两个句子通常有下图所示的类别对组成,例如问题和文档),常用的方法就是将句子拼接起来,中间中分隔符号隔开。再丢模型里面。
输出
输出的第一种情况是one class。
通常情况下,模型的输出是一个token对应一个embedding,当要一个输入输出一个class的时候,BERT是加一个【CLS】的token,模型遇到这个特殊的token的时候,就会将句子(整个输入所有)的embedding都收集起来,丢入一个模型中(下图绿色部分),然后得到分类结果,这个模型可以很简单也可以很复杂,甚至可以是Linear的模型,反正能用来分类就好。
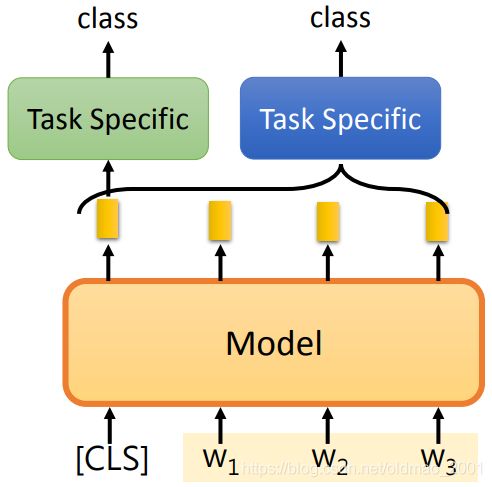
如果不用【CLS】token那么也行,那就是训练另外一个模型(上图中蓝色部分),这个模型吃整个句子的embedding,然后吐出一个class,这里图中的括号应该从 w 1 w_1 w1开始即可。
输出的第二种情况class for each token。
这个很简单,就是模型(下图绿色部分)吃每个token的embedding,然后吐出每个token的class。

输出的第三种情况ccopy from input。这种情况用得最多的就是Extraction-based QA任务。
这个任务中有两个输入:
Document: D = { d 1 , d 2 , ⋯ , d N } D=\{d_1,d_2,\cdots,d_N\} D={d1,d2,⋯,dN}
Query: Q = { q 1 , q 2 , ⋯ , q M } Q=\{q_1,q_2,\cdots,q_M\} Q={q1,q2,⋯,qM}
其中 d n d_n dn代表文档中的第n个词, q m q_m qm代表提问中的第m个词。
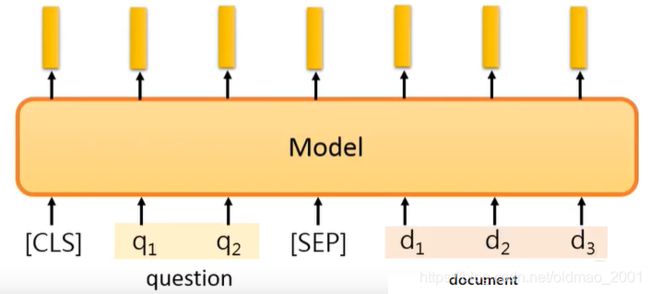
这两个输入经过模型得到答案的开始位置和结束位置两个东西(两个整数)。
答案表示为Answer: A = = { d s ⋯ , d e } A==\{d_s\cdots,d_e\} A=={ds⋯,de}
例如下面的第二个问题答案在原文的第77个词到第79个词,那么s=77,e=19.

下面看下用BERT如何解这个任务,首先模型要吃Query和Document,然后中间要分隔符分开,
然后我们知道答案的开始和结束的词的向量表示为:

当要求答案的开始位置的时候,我们可以用开始词的向量表示分别于document中的词逐个进行点乘,然后将结果丢入softmax,看谁的概率最大,那么这个词就是答案的开始词:

