机器翻译实战(英译汉)Transformer代码学习详解
任务目标
基于Transformer实现英语翻译汉语。如有疏忽请多指教
数据
Hi. 嗨。
Hi. 你好。
Run. 你用跑的。
Wait! 等等!
Hello! 你好。
I try. 让我来。
I won! 我赢了。
Oh no! 不会吧。
Cheers! 乾杯!
Got it? 你懂了吗?
He ran. 他跑了。
Hop in. 跳进来。
I lost. 我迷失了。
I quit. 我退出。
I'm OK. 我沒事。
Listen. 听着。
No way! 不可能!
No way! 没门!
Really? 你确定?
Try it. 试试吧。
We try. 我们来试试。
Why me? 为什么是我?
…… ……
代码&数据来源
Github:transformer-simple
哈弗NLP
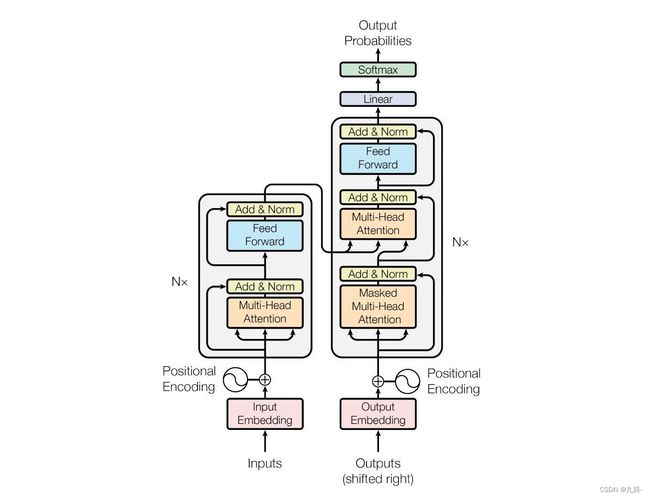
Transformer模型结构
Transformer的组成
1. Encoder
a. 若干个EncoderLayer(两个子层)
i. Feed Forward Neural Network
connected layer.子层间使用Add & Normalization 相连
ii. Self-Attention
2. Decoder
a. 若干个DecoderLayer(三个子层)
i. Feed Forward Neural Network
connected layer.子层间使用Add & Normalization 相连
ii. Encoder-Decoder-Attention,常规注意力机制
connected layer.子层间使用Add & Normalization 相连
iii. Self-Attention,自注意力机制
Batch and Masking
Mask策略一
一种就是普通的mask,就是自然语言处理中将某些字符(如标点符号,空格等)进行mask的操作
# 该部分与transformer实现有关
class Batch:
"""
Batches and Masking
"Object for holding a batch of data with mask during training." 在训练期间使用mask处理数据
"""
def __init__(self, src, trg=None, pad=0):
"""
构造函数
@param src: 源数据
@param trg: 目标数据
@param pad: 需要mask掉的字符,默认为0
一共有两种mask的方式:
一种就是普通的mask,就是自然语言处理中将某些字符(如标点符号,空格等)进行mask的操作
另一种就是对目标数据的mask,其原因是为了不让decoder在训练中看到后续的内容(即,我对于下一个字符的预测,只来源于前面的字符)
对于src的mask就是第一种mask,而对于tgt的mask是第一种加第二种
"""
# 将numpy.array转换为张量torch.tensor
src = torch.from_numpy(src).to(args.device).long()
trg = torch.from_numpy(trg).to(args.device).long()
self.src = src
# 此处pad=0,src向量均不为0(0表示UNK标识),src!=pad生成bool数组,且数组所有元素均为True
# 此处为第一种mask策略
self.src_mask = (src != pad).unsqueeze(-2) # unsqueeze()扩展维度,负数表示扩展的维度在倒数第n个位置
if trg is not None:
self.trg = trg[:, :-1] # 截掉trg中每个句子最后一个字符Mask策略二
另一种就是对目标数据的mask,其原因是为了不让decoder在训练中看到后续的内容(即,我对于下一个字符的预测,只来源于前面的字符)
def subsequent_mask(size):
"""
第二种mask策略
"Mask out subsequent positions."
