pytorch模型推理提速
PyTorch 是一种使用动态计算图形的常见深度学习框架,借助它,我们可以使用命令语言和常用的 Python 代码轻松开发深度学习模型。推理是使用训练模型进行预测的过程。对于使用 PyTorch 等框架的深度学习应用程序,推理成本占计算成本的90%。由于深度学习模型需要不同数量的 GPU、CPU 和内存资源,为推理选择适当的实例有难度。在一个独立的 GPU 实例上对其中一个资源进行优化通常会导致其他资源利用不足。因此,我们可能要为未使用的资源付费。
Amazon Elastic Inference 通过支持将适量 GPU 支持推理加速附加到任何 Amazon SageMaker 或 EC2 实例或 Amazon ECS 任务中来解决此问题。我们可以在亚马逊云科技 (Amazon Web Services)中选择最适合应用程序整体计算和内存需求的 CPU 实例,并单独附加所需的适量 GPU 支持推理加速,以满足应用程序延迟要求。如此一来,就可以更加高效地使用资源并降低推理成本。今天,PyTorch 加入 TensorFlow 和 Apache MXNet 作为 Elastic Inference 支持的深度学习框架。撰写本文时发行的版本为1.3.1。
Amazon SageMaker 是一项完全托管的服务,为每个开发人员和数据科学家提供在 TensorFlow、Apache MXNet 和 PyTorch 等深度学习框架上快速构建、训练和部署机器学习(ML)模型的能力。Amazon SageMaker 通过提供在生产环境中部署机器学习模型和监控模型质量所需的一切来轻松生成预测。
下文将介绍如何使用 Elastic Inference 降低成本及改善 PyTorch 模型在 Amazon SageMaker 上的延迟。
TorchScript:弥合研究与生产之间的差距
我们现在讨论 TorchScript,它是从 PyTorch 代码中创建可序列化及可优化模型的一种方式。我们必须将模型转换为 TorchScript 才能将 Elastic Inference 与 PyTorch 结合使用。
PyTorch 使用动态计算图形大大简化了模型开发过程。然而,此模式为生产模型部署带来独特的挑战。在生产环境中,较好的方法是对模型进行静态图形表示。这不仅能让我们在使用 Python 较少的环境中使用该模型,还允许对性能和内存进行优化。
TorchScript 通过提供将模型编译并导出至没有使用 Python 的图形表示中的能力来弥合这一差距。我们可以通过将 PyTorch 模型转换为 TorchScript 来在任何生产环境中运行您的模型。TorchScript 还可以执行适时的图形级优化,从而提供比标准 PyTorch 更高的性能。
要将 Elastic Inference 与 PyTorch 结合使用,必须将模型转换为 TorchScript 格式,并将推理 API 用于 Elastic Inference。本文通过示例说明了如何将模型编译到 TorchScript 及如何使用支持 Elastic Inference 的 PyTorch 衡量端到端推理延迟的基准。最后,本文比较了各种不同的实例和加速器组合与独立 CPU 和 GPU 实例的性能和成本指标。
使用 TorchScript 编译和序列化模型
我们可以使用 tracing 或 scripting 将 PyTorch 模型编译到TorchScript 中。它们都会生成计算图形,但方式不同。
编写模型脚本的推荐方法通常是编译到 TorchScript,因为它会保留所有模型逻辑。然而在撰写本文时,可使用 PyTorch 1.3.1编写脚本的模型集比可跟踪的模型集小。模型或许可以跟踪,但不能编写脚本,或者根据无法跟踪。我们可能需要修改您的模型代码,以使其与 TorchScript 兼容。
由于 Elastic Inference 目前在 PyTorch 1.3.1 中处理控制流操作的方式,对于包含很多条件分支的脚本模型而言,推理延迟可能不是最优的。同时尝试跟踪和脚本,了解模型在使用 Elastic Inference 时的表现。随着1.3.1版本的发布,跟踪模型的表现可能比其脚本版本好。
有关更多信息,请参阅 PyTorch 网站上的 TorchScript 介绍教程。
脚本
脚本通过直接分析元代码来构建计算图形和保留控制流。下面的示例显示了如何使用脚本编译模型。它使用 TorchVision 为 ResNet-18 预训练的权重。我们可以将生成的脚本模型保存到一个文件中,然后使用支持 Elastic Inference 的 PyTorch 将它与 torch.jit.load 一起加载。请参阅以下代码:
import torchvision, torch
# Call eval() to set model to inference mode
model = torchvision.models.resnet18(pretrained=True).eval()
scripted_model = torch.jit.script(model)
跟踪
跟踪使用示例输入记录我们在该输入上运行模型时执行的操作。这意味着,由于只是通过一个输入来跟踪代码,然后来编译图形,控制流可能会被擦除。例如,模型定义可能拥有填充特定大小x图像的代码。如果使用另一种大小y的图像跟踪模型,将不会填充被注入跟踪模型的未来的大小x输入。发生这种情况是因为在使用特定输入进行跟踪时,并不会执行所有的代码路径。
下面的示例显示如何使用跟踪与随机化张量输入编译模型。它还使用 TorchVision 为 ResNet-18 预训练的权重。我们必须将 torch.jit.optimized_execution 上下文块与第二个参数用户设备序号,以将跟踪模型与 Elastic Inference 结合使用。这个修改的函数定义接受两个参数,仅可通过支持 Elastic Inference 的 PyTorch 框架提供。