可以看到第二个词的概率最大,所以s=2. 同理可以求结束词:
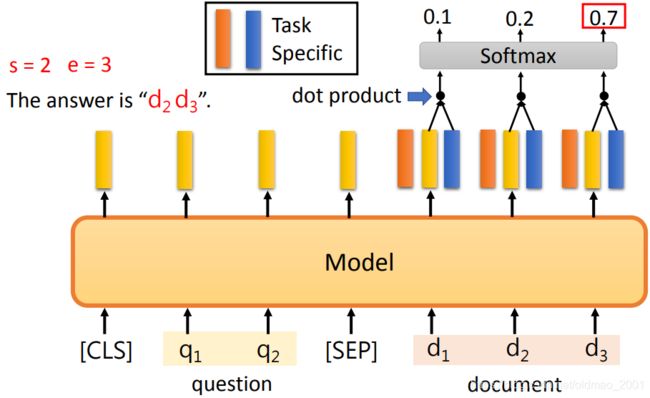
当然上面可以把点乘部分换成别的模型,例如LSTM(可以获取document全局信息),但BERT原文就是直接用的点乘结果也不错。
输出的第四种情况general sequence。
比较treeview的想法就是将预训练模型当做seq2seq中的encoder,将得到的特征作为decoder的输入经过attention后做下游任务。可以看到这样做的缺点是右边decoder没有经过预训练。没有经过预训练的模型不好做finetune,如果训练过的模型参数已经比较优化,只需要少量数据就可以训练得不错。
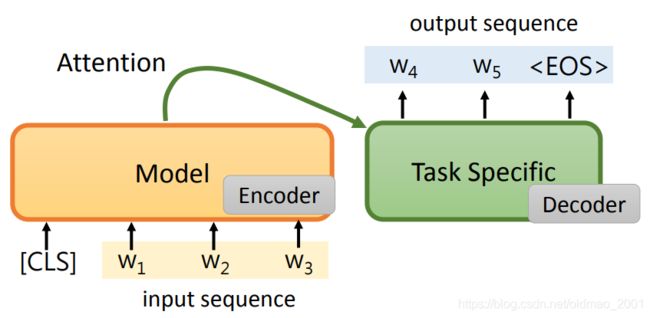
为了最大化的利用预训练模型,我们可以将模型改进为下图所示的结构:
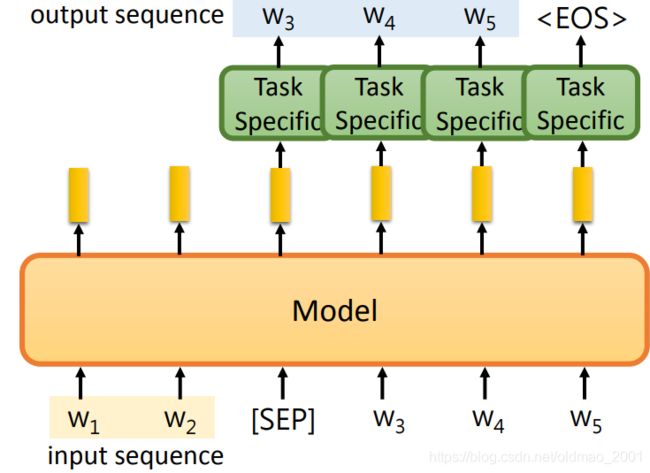
可以看到,预训练模型的作用并没有变化,还是吃一个token吐一个embedding,只不过当遇到【SEP】这个特殊的token后就开始输出output sequence,然后每个output sequence的embedding又作为预训练模型的输入,得到下一个output sequence的embedding,当然中间还要经过下游任务的模块。
How to fine-tune
第一种情况,我们将预训练模型当做特征提取模块,其参数不变,只需要微调任务所对应的模型参数:

另外一种情况是将任务模型与预训练模型接到一起,同时微调,这个方法比上面那种效果要好,不容易过拟合(预训练模型参数是经过优化的,任务模型的参数是随机初始化的)。
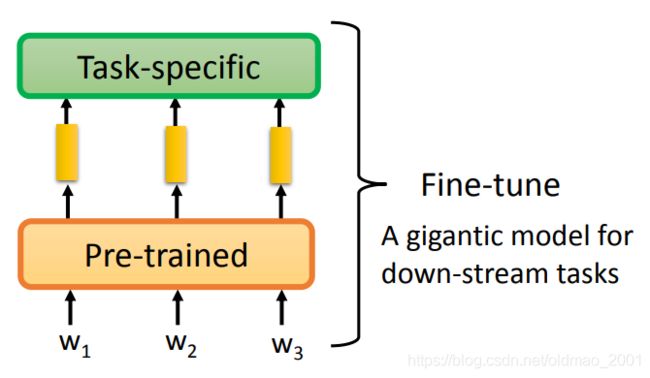
下面具体来看下第二种情况会遇到什么问题
Adaptor
假设我们有一个应用用到三个任务,三种颜色表示,刚开始预训练模型都一样,都是黄色的,三个任务都采用第二种方法整体fine-tune,那么预训练模型结果就变成三个不一样的模型,分别用三种颜色表示。
之前有说过,预训练模型的参数量是非常巨大的,那么三个预训练模型就是triple参数量,需要太多内存根本跑不起来。
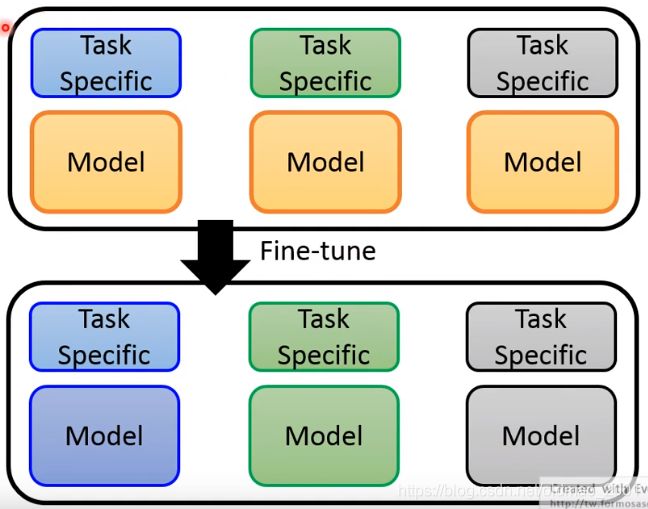
因此可以考虑只对预训练模型的某几层进行fine-tune,其他层参数不变。