@param size: 句子长度
@return:
"""
attn_shape = (1, size, size)
# np.triu函数生成一个对角线位置上移一位的上三角矩阵(k=1代表按对角线方向上移),矩阵大小为attn_shape
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0 # 返回布尔矩阵,subsequent_mask上三角矩阵中0的位置对应True
make_model
构造Transformer模型
def make_model(src_vocab, tgt_vocab, N = 6, d_model = 512, d_ff = 2048, h = 8, dropout = 0.1):
"""
定义了一个接收超参数并生成完整模型的函数。
@param src_vocab: 源数据字典长度
@param tgt_vocab: 目标数据字典长度
@param N: 层数layer
@param d_model: 表征后的维度
@param d_ff: FeedForward输出维度
@param h: attention机制,head多头个数
@param dropout:
@return:
"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model).to(args.device) # 多头注意力机制
ff = PositionwiseFeedForward(d_model, d_ff, dropout).to(args.device)
position = PositionalEncoding(d_model, dropout).to(args.device) # 位置信息嵌入
# model其实是Transformer的类
model = Transformer(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout).to(args.device), N).to(args.device),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout).to(args.device), N).to(args.device),
nn.Sequential(Embeddings(d_model, src_vocab).to(args.device), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab).to(args.device), c(position)),
Generator(d_model, tgt_vocab)).to(args.device)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p) # xavier初始化可以使得输入值x的方差和经过网络层后的输出值y的方差一致。
return model.to(args.device)
模型核心代码
Transformer(EncoderDecoder)模型结构
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(Transformer, self).__init__()
# 与实参的对应关系
self.encoder = encoder # Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout).to(args.device), N).to(args.device)
self.decoder = decoder # Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout).to(args.device), N).to(args.device)
self.src_embed = src_embed # nn.Sequential(Embeddings(d_model, src_vocab).to(args.device), c(position))
self.tgt_embed = tgt_embed # nn.Sequential(Embeddings(d_model, tgt_vocab).to(args.device), c(position))
self.generator = generator # Generator(d_model, tgt_vocab)).to(args.device)
def encode(self, src, src_mask):
"""
对src进行embedding,并嵌入位置信息
@param src: self.src_embed(src),调用self.src_embed对应类中的forward函数,对batch.src进行embedding操作
包含两个部分:一个是对输入的句子进行了embedding,第二个就是添加了位置信息
@param src_mask: batch中的masking后的源数据
@return: 调用nn.Embedding 对输入的src进行了向量化
"""
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
"""
对tgt进行embedding,并嵌入位置信息
@param memory: 下面forward()中的self.encode(src, src_mask)
@param src_mask:
@param tgt: tgt_embed的参数
@param tgt_mask:
@return:
"""
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
"""
调用decode函数和encode函数,其中encode的输出作为decode的输入
@param src: encode的参数
@param tgt:
@param src_mask: encode和decode的参数
@param tgt_mask:
@return:
"""
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
嵌入
Embedding
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model) # 开根号与make_model()中nn.init.xavier_uniform_()初始化有关
PositionalEncoding
class PositionalEncoding(nn.Module):
"""
嵌入位置信息
"""
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model, device=args.device) # pe是一个二维tensor,5000*512
position = torch.arange(0., max_len, device=args.device).unsqueeze(1) # 经过unsqueeze扩展成5000*1的二维tensor
# div_term,通过绝对位置编码来表达相对位置并保证远程衰减
# torch.arange(0., d_model, 2) 生成从0~512的偶数,共256个
div_term = torch.exp(torch.arange(0., d_model, 2, device=args.device) *- (math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # pe取所有行,从0开始到末尾步长为2的所有列,偶数,5000*512
pe[:, 1::2] = torch.cos(position * div_term) # pe取所有行,从1开始到末尾步长为2的所有列,奇数,5000*512
pe = pe.unsqueeze(0) # 加1个维度,1*5000*512
self.register_buffer('pe', pe) # register_buffer在内存中定义一个常量,同时,模型保存和加载的时候可以写入和读出
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
编码器
Encoder
"""
继承nn.Module,并重写构造函数forward函数
Q:何时调用forward函数?
