编辑距离、拼写检查与度量空间:一个有趣的数据结构
本文除代码外,其余转自Matrix67大神的博客,原文链接地址:点击打开链接,声明:本文只作为个人知识备份之用
除了字符串匹配、查找回文串、查找重复子串等经典问题以外,日常生活中我们还会遇到其它一些怪异的字符串问题。比如,有时我们需要知道给定的两个字符串“有多像”,换句话说两个字符串的相似度是多少。1965年,俄国科学家Vladimir Levenshtein给字符串相似度做出了一个明确的定义叫做Levenshtein距离,我们通常叫它“编辑距离”。字符串A到B的编辑距离是指,只用插入、删除和替换三种操作,最少需要多少步可以把A变成B。例如,从FAME到GATE需要两步(两次替换),从GAME到ACM则需要三步(删除G和E再添加C)。Levenshtein给出了编辑距离的一般求法,就是大家都非常熟悉的经典动态规划问题。
下面给出本人的粗略的实现方法,望多指教:
#define MIN(a,b) ((a)>(b)?(b):(a))
#define MAX_LEN 100 //最长单词长度
static int m[MAX_LEN][MAX_LEN];
static int LevenshteinDist(const Letter& l1, const Letter& l2)
{
int i, j;
m[0][0] = 0;
if(l1[0] != l2[0]) m[0][0] = 1;
for(i = 1; i < l1.size(); i++)
{
m[i][0] = m[i-1][0]+1;
if(m[i-1][0] == i+1 && l1[i] == l2[0]) m[i][0]--;
}
for(j = 1; j < l2.size(); j++)
{
m[0][j] = m[0][j-1]+1;
if(m[0][j] == j+1 && l1[0] == l2[j]) m[0][j]--;
}
for(i = 1; i < l1.size(); i++)
{
for(j = 1; j < l2.size(); j++)
{
int m1, m2, m3;
m1 = m[i-1][j]+1;
m2 = m[i][j-1]+1;
m3 = m[i-1][j-1]+(l1[i]==l2[j]?0:1);
m[i][j] = MIN(m1,MIN(m2,m3));
}
}
return m[l1.size()-1][l2.size()-1];
}首先,我们观察Levenshtein距离的性质。令d(x,y)表示字符串x到y的Levenshtein距离,那么显然:
1. d(x,y) = 0 当且仅当 x=y (Levenshtein距离为0 <==> 字符串相等)
2. d(x,y) = d(y,x) (从x变到y的最少步数就是从y变到x的最少步数)
3. d(x,y) + d(y,z) >= d(x,z) (从x变到z所需的步数不会超过x先变成y再变成z的步数)
最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。给某个集合内的元素定义一个二元的“距离函数”,如果这个距离函数同时满足上面说的三个性质,我们就称它为“度量空间”。我们的三维空间就是一个典型的度量空间,它的距离函数就是点对的直线距离。度量空间还有很多,比如Manhattan距离,图论中的最短路,当然还有这里提到的Levenshtein距离。就好像并查集对所有等价关系都适用一样,BK树可以用于任何一个度量空间。
建树的过程有些类似于Trie。首先我们随便找一个单词作为根(比如GAME)。以后插入一个单词时首先计算单词与根的Levenshtein距离:如果这个距离值是该节点处头一次出现,建立一个新的儿子节点;否则沿着对应的边递归下去。例如,我们插入单词FAME,它与GAME的距离为1,于是新建一个儿子,连一条标号为1的边;下一次插入GAIN,算得它与GAME的距离为2,于是放在编号为2的边下。再下次我们插入GATE,它与GAME距离为1,于是沿着那条编号为1的边下去,递归地插入到FAME所在子树;GATE与FAME的距离为2,于是把GATE放在FAME节点下,边的编号为2。
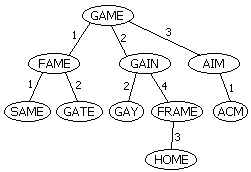
查询操作异常方便。如果我们需要返回与错误单词距离不超过n的单词,这个错误单词与树根所对应的单词距离为d,那么接下来我们只需要递归地考虑编号在d-n到d+n范围内的边所连接的子树。由于n通常很小,因此每次与某个节点进行比较时都可以排除很多子树。
举个例子,假如我们输入一个GAIE,程序发现它不在字典中。现在,我们想返回字典中所有与GAIE距离为1的单词。我们首先将GAIE与树根进行比较,得到的距离d=1。由于Levenshtein距离满足三角形不等式,因此现在所有离GAME距离超过2的单词全部可以排除了。比如,以AIM为根的子树到GAME的距离都是3,而GAME和GAIE之间的距离是1,那么AIM及其子树到GAIE的距离至少都是2。于是,现在程序只需要沿着标号范围在1-1到1+1里的边继续走下去。我们继续计算GAIE和FAME的距离,发现它为2,于是继续沿标号在1和3之间的边前进。遍历结束后回到GAME的第二个节点,发现GAIE和GAIN距离为1,输出GAIN并继续沿编号为1或2的边递归下去(那条编号为4的边连接的子树又被排除掉了)……
实践表明,一次查询所遍历的节点不会超过所有节点的5%到8%,两次查询则一般不会17-25%,效率远远超过暴力枚举。适当进行缓存,减小Levenshtein距离常数n可以使算法效率更高。
下面给出本人的实现代码,代码中有不足之处望多指教:
#define MAX_LEN 20
typedef std::string Letter;
struct BKNode;
typedef BKNode* pBKNode;
typedef BKNode* BKTree;
struct BKNode
{
Letter word;
pBKNode next[MAX_LEN+1];
BKNode(const Letter& w):word(w)
{
memset(next, NULL, sizeof(pBKNode)*(MAX_LEN+1));
}
} ;
void insert(BKTree& bktree, const Letter& new_word);
/**
*Query the BK-Tree to get all those letters whose LevenshteinDist is less than
*max_dist.
*@param letters used to store the letters that satisfy the query condition.
*@return return the node that has been traversed during this query.
*/
int query(BKTree bktree, const Letter& query, int max_dist, std::vector& letters);
void destroyBKTree(BKTree bktree);
void insert(BKTree& bktree, const Letter& new_word)
{
if(new_word.size()==0 || new_word.size()>MAX_LEN) return;
if(bktree == NULL){bktree = new BKNode(new_word); return;}
int dist = LevenshteinDist(bktree->word, new_word);
if(dist == 0) return;
if(bktree->next[dist] == NULL)
{
pBKNode new_node = new BKNode(new_word);
bktree->next[dist] = new_node;
return;
}
insert(bktree->next[dist], new_word);
}
int query(BKTree bktree, const Letter& query_word, int max_dist, vector& letters)
{
if(bktree == NULL) return 0;
int t_nodes_count = 1;
int begin = 1, end = 1;
int dist = LevenshteinDist(bktree->word, query_word);
if(dist <= max_dist)
{
letters.push_back(bktree->word);
}
begin = dist - max_dist;
end = dist + max_dist;
begin = (begin<1)?1:begin;
end = (end>MAX_LEN)?MAX_LEN:end;
for(int i = begin; i <= end; i++)
{
if(bktree->next[i] == NULL) continue;
t_nodes_count += query(bktree->next[i], query_word, max_dist, letters);
}
return t_nodes_count;
}
void destroyBKTree(BKTree bktree)
{
if(bktree == NULL) return;
for(int i = 0; i <= MAX_LEN; i++)
{
if(bktree->next[i] != NULL)
destroyBKTree(bktree->next[i]);
}
delete bktree;
}