可观测性不止于监控,让运维不开盲盒!
近年来,可观测性热度节节攀升,企业在可观测性实践过程中常常也伴随着一系列棘手的问题:
- 监控与可观测区别是什么?
- 可观测发展史是怎样的?
- 如何规划可观测的体系化建设之路?
- 如何让可观测平台与工具顺利落地?
接下来我们就跟随嘉为科技AIOps产品负责人宋蕴真的脚步,步步深入,深度剖析可观测性,全面深度挖掘探索企业运维可观测体系的建设之路。
*注:以下内容整理自:嘉为科技AIOps产品负责人 宋蕴真 于 嘉为蓝鲸2022研运一体创新峰会的精彩分享——《运维可观测体系化建设之路》。
01. 正本清源——可观测与相关易混淆概念
1)监控VS可观测性
谈及可观测性,就不得不提一个经常会被混淆的概念,也就是监控。在我们以往的实践过程中,通常遇到最多的问题就是:企业现在已经建设了许多监控工具了,可观测的体系建设能够带来什么价值?
首先需要明确:监控是一种可观测的实现手段,而可观测性本身不止于监控。
对于运维来说,在发现问题时,传统监控通通仅能指向问题发生的对象,将告警发送给用户,此时依靠运维人员的历史处理经验来进行下一步动作。往往这种处理方式经由经验丰富的运维人员处理,能够得心应手,但是当运维人员缺乏处理经验时,我们仅仅只能够发现问题的表层,而无法得知问题的根源,造成运维在解决问题时,犹如开“盲盒”一般,毫无头绪的境况。
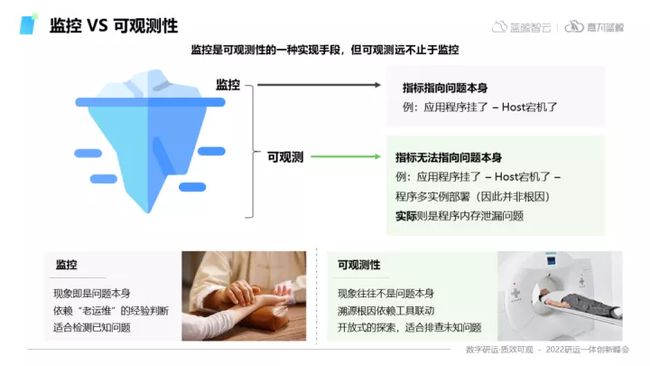
监控使用者更偏向于具备丰富经验的传统运维老手,举个例子来说,就如同老中医通过把脉能够大体判断病症,同样的,运维老手从仪表盘就大概能够判断出问题的程序或机器。但这种方式非常依赖于过往的经验,以及运维人员对这套系统的熟悉度。
而对于可观测来说,它更像是西医的概念,就好比去医院进行体检时,通过很多全面的检查,医生就能够比较精确的指向病因根源。可观测性让我们通过更加复合的手段,让不具有很多运维经验或者对系统并不熟悉的人也能够很好的完成运维工作。
2)可视化VS可观测性
第二个容易混淆的概念,往往出现在初步接触可观测领域,即可视化和可观测性的混淆。本身这两个概念都比较大,在此我们也仅仅只浅谈可观测里面的可视化。

在可观测中的可视化就是将观测数据进行展现的手段,而在更大的领域,有的企业会去做数字孪生,将各种对象以数字化方式进行投射或展示。
可观测更关注的点并不在可视化上,更多时候只是将可视化作为呈现数据的手段,除了呈现数据,可观测还包括数据的收集、存储、分析等,最终整合后组织成一个良好的产品形态,辅助运维人员进行排障。
02. 以史为镜——可观测发展进程
1)可观测性的发展
以史为镜,纵观可观测性的整个发展历程。企业在选用或采购产品时,通常也会去了解产品发展的来龙去脉,那么可观测的发展是怎样的呢?