A:实际上model(data)是等价于model.forward(data),因为Module中定义了__call__()函数,该函数调用了forward()函数
"""
class Encoder(nn.Module):
# layer = EncoderLayer
# N = 6
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N) # Encoder包含N个EncoderLayer(下方代码)
self.norm = LayerNorm(layer.size) # 对输入数据进行白化操作(即使输入数据符合独立同分布),layer.size=dmodel
def forward(self, x, mask):
# 连续encode 6次,且是循环的encode
for layer in self.layers:
x = layer(x, mask) # 将输入(和掩码)依次通过每一层
return self.norm(x) # 调用LayerNorm()归一化
EncoderLayer
class EncoderLayer(nn.Module):
"""
"Encoder is made up of self-attn and feed forward (defined below)"
"""
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
# self_attn和feed_forward是在make_model时传入,与实参的对应关系
self.self_attn = self_attn # 自注意力机制:MultiHeadedAttention类 (transformer图中橙色方块)
self.feed_forward = feed_forward # PositionwiseFeedForward类 (transformer图中蓝色方块)
# 因为encoder一共两层,每层需要一个SublayerConnection来对子层进行layernorm跟残差,所以这里clones函数是复制了两次
# 克隆两个SublayerConnection,分别给上面两个模块(self_attn和feed_forward),因为两个模型残差不一样
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size # d_model
"""
SublayerConnection的作用就是把self_attn和feed_forward连在一起,只不过每一层输出之后都要先norm再残差
"""
def forward(self, x, mask):
# 调用sublayerConnextion的forward()
# 此注意力机制要求Q=K=V
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 将输入x传入self_attn子层
# 注意到attn得到的结果x直接作为了下一层的输入
return self.sublayer[1](x, self.feed_forward) # 传入feed_forward子层
残差连接层&正则层
正则层
class LayerNorm(nn.Module):
"""
#自己定义的Layer归一化,这个代码号称是不调用额外的包的,所以这个自己实现
#对应的就是上面图中黄色方块中的norm操作
"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 缩放大小,features=dmodel
self.b_2 = nn.Parameter(torch.zeros(features)) # 位移大小
self.eps = eps # 分母的微小值,防止标准差(分母)为0
def forward(self, x):
# .mean(dim, keepdim=True),-1:若dim为负,则将被转化为dim+input.dim()+1,keepdim保持维度不变
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
残差层
class SublayerConnection(nn.Module):
"""
子层之间的连接层(Add&Normal)
子层:self-Attention & Feed Forward Network
残差连接residual connection后面是layerNorm
其中Add代表了Residual Connection
通过将一部分的前一层的信息无差的传递到下一层,可以有效的提升模型性能,防止梯度消失,加快收敛
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
前向逻辑
@param x: 上一层的输出
@param sublayer: 子层
@return:
"""
# 我们首先对输出进行规范化,然后将结果传给子层处理,之后再对子层进行dropout操作,
# 随机停止一些网络中神经元的作用,来防止过拟合. 最后还有一个add操作,
# 因为存在跳跃连接,所以是将输入x与dropout后的子层输出结果相加作为最终的子层连接输出.
return x + self.dropout(sublayer(self.norm(x))) # x为上一层的输出
注意力机制
多头注意力机制
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
# dmodel和h都是在make_model中定义的超参数,保证可以整除
assert d_model % h == 0 # assert断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况
self.d_k = d_model // h # 向下取整
self.h = h
# #这里克隆4个线性变换,前三个对QKV做特征变换,最后一个是输出的的特征变换,得到W_query,W_key,W_value,W_output
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
query,key,value均为输入x,详见EncoderLayer类的forward函数
@param query:
@param key:
@param value:
@param mask:
@return:
"""
if mask is not None:
mask = mask.unsqueeze(1)
nbatches = query.size(0) # 取第一个维度
# 1) Do all the linear projections in batch from d_model => h x d_k
for l, x in zip(self.linears, (query, key, value)):
lx = l(x)
print(lx.view(nbatches, -1, self.h, self.d_k).shape)
print(l(x).view(nbatches, -1, self.h, self.d_k).transpose(1,2).shape)
# l取出linears对应层,x依次取出query,key,value
# (self.linears[0], self.linears[1], self.linears[2])&(query, key, value)
# view()重构张量维度,-1的含义是根据元素总数total和nbatches个数,自动补齐矩阵[nbatches, total / nbatches]
# transpose(),交换维度1与维度2(1和2为索引位置) => torch.Size([64, 10, 8, 32]) => torch.Size([64, 8, 10, 32])
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))] # zip()将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
# contiguous()作用是返回一个在内存中连续的tensor,其data与原tensor一致
# transpose()后内存空间是非连续保存的,而view()要求tensor的内存空间是连续的,因此需要contiguous()将tensor的内存空间转换为连续的
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x) # 使用self.linears[-1]最后一个线性层,对输出x做线性变换
注意力分数计算
def attention(query, key, value, mask=None, dropout=None):
"""
Compute 'Scaled Dot Product Attention
@param query: (batch, #head头数, sequence length, feature dimension(d_k))
@param key: (batch, #head头数, sequence length, feature dimension(d_k))
@param value: K和Q的shape必须相同的,而V可以不同
@param mask: (batch, 1, sequence length, sequence length)
@param dropout:
@return: p_attn,将注意力分数转换为概率的矩阵,p_attn与value的乘积
"""
d_k = query.size(-1) # 取query最后一个维度
"""
torch.matmul() tensor乘法
高维矩阵遵循的原则是:在多维矩阵相乘中,需最后两维满足shape匹配原则,最后两维才是有数据的矩阵,前面的维度只是矩阵的排列而已!