如果使用标准的 PyTorch 框架跟踪模型,请忽略torch.jit.optimized_execution 数据块。我们仍然可以将生成的脚本模型保存到一个文件中,然后使用支持 Elastic Inference 的 PyTorch 将它与 torch.jit.load 一起加载。请参阅以下代码:
# ImageNet pre-trained models take inputs of this size.
x = torch.rand(1,3,224,224)
# Call eval() to set model to inference mode
model = torchvision.models.resnet18(pretrained=True).eval()
# Required when using Elastic Inference
with torch.jit.optimized_execution(True, {‘target_device’: ‘eia:0’}):
traced_model = torch.jit.trace(model, x)
保存并加载编译的模型
跟踪和脚本的输出为 ScriptModule,它是标准 PyTorch 的 nn.Module 的 TorchScript 模拟。对 TorchScript 模块进行序列化和反序列化分别与调用 torch.jit.save()和 torch.jit.load() 一样。它是使用 torch.save () 和 torch.load () 保存和加载标准 PyTorch 模型的 JIT 模拟。请参阅以下代码:
torch.jit.save(traced_model, 'resnet18_traced.pt')
torch.jit.save(scripted_model, 'resnet18_scripted.pt')
traced_model = torch.jit.load('resnet18_traced.pt')
scripted_model = torch.jit.load('resnet18_scripted.pt')
不同于保存的标准 PyTorch 模型,保存的 TorchScript 模型不会绑定到特定的类和代码目录。我们可以直接加载保存的 TorchScript 模型,无需先实例化模型类。如此一来,就可以在没有Python的环境中使用 TorchScript 模型。
带有 Elastic Inference PyTorch 的 Amazon SageMaker 中的端对端推理基准
下文将逐步介绍使用 Amazon SageMaker 托管终端节点衡量 DenseNet-121的支持 Elastic Inference 的 PyTorch 推理延迟基准的过程。
DenseNet-121是一种卷积神经网络(CNN),已在各种数据集的图像分类中取得一流结果。它的架构松散地建立在 ResNet(另一个常见的图像分类CNN)的基础上。
Amazon SageMaker 托管能力使得将模型部署到 HTTPS 终端节点变成可能,从而使模型可用于通过 HTTP 请求执行推理。
先决条件
此演示将 EC2 实例用作客户端,以启动并与 Amazon SageMaker 托管的终端节点交互。此客户端实例没有附加加速器;我们将启动终端节点,该终端节点可预置附加了加速器的托管实例。若要完成此演练,必须先完成以下先决条件:
Ø 创建 IAM 角色并添加 Amazon SageMaker FullAccess,此策略可授予使用 Amazon Elastic Inference 和 Amazon SageMaker 的权限。
- 确保 sagemaker.amazonaws.com 是“信任关系”下的受信任实体。
- 有关更多信息,请参阅为实例角色配置一个 Elastic Inference 策略和 Amazon SageMaker 角色。
Ø 启动 m5.large CPU EC2 实例。
使用 Linux 或 Ubuntu Deep Learning AMI (DLAMI) v27。
本文使用 DLAMI 中内置的 Elastic Inference 支持的 PyTorch Conda 环境,只访问 Amazon SageMaker 开发工具包,并使用 PyTorch 1.3.1 保存 DenseNet-121 权重。当 Amazon SageMaker Notebook 支持发布时,我们可以使用 Notebook 内核替代之。
托管的实例和加速器通过 Amazon DL Container 使用 Elastic Inference 支持的 PyTorch。为客户端实例选择的环境只能简化 Amazon SageMaker 开发工具包的使用,及使用 PyTorch 1.3.1保存模型权重。
演示
请完成以下步骤:
- 登录创建的实例。
- 使用以下命令激活Elastic Inference支持的PyTorch Conda环境:
source activate amazonei_pytorch_p36
- 创建一个名为script.py的空文件。此文件将用作托管容器的入口点。此文件为空,是为了触发默认的model_fn和predict_fn。默认predict_fn同时适用于标准PyTorch和Elastic
Inference支持的PyTorch。但默认model_fn只能为Elastic
Inference支持的PyTorch实施。如果要衡量标准PyTorch的基准,则需要像以前一样实施自己的model_fn。 - 在同一个目录中,使用以下代码创建名为create_sm_tarball.py的脚本:
import torch, torchvision