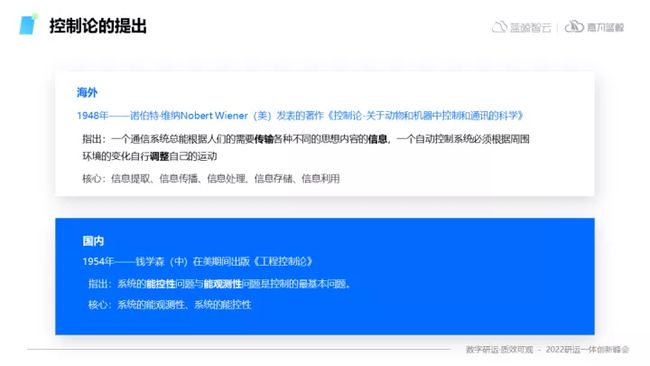
在早期,可观测并不是作为一个独立概念被提出,而是在海外经典理论——控制论中有所提及。在控制论的描述中,信息在系统中不断的进行传输,系统会随着信息不断的反馈而调整行为,最终形成整体反馈的闭环。
控制论在传入国内后,被我国著名科学家钱学森发扬光大,并且在工程学上进一步进行应用。其核心基本问题就是系统的能控性与能观测性,也就是通过系统中信息的不断反馈,来指导并优化整体工程。
为了方便理解,我们以人体领域来和研运领域进行对比,更形象的解释可观测的概念。
对于人来说,判断事物需要从眼睛看到,耳朵听到以及感官获取,这就是人体的观测系统。在观测到数据后,通过大脑进行判断,接着进行下一步行动思考,构成完整的观测闭环。
而对于运维,我们希望建立AI专家系统的概念,能够像人脑一样,通过可观测系统收集数据后进行判断,对于能够解决的问题给予自动化或手动的操控,对于需要求助的可以申请工单获得问题支持。

在这里,最大的价值点仍然在于信息的输入,如果能够尽早的获取系统中的数据,就能够尽早的思考和分析,从而采取行动。
2)IT与可观测性相辅相成
回顾IT发展史,事实上,可观测性与IT的发展是密不可分、相辅相成的。IT发展史大体来说可以分为三个时代,可观测性手段也随之不断的进步。
① 单机时代
早期IT对象较为单一,大型机时期,观测手段主要通过仪表盘进行,随着DOS的出现,可以通过命令查询信息,但此时并不具备监控的能力,直到Windows/Linux的出现,通过记录Syslog数据,使得大家可以在远端或者不在电脑上的情况下理解系统的信息。

而这种结构化的文本数据Syslog,如今在在业内,我们也通常称之为日志,实际上,日志就是最明细、最单元、也是最早出现的一种观测数据。
② 局域网时代
随着局域网时代的到来,存储成本变高,上述对结构化数据记录这种观测手段,存在着是信息量日趋庞大的问题,面对这样的挑战,一个划时代的数据——指标类型数据出现了,它通过将低维度的结构化事件进行升维,在此之后,我们逐渐能够对IT对象进行集群式的观测和监控,通过插件对结构化的日志聚合成指标数据,从而节省存储和网络的开销,这也是最早期监控的雏形。
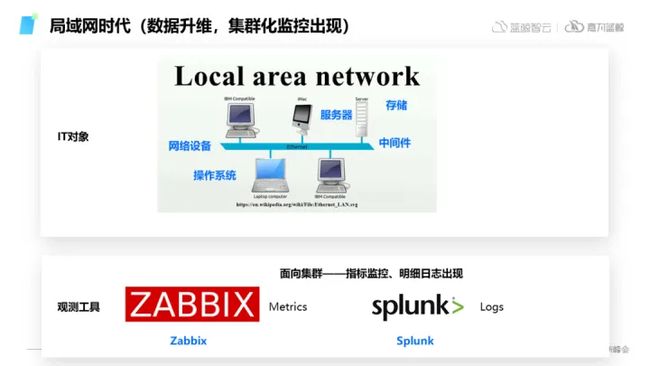
在这个时代,诞生了一些极具代表性的软件:Zabbix以及以日志为核心的Splunk,代表了集群化的局域网时代IT观测的的两种核心工具。
③ 互联网时代