这也是在MultiHeadedAttention这个函数中将数据输入attention函数时要进行transpose的原因
因为只有seq_length跟 embedding才是要进行注意力点乘的关键啊,其他俩维度只是排列而已啊
"""
# 计算注意力分数
# scores最后两维组成attention矩阵,attention[i][j]表示时刻 i attend to j 的得分(此时还没有经过softmax转换为概率)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # query和key最后两个维度进行矩阵乘法
if mask is not None: # 这里的mask是第一种mask策略:就是普通的mask,就是自然语言处理中将某些字符(如标点符号,空格等)进行mask的操作
scores = scores.masked_fill(mask == 0, -1e9) # 将其中的0值用几个较小值替代,使其经过softmax操作近似为0
p_attn = F.softmax(scores, dim=-1) # 经过softmax,将数值attn转换为概率p_attn后的维度不变
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
前馈层
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
# 两个全连接(fully connected layer)层
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 线性变换 ->relu激活->dropout防止过拟合-> 线性变换
return self.w_2(self.dropout(F.relu(self.w_1(x))))
解码器
Decoder
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
"""
@param x: 每个DecoderLayer的输出,即DecoderLayer层之间的信息流动
@param memory: 是Encoder的输出
@param src_mask: Encoder的mask用于padding
@param tgt_mask: Decoder的mask用于隐藏后面的单词的输出
@return:
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
DecoderLayer
class DecoderLayer(nn.Module):
"""
每个DecoderLayer包含三个子层
"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn # 自注意力机制:与EncoderLayer的attention一致,Transformer结构图Decoder下方的Attention
self.src_attn = src_attn # 常规注意力机制:建立起Encoder与Decoder之间的Attention,结构图Decoder中间的Attention
self.feed_forward = feed_forward # 结构图Decoder上方的feedForward
# 由于DecoderLayer包含3个子层,因此克隆3个
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
# 第一个attention(与Encoder的attention一致),传入tgt_mask
# tgt_mask采用第一种 && 第二种mask策略(即在解码时只能看到当前单词之前的单词而看不到之后的单词)
# 此注意力机制要求Q=K=V
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # tgt_mask采用了两种mask策略
# 输出与Encoder输出之间的attention计算
# 这个子层中常规的注意力机制,q是输入x; k,v是编码层输出memory
# 同样也传入source_mask,但是进行源数据遮掩的原因并非是抑制信息泄漏,而是遮蔽掉对结果没有意义的字符而产生的注意力值,
# 以此提升模型效果和训练速度. 这样就完成了第二个子层的处理.
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) # 第二个attention
# 最后一个子层就是前馈全连接子层,经过它的处理后就可以返回结果.这就是我们的解码器层结构.
return self.sublayer[2](x, self.feed_forward)
源码阅读过程中的参考资料
- Transformer代码记录整理
- 第二章:Transformer架构解析
- Transformer代码详解
- Transformer代码阅读
- pytorch yield
- unsqueeze和sequeeze
- np.triu()的用法
- nn.Sequential
- PositionalEmbedding
- python中copy()和deepcopy()详解
- make_model()中 nn.init.xavier_uniform_()初始化
- 深度学习中的Normalization
- 残差连接和归一化层
- zip函数
- nn.Module()什么时候调用forward()函数=>__call __()函数
- torch.matmul()用法介绍
- 多维tensor的相乘到底在乘什么
- pytorch broadcasting广播
- pytorch transpose与contiguous
- Linear、Dense、MLP、FC的区别
- 保姆级硬核图解Transformer