李宏毅机器学习(七)Bert and its family
技术前瞻

在预训练模型上训练Bert,并在我们的数据上fine-tune所需要的模型!
就像学习英文一样! 应该是通读英文文章后再去做题,而不是先做题再读懂文章!
Pre-train Model
Embedding
刚开始是 Word2Vertor,但是不能所有的单词都这样的! 太多了
要不,用字母和偏旁?
但是你这样下去,是有词义歧义的!
所以才有了Contextualized Word Embedding! 这里中间的Model可以选择是LSTM、Self-attention layers或者是Tree-based model(语法树)! 下面的链接是关于Tree-based model的!
BERT要不做大,要不做小! 大公司都是越来越大,但是穷人就是使得Bert越来越小!
其中最有名的是ALBERT,它神奇的地方在于基本都和BERT一样,不同的方法在于原来的BERT12层、24层都是不同的参数,但是ALBERT12层、24层都是一样的参数,但是效果比BERT还要好。
究竟怎么让模型变小呢? 这里有很多的方法可以自己去了解一下:

Network Architecture
如果我们处理更多的句子,而不是仅仅的sequence的tokens,而是segment-level的! 而是成段的,整个文章放入网络!

how to fine-tune
具体的NLP任务来进行fine-tune!
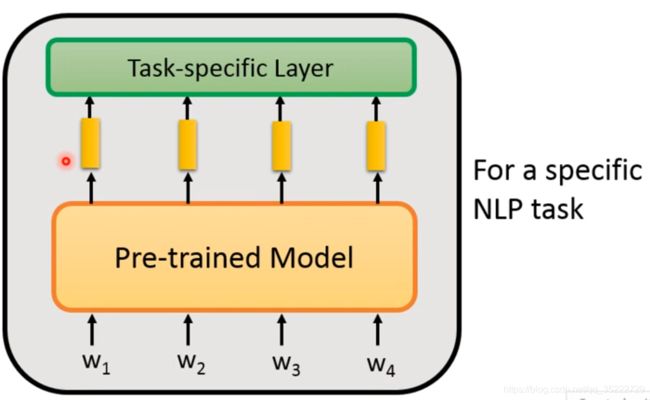
NLP的任务:

如果输入多个句子时:

输入两个句子,中间有【SEP】作为隔绝! 两个句子可以是查询和文件的差距,也可以是前提和假设的差异!
如果是输出时:

one class:
我们可以使用CLS,使得其输出一个类!
或者我们取几个向量的平均!

class for each token:
每个token输出一个类

copy from input:
文件D和答案query一起作为输入放到QA model里,最终输出两个整型变量s和e,分别是在文中的答案!

在BERT中如果操作的呢? 我们只需要两个vector(没有懂怎么获得的,可能是预定义的),其中一个vector用来和document中的输出vector做dot product来,根据相似度来定是不是是不是起点; 而另一个vector是作为结尾的!

General Sequence(v1):
Bert很适合Seq2Seq中的Encoder,然后经过Decoder来得到输出的句子! 但是问题在于,现在的Task Specific需要的labeled data不应该多,而且Decoder最好是预训练的! 但是现实是没有训练,那就会受到影响!

General Sequence(v2):
我们可以以预测下一个token的方法来训练seq2seq!

how to fine-tune:
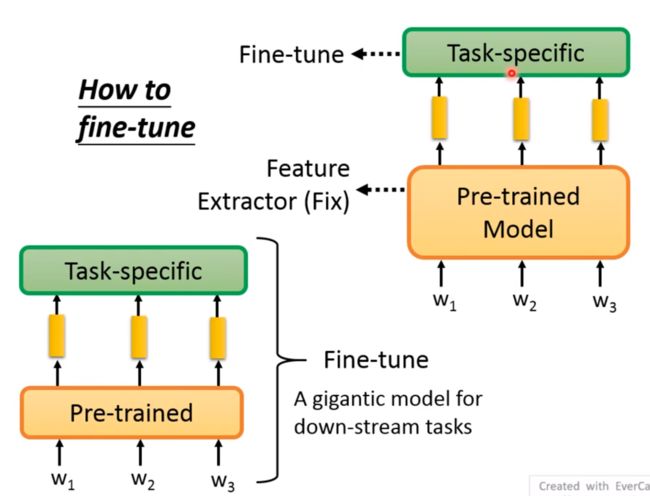
第一种是将Pre-trained model固定住,第二种是一块训练! 但是结果表明,往往一块训练效果会更好!
Adaptor:
如果一块训练的话,参数实在是太多了!
那么我们可不可以选择其中一部分层进行训练呢? 将这些层称为Adaptor层!其它地方固定!

Adaptor的方法很多,而且插入到哪里都是需要研究的! 我们以Transformer为例,我们在Feed-forward layer后加入Adaptor; 同时在训练之前我们不训练Adaptor,加入具体任务之后,我们才会训练Adaptor! 右边的是Adaptor层的具体,确保参数不会太多!

左侧0代表的是如果我们fine-tune整个model得到的结果,下图中蓝色的线表示的是训练倒数层,第一个点是倒数第一层,第二个点加入了倒数第二层,第三个点是加入了倒数第三层,以此类推! 而橙色的线就表示的是只训练其中的Adaptor!
Weighted Features:
其中 W 1 W_1 W1和 W 2 W_2 W2是可以被学出的! 比如我们用最终的特征放入具体的任务中,那么这个参数就是可以被学习的!其中 W 1 W_1 W1和 W 2 W_2 W2对应于不同层产出的特征! 不同层产出的特征是有不同的侧重点的,谁重要谁不重要是需要自己学的!

WHY Pre-train Models?:
为什么使用Pre-train Models? 因为这些Model真的带给了我们不错的效果!
Why FIne-tune?:
实现代表该模型Fine-tune过,虚线代表没有Fine-tune过! 可以看出所有的实线loss下降的都很快!

如何生成下面的图像? 可以看右上角的链接!
怎么看出这个模型是不是有泛化能力? end Point是峡谷的话泛化能力差,如果是盆地,那么泛化能力就很好!