我们来到现在的互联网时代,C端用户不断增多,在云原生技术的飞速推动下,IT面临着更多更复杂的对象和架构,如右上角CNCF矩阵图所示。
在这样一个对象暴涨的时代,依靠过去用插件做采集的模式已经逐渐行不通,于是云原生开发者们相应的开始做一些观测工具,为了拓展生态能力,适配对接更多类型的对象,开源社区共建共享的形式也逐渐铺开。诞生一些诸如DATADOG、dynatrace等较为代表性的工具。
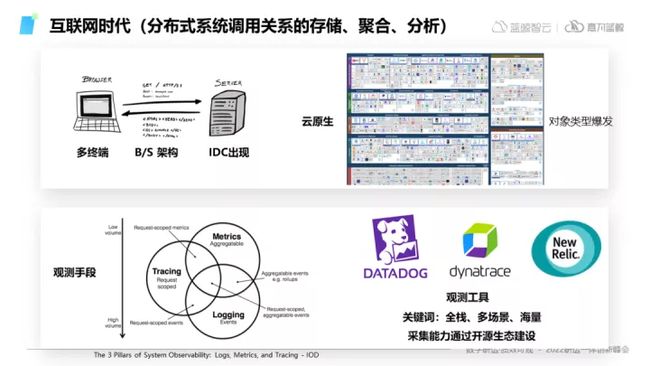
回顾整个观测手段的发展过程,其核心也是围绕经典三支柱Metrics、Logs和Traces在发展,其中Traces即是分布式架构时代下产生的新的元数据。在互联网时代,新的商业化的软件和企业也有以下一些与以往不同的思路,来实现现代化的可观测:
- 全栈覆盖更多观测手段
- 数据采集能力通过开源生态共建
- 海量数据处理,多场景支持
03. 工欲善其事,必先利其器
在整个可观测发展过程中,每一个企业可能都会建立一些监控工具、日志工具,但这些工具就像是散乱的零件,没有办法组装打通,各个工具之间体验也完全不一致。
这就好比过去我们需要进行拍照,打电话,阅读文本时,往往需要不同的工具,而到了现在,这些功能会被统一整合进手机里,以更高的效率、更好的体验来去解决问题。
“工欲善其事,必先利其器”。可观测性并非是简单的工具搭建,低整合度的工具排查问题时不仅效率低下,同时存在着跨系统排障不一定可行的隐患。那么如何“打磨利器”呢?这里我们看DATADOG提出的3个重要概念:Any Stack、Any Scale和Any APP。
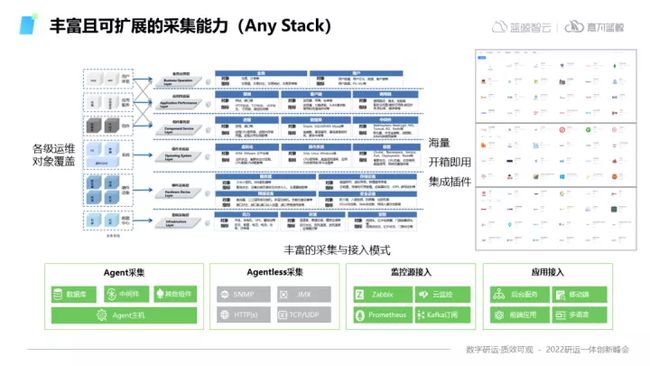
1)丰富且可扩展的采集能力(Any Stack)
运维系统最大的复杂度并不在于运维系统的建设,也不在于运维工具如何建设,而是在于运维的对象非常多,要求各种各样的运维专家来应对这些不同对象所产生的问题。
可观测性的建立第一步,即是强调需要具备丰富的从不同对象采集数据的能力。这也是整个观测系统建设的基础,实现方式主要有两个点,一是要依赖于开源社区的贡献,而是将采集能力建设为可插拔的方式。
2)灵活可扩展的大数据后台架构(Any Scale)
通常在做可观测时,都会面向一个非常大的系统,与传统局域网集群和单体监控不同,我们所面临的主要问题并不是稳定的指标数据,而是相对变化频繁的Logs,Traces数据,随着业务系统调用量的变化,如流量洪峰时,系统的数据压力就非常难以预测。所以,建立背后可弹性支持海量数据、能够扛住流量洪峰的后台架构,是系统稳定的重要保障。

