Hierarchical Graph Network for Multi-hop Question Answering 论文笔记
Hierarchical Graph Network for Multi-hop Question Answering 论文笔记
2020 EMNLP,Microsoft 365, 这篇文章所提出的层级图模型是在leaderboard上排名比较高的一个模型。
Overview
这篇文章同样是引入图表示学习来做多跳推理,但是本文在建图上做了改进和创新,提出Hierarchical Graph。作者认为之前基于图表示学习的方法有两个不足:一是图只被用来预测答案,没有充分地去寻找supporting fact;二是一些简单的Entity Graph无法完成复杂的multi-hop reasoning。基于以上两点问题,作者将建图方式做了改进,本文提出的层级图包含4类结点,7类边。
本文的contribution如下:
- 提出HGN,异质结点可以聚合到同一张层级图中
- 不同细粒度的结点为supporting fact的提取和答案地预测提供了更强的supervision
- 在HotpotQA上成为了SOTA
HGN
还是先来看模型架构图

从图中不难得出HGN主要有4个子模块:
- Graph Construction Module
- Context Encoding Module
- Graph Reasoning Module
- Multi-task Prediction Module
Graph Construction Module
本文的图可以视作是heterogeneous graph,结点分为四类:question、paragraph、sentence、entity,而连边的情况共有7种。
Paragraph Selection
对于段落的选取,首先进行title matching,即抽取出所有包含问题中某个phrase的段落,然后使用预训练的RoBERTa作为打分器,如果title matching返回了多个candidates,那就选取得分最高的两个;如果title matching没有返回任何结果,那么就选取所有包含问题中实体的段落,然后再进行打分取前2;如果还是没有找到,那就直接进行打分取前2。这一步段落选取是first-hop,至多得到两个段落。
接下来是second-hop的段落选取,这里作者提到entity linking的方式噪声比较多,因此他们采用的是通过first-hop段落的hyperlink来找second-hop段落(这里的hyperlink不清楚具体是什么,但是原文中提到是由Wikipedia提供的)。
Nodes and Edges
结点有四类:question、paragraph、sentence、entity,如上图中所示。作者说这样的异质结点能够使模型学习到不同细粒度的信息,从而更加准确地捕捉到supporting fact和answer。
连边总共有七种情况:
- question结点和所有的paragraph结点
- question结点和它所包含地entity结点
- paragraph结点和对应的sentence结点
- sentence结点和通过hyperlink相连的paragraph结点
- sentence结点和它所包含的entity结点
- paragraph结点和paragraph结点
- sentence结点和同一个段落里的sentence结点
Context Encoding Module
作者先是通过一个RoBERTa得到问题和所选段落的embedding Q ∈ R m × d Q\in{R^{m\times d}} Q∈Rm×d和 C ∈ R n × d C\in{R^{n\times d}} C∈Rn×d。接着,对于段落编码 C C C,再经过一层BiLSTM得到 M ∈ R n × 2 d M\in{R^{n \times 2d}} M∈Rn×2d。接下来,本文获取结点embedding的做法与DFGN比较类似,虽然没用采用mask,但是仍然是基于不管是entity、sentence还是paragraph,都可以表示为一个span的事实来计算embedding。
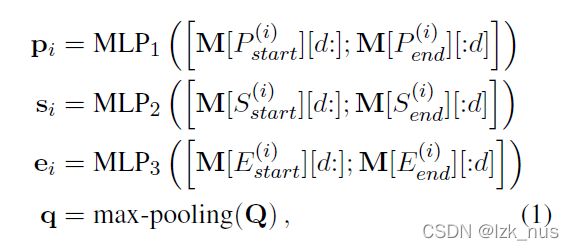
P、S、E分别表示Paragraph、Sentence、Entity,start和end就表示对应span的起始index和结束index。而对于问题结点的embedding则是通过max pooling获得。
Graph Reasoning Module
得到结点的embedding之后,就是在图上进行推理,应用图神经网络,本文也是选用了GAT模型。首先,整张图可以表示为 H ∈ R g × d H\in{R^{g\times d}} H∈Rg×d,其中 g = n p + n s + n e + 1 g\ =\ n_{p}+n_{s}+n_{e}+1 g = np+ns+ne+1,是paragraph结点数量、sentence结点数量、entity结点数量和question结点数量之和。