在保存模型的时候,预训练模型中黄色部分都一样,可以只保存一份:
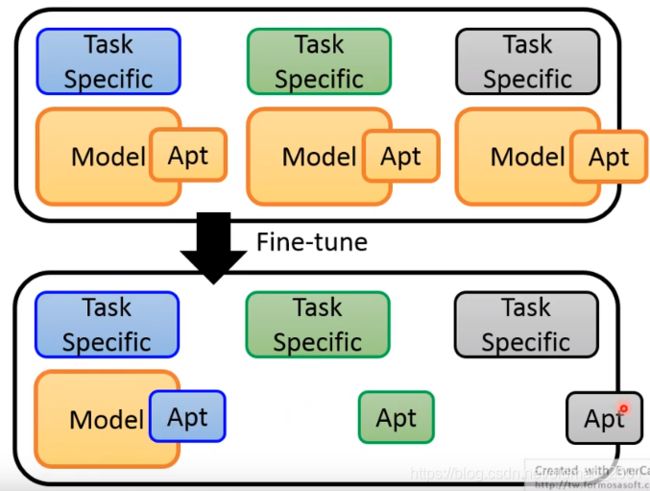
在文章Parameter-Efficient Transfer Learning for NLP中有个实例(该方法不唯一)
Transformer Layer如下图所示,可以看到在里面有放置adapter层,这个玩意在pre-train的时候是没有的,fine-tune的时候才放进来。
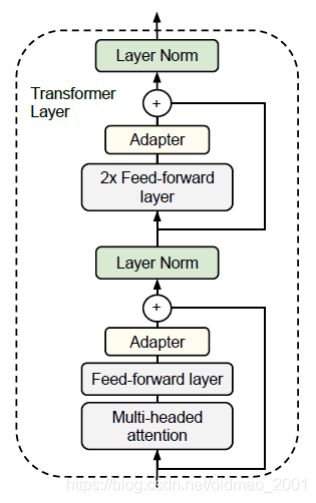
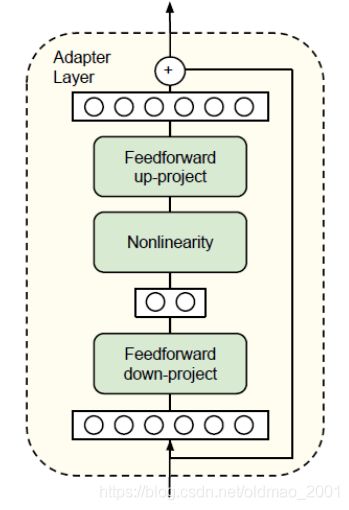
adapter层结构也很简单,尽量的减少所包含的参数,采用的中间是bottleneck的设计:
论文结果:
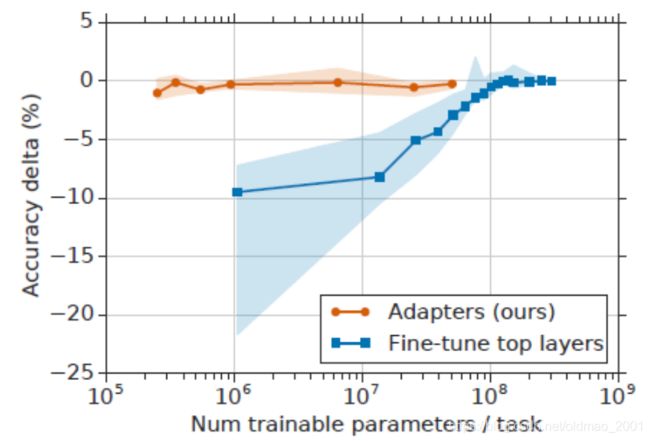
可以看到微调的参数(横轴)越多,效果越好,浅色的阴影代表不同任务取得的不同结果区间。
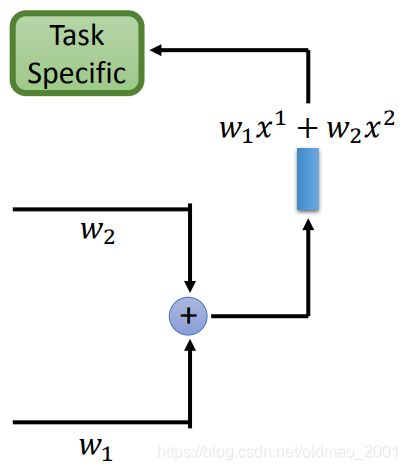
Weighted Features
之前的模型中都是吃token,然后经过很多层隐藏层后,然后最后一层得到token的embedding,然后用于downstream的任务。