import subprocess
# Toggle inference mode
model = torchvision.models.densenet121(pretrained=True).eval()
cv_input = torch.rand(1,3,224,224)
model = torch.jit.trace(model,cv_input)
torch.jit.save(model, 'model.pt')
subprocess.call(['tar', '-czvf', 'densenet121_traced.tar.gz', 'model.pt'])
此脚本遵照 Amazon SageMaker 使用的命名约定(默认为 model.pt)创建原始码。DenseNet-121 的模型权重为经过预训练的 ImageNet,并且从 TorchVision 中提取。有关更多信息,请参阅将 PyTorch 与 SageMaker Python 开发工具包结合使用。
- 运行脚本以使用下列命令创建原始码:
python create_sm_tarball.py
- 使用以下代码创建名为create_sm_endpoint.py的脚本:
import sagemaker
from sagemaker.pytorch import PyTorchModel
sagemaker_session = sagemaker.Session()
region = YOUR_DESIRED_REGION
role = YOUR_IAM_ROLE_ARN
instance_type = 'c5.large'
accelerator_type = 'eia2.medium'
ecr_image = '763104351884.dkr.ecr.{}.amazonaws.com/pytorch-inference-eia:1.3.1-cpu-py3'.format(region)
# Satisfy regex
endpoint_name = 'pt-ei-densenet121-traced-{}-{}'.format(instance_type, accelerator_type).replace('.', '').replace('_', '')
tar_filename = 'densenet121_traced.tar.gz'
# script.py should be blank to use default EI model_fn and predict_fn
# For non-EI PyTorch usage, must implement own model_fn
entry_point = 'script.py'
# Returns S3 bucket URL
print('Upload tarball to S3')
model_data = sagemaker_session.upload_data(path=tar_filename)
pytorch = PyTorchModel(model_data=model_data, role=role, image=ecr_image, entry_point=entry_point, sagemaker_session=sagemaker_session)
# Function will exit before endpoint is finished creating
predictor = pytorch.deploy(initial_instance_count=1, instance_type='ml.' + instance_type, accelerator_type='ml.' + accelerator_type, endpoint_name=endpoint_name, wait=False)
我们需要修改脚本,以包含自己的亚马逊云科技账户ID、区域和 IAM ARN 角色。该脚本使用我们以前创建的原始码和空白入口点脚本来预置 Amazon SageMaker 托管的终端节点。此示例代码可衡量附加了 ml.eia2.medium 加速器的 ml.c5.large 托管实例的基准。
我们不必直接提供映像来创建终端节点,但为了清楚起见,此文会提供。有关其他框架的可用 Docker 容器的更多信息,请参阅深度学习容器镜像。
- 使用以下命令运行脚本,以创建附加了 ml.c5.large 和 ml.eia2.medium 的托管终端节点:
python create_sm_endpoint.py
- 转至 SageMaker 控制台并等待终端节点完成部署。此过程应该需要花费10分钟左右。现在已准备就绪,可以调用终端节点进行推理。
- 使用以下代码创建名为 benchmark_sm_endpoint.py 的脚本:
import sagemaker
from sagemaker.pytorch import PyTorchPredictor
import torch
import boto3
import datetime
import math
import numpy as np
import time
instance_type = 'c5.large'
accelerator_type = 'eia2.medium'
endpoint_name = 'pt-ei-densenet121-traced-{}-{}'.format(instance_type, accelerator_type).replace('.', '').replace('_', '')
predictor = PyTorchPredictor(endpoint_name)
data = torch.rand(1,3,224,224)