s i , j = L e a k y R e L u ( W T [ h i ; h j ] ) α i j = e x p ( s i , j ) ∑ k e x p ( s i , k ) h i ′ = R e L u ( ∑ j ∈ N i α i , j h j ) s_{i,j}\ =\ LeakyReLu(W^{T}[h_{i};h_{j}])\\ \alpha_{ij}\ =\ \frac{exp({s_{i,j}})}{\sum_{k}exp(s_{i,k})}\\ h^{'}_{i}\ =\ ReLu(\sum_{j \in N_{i}}\alpha_{i,j}h_{j}) si,j = LeakyReLu(WT[hi;hj])αij = ∑kexp(si,k)exp(si,j)hi′ = ReLu(j∈Ni∑αi,jhj)
经过GAT后我们就得到了更新后的 H ′ H^{'} H′。由于本文采取的也是通过context representation来进行answer prediction,因此接下来要对context representation进行更新,做法是Gated Attention。
C = R e L u ( W m M ) ⋅ R e L u ( W h H ′ ) H ˉ = s o f t m a x ( C ) ⋅ H ′ G = σ ( [ M ; H ˉ ] W s ) ⋅ t a n h ( [ M ; H ˉ ] W t ) C\ =\ ReLu(W_{m}M)\cdot ReLu(W_{h}H^{'})\\ \bar{H}\ =\ softmax(C) \cdot H^{'}\\ G\ =\ \sigma([M;\bar{H}]W_{s}) \cdot tanh([M;\bar{H}]W_{t}) C = ReLu(WmM)⋅ReLu(WhH′)Hˉ = softmax(C)⋅H′G = σ([M;Hˉ]Ws)⋅tanh([M;Hˉ]Wt)
Multi-task Prediction Module
本文设计了多任务学习,在原有的四个prediction基础上又加入了paragraph selection和entity prediction
o s e n t = M L P 4 ( S ′ ) o p a r a = M L P 5 ( P ′ ) o e n t = M L P 6 ( E ′ ) o s t a r t = M L P 7 ( G ) o e n d = M L P 8 ( G ) o t y p e = M L P 9 ( G [ 0 ] ) o_{sent}\ =\ MLP_{4}(S')\ \ \ \ \ \ o_{para}\ =\ MLP_{5}(P')\\ o_{ent}\ =\ MLP_{6}(E')\\ o_{start}\ =\ MLP_{7}(G)\ \ \ \ \ \ o_{end}\ =\ MLP_{8}(G)\\ o_{type}\ =\ MLP_{9}(G[0]) osent = MLP4(S′) opara = MLP5(P′)oent = MLP6(E′)ostart = MLP7(G) oend = MLP8(G)otype = MLP9(G[0])
而损失函数也是所有的和
L = L s t a r t + L e n d + λ 1 L p a r a + λ 2 L s e n t + λ 3 L e n t + λ 4 L t y p e L\ =\ L_{start}+L_{end}+\lambda_{1}L_{para}+\lambda_{2}L_{sent}+\lambda_{3}L_{ent}+\lambda_{4}L_{type} L = Lstart+Lend+λ1Lpara+λ2Lsent+λ3Lent+λ4Ltype
Experiment

这个模型在当时是成为了新SOTA。
作者对Hierarchical Graph的构建进行了消融实验
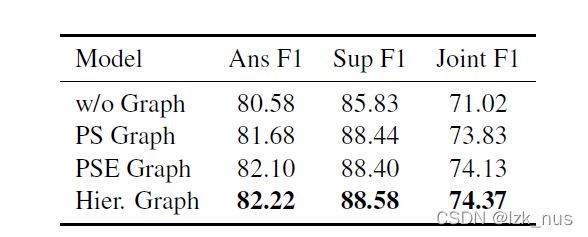
PS表示只有paragraph和sentence,PSE又加入了entity
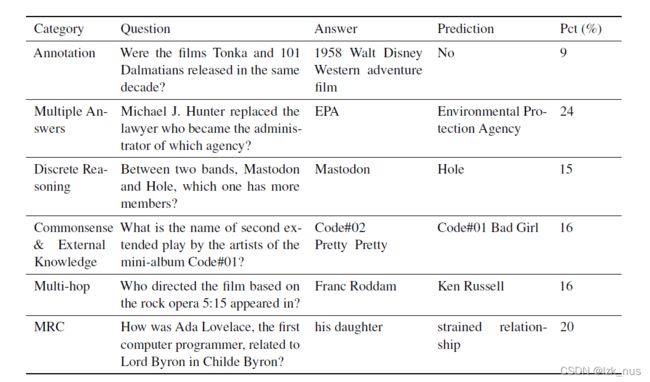
本文还进行了error分析,总结出了六类错误原因
Reflection
这篇文章的效果提升的确是非常显著的。我们把这篇文章与DFGN做一个比较会发现,两者模型结构上其实比较相似,最大的不同点就在于图的构建,而F1差出了12个点。我感觉本文改进的建图方式成功之处在于极大地丰富了图的信息,文中提到 n p = 4 n_{p}=4 np=4, n s = 40 n_{s}=40 ns=40, n e = 60 n_{e}=60 ne=60,可以看到这张图还是比较大的。其实 n p = 4 n_{p}=4 np=4说明图中包含了至少两个不相关的噪声段落,但从实际效果来看,这并没有什么影响,反而图的信息量变大后使得GAT进行信息传递变得更加有效。