但是由于每层隐藏层抽取的特征不一样,下面的做法是将每层的feature做weighted sum。
例如下图中第一层输出 x 1 x^1 x1,第二层输出 x 2 x^2 x2,然后把这两个输出分别乘上权重: w 1 , w 2 w_1,w_2 w1,w2再求和得到一个新的embedding,然后再进入下游任务。
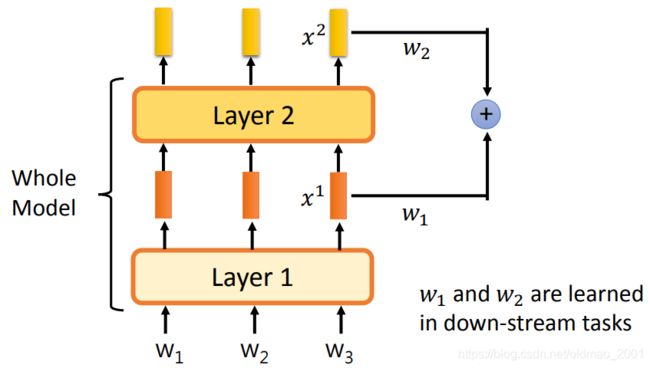
w 1 , w 2 w_1,w_2 w1,w2可以看做绿色模型的参数进行训练。
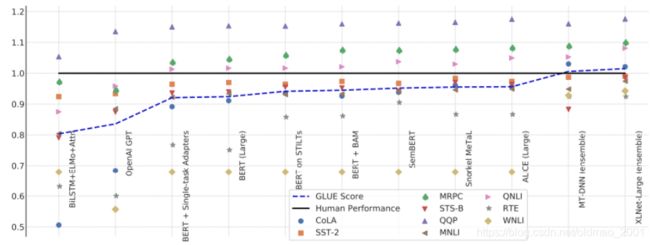
Why Pre-train Models?
• GLUE scores,下图中黑色横线代表人类的水平,每个一个列都是一个任务。
下图中用实线和虚线分别代表相同大小的同一个模型(相同颜色),然后虚线代表随机初始化,实线代表使用预训练模型初始化。可以看到,明显实线训练阶段收敛的速度要快!

关于如何将多维参数的loss可视化为下图的三维效果可以参考:https://youtu.be/XysGHdNOTbg
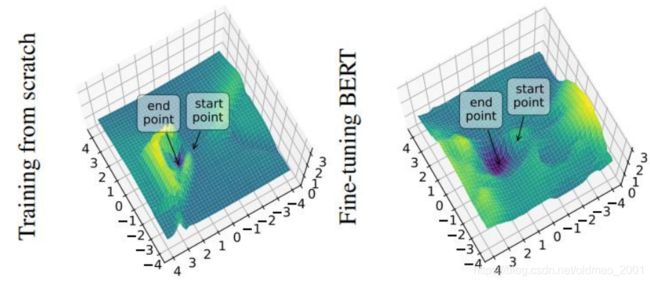
可以看到预训练模型得到Loss图像比较平滑,其泛化性能要好于左边陡峭的随机初始化的模型。