# Do warmup round of 100 inferences to warm up routers
print('Doing warmup round of 100 inferences (not counted)')
for i in range(100):
output = predictor.predict(data)
time.sleep(15)
client_times = []
print('Running 1000 inferences for {}:'.format(endpoint_name))
cw_start = datetime.datetime.utcnow()
for i in range(1000):
client_start = time.time()
output = predictor.predict(data)
client_end = time.time()
client_times.append((client_end - client_start)*1000)
cw_end = datetime.datetime.utcnow()
print('Client end-to-end latency percentiles:')
client_avg = np.mean(client_times)
client_p50 = np.percentile(client_times, 50)
client_p90 = np.percentile(client_times, 90)
client_p95 = np.percentile(client_times, 95)
client_p100 = np.percentile(client_times, 100)
print('Avg | P50 | P90 | P95 | P100')
print('{:.4f} | {:.4f} | {:.4f} | {:.4f}\n'.format(client_avg, client_p50, client_p90, client_p95, client_p100))
print('Getting Cloudwatch:')
cloudwatch = boto3.client('cloudwatch')
statistics=['SampleCount', 'Average', 'Minimum', 'Maximum']
extended=['p50', 'p90', 'p95', 'p100']
# Give 5 minute buffer to end
cw_end += datetime.timedelta(minutes=5)
# Period must be 1, 5, 10, 30, or multiple of 60
# Calculate closest multiple of 60 to the total elapsed time
factor = math.ceil((cw_end - cw_start).total_seconds() / 60)
period = factor * 60
print('Time elapsed: {} seconds'.format((cw_end - cw_start).total_seconds()))
print('Using period of {} seconds\n'.format(period))
cloudwatch_ready = False
# Keep polling CloudWatch metrics until datapoints are available
while not cloudwatch_ready:
time.sleep(30)
print('Waiting 30 seconds ...')
# Must use default units of microseconds
model_latency_metrics = cloudwatch.get_metric_statistics(MetricName='ModelLatency',
Dimensions=[{'Name': 'EndpointName',
'Value': endpoint_name},
{'Name': 'VariantName',
'Value': "AllTraffic"}],
Namespace="AWS/SageMaker",
StartTime=cw_start,
EndTime=cw_end,
Period=period,
Statistics=statistics,
ExtendedStatistics=extended
)
# Should be 1000
if len(model_latency_metrics['Datapoints']) > 0:
print('{} latency datapoints ready'.format(model_latency_metrics['Datapoints'][0]['SampleCount']))
print('Side-car latency percentiles:')
side_avg = model_latency_metrics['Datapoints'][0]['Average'] / 1000
side_p50 = model_latency_metrics['Datapoints'][0]['ExtendedStatistics']['p50'] / 1000
side_p90 = model_latency_metrics['Datapoints'][0]['ExtendedStatistics']['p90'] / 1000
side_p95 = model_latency_metrics['Datapoints'][0]['ExtendedStatistics']['p95'] / 1000