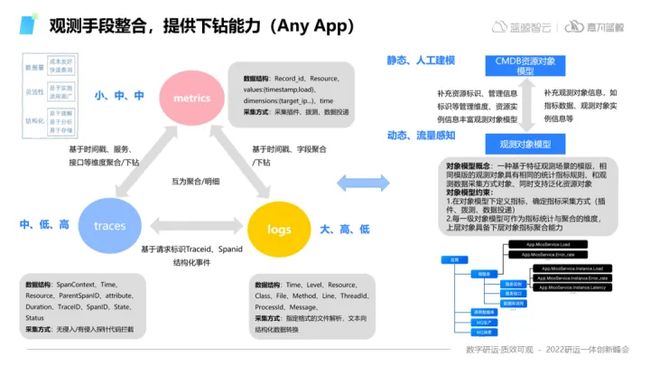
3)观测手段整合,提供下钻能力(Any App)
第三点Any App,是针对各类不同场景,都可提供相应工具或能力。一方面体现的场景在于对Traces Logs和Metrics数据之间相互映射的关系,从低维度数据聚合到中高维度,在实际使用过程中从高维数据产生的告警去探索和溯源。
另一方面,在整个运维系统组织构建时,CMDB的建模与可观测也是相辅相成的,在CMDB中建立资源对象模型后,能够进一步实现维度下钻,通过Traces的动态聚合,生成不同的微服务,从而获取不同时段下具体的指标有哪些,相关动态拓扑又是什么样的,从而更好的实现从宏观到微观角度排查问题。
04. 规程 OR 文化?
聊完了工具,我们最后再来谈一谈企业落地决策,到底是以一个好的规程,还是建立一个文化来去落地。这里我们的建议是根据企业组织现状来去决定。
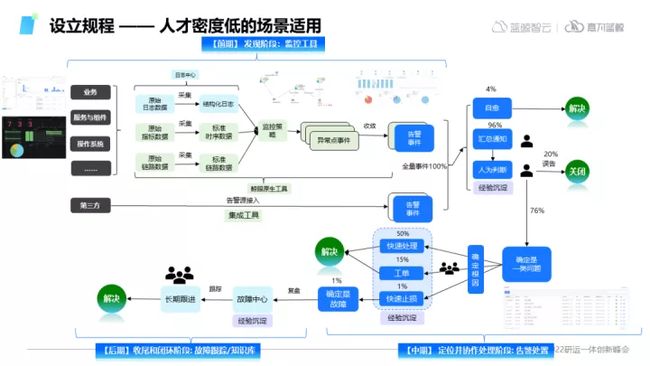
1)设立规程
这种思路比较适用于人才密度相对较低的团队,例如在一些企业中,会有一定的正式员工负责监控、观测的项目,同时会有一些外包团队帮助进行具体操作,在这种情况下,一般是Control(控制)大于Context(基于背景信息协作)的协作模式,也就是需要通过建立良好的流程来控制整套系统的运行。
在建立工具体系以后,制定好具体的流程策略以及相对于的负责团队,同时打通观测前中后期全流程,可以更好的控制整个团队排查问题的效率。
2)形成文化
在一些企业中,团队会追求运维向运维开发转型,或是运维工程师向SRE工程师的转型,企业希望能够将团队变得更加精英化,此时我们就需要去激发每个人的主观能动性,通过建立一些正向的反馈,让整个团队在过程中不仅得到技术上的精进,更能够从中获得成就感,从而形成一正向的循环。
同时我们也鼓励团队中积极分享更多的技术与方法论实践,将整个文化进行推广,不仅仅局限在运维团队之中,还需要与开发、业务团队之间沟通交流,跨团队的推广实践。其次,提早进行埋点设计,早期建设时就需要考虑可观测设计中可能出现的瓶颈,在后续的实际运行过程中,能够帮助更好的发现问题。

最后是鼓励工程师探索更多观测手段,而不是像传统的所谓“尽责”,单纯追求所有问题的呈现和记录,最后造成“狼来了”的局面,告警一直不停,但却不会去关注问题所在。这样的团队最终也就演变成为“互相甩锅”的割裂组织。
关于可观测性的内容还有很多,限于篇幅,我们仅仅只涉及到了冰山一角,当然可观测性的发展路途还很漫长。