side_p100 = model_latency_metrics['Datapoints'][0]['ExtendedStatistics']['p100'] / 1000
print('Avg | P50 | P90 | P95 | P100')
print('{:.4f} | {:.4f} | {:.4f} | {:.4f}\n'.format(side_avg, side_p50, side_p90, side_p95, side_p100))
cloudwatch_ready = True
此脚本使用大小为 1 x 3 x 224 x 224 的张量(图像分类的标准值)。首先,它会运行一系列的100个预热推理,然后再运行1000个推理。延迟百分位数仅使用这1000个推理报告。
本文使用延迟指标 ModelLatency。此指标将发送到 Amazon CloudWatch 并在 Amazon SageMaker 系统内捕获推理延迟。有关更多信息,请参阅使用Amazon CloudWatch监控Amazon SageMaker。
我们需要使用 TorchScript 编译模型并在原始码中将其另存为 model.pt。
当使用附加到托管实例的加速器调用终端节点时,Amazon SageMaker 将在默认情况下调用默认的 model_fn 和 predict_fn。如果在没有加速器的 Amazon SageMaker 中使用 PyTorch,需要通过入口点脚本提供自己的 model_fn 实现。
默认的 model_fn 使用 torch.jit.load(‘model.pt’) 加载模型权重,因为它假设我们以前使用 TorchScript 对模型进行了序列化,并且遵循了文件名约定。附加了加速器时,默认的 predict_fn 使用 torch.jit.optimized_execution 数据库,指定模型应经过优化后才能在附加的Elastic Inference加速器上运行。否则 predict_fn 将以标准的 PyTorch 方式进行推理。请注意,撰写本文时 Amazon SageMaker 不支持多附加,因此设备序号始终被设置为0。
如果决定在使用 Elastic Inference 时实施自己的 predict_fn,必须记得使用 torch.jit.optimized_execution 上下文,否则推理将完全运行在托管实例上,且不会使用附加的加速器。有关更多信息请参阅将 PyTorch 与 SageMaker Python 开发工具包结合使用。
默认处理程序提供在 GitHub 上。
- 使用以下命令运行基准脚本:
python benchmark_sm_endpoint.py
随后应该会看到类似于以下内容的输出:
Doing warmup round of 100 inferences (not counted)
Running 1000 inferences for pt-ei-densenet121-traced-c5large-eia2medium:
Client end-to-end latency percentiles:
Avg | P50 | P90 | P95 | P100
64.7758 | 61.7952 | 73.7203 | 77.3841
Getting Cloudwatch:
Time elapsed: 364.777493 seconds
Using period of 420 seconds
Waiting 30 seconds ...
1000.0 latency datapoints ready
Side-car latency percentiles:
Avg | P50 | P90 | P95 | P100
47.8507 | 46.1647 | 51.7429 | 56.7705
选择适当的实例
部署新的推理工作负载时,有很多实例类型可供选择。应该考虑以下关键参数:
- 内存 – 需要选择为应用程序提供充足的 CPU和加速器内存的托管实例和加速器组合。可以将运行时内存要求下界指定为输入张量大小和模型大小的总和。然而,运行时内存使用量通常显著高于任何模型的下界,并且根据框架不同而不同。应该仅使用此指南来帮助大致知道CPU 实例和 Elastic Inference 加速器选择。
- 延迟要求 –当拥有一组具有足够内存的托管实例和加速器后,可以将选择范围进一步缩小到满足应用程序延迟要求的那些实例和加速器。本文将每次推理的延迟视为评估性能的关键指标。按单位时间处理的图像或单词的推理吞吐量是另一个常用指标。
- 成本 – 当拥有一组同时满足内存和延迟要求的硬件组合后,可以通过选择为每次推理提供最低价格的组合来优化成本效率。可以将此指标计算为(价格/ 秒 *每次推理调用的平均延迟)。为了使数字更加具体,本文提供每100000次推理的费用。我们可以比较工作负载的成本效率,并通过这样做来为每个硬件组合选择最佳硬件。本文使用美国西部(俄勒冈)区域的每小时价格。
现已准备就绪,可应用此过程来选择最佳实例以运行 DenseNet-121。首先,评估应用程序的内存和 CPU 要求,并将符合要求的托管实例和加速器子集列入候选名单。
接下来,了解一下延迟性能。本文对每个实例都使用相同的张量输入和 DenseNet-121 的 TorchVision ImageNet 预训练权重。我们使用此输入在模型上运行1000次推理,收集每次运行的延迟,并报告平均延迟和第90个百分位的延迟(P90延迟)。本文要求 P90 延迟低于80毫秒,也就是说所有推理调用中90%的调用延迟应低于80ms。
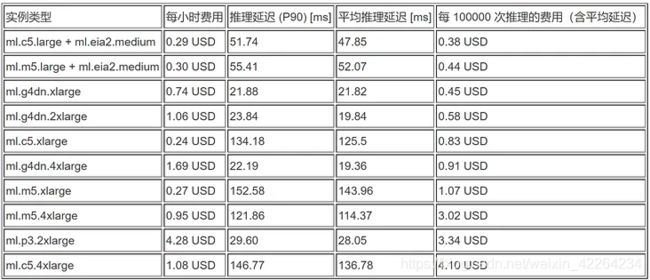
我们将 Amazon Elastic Inference 加速器附加在三种类型的 CPU 托管实例上,并为其各自运行前述性能测试。下面列出了每小时价格、每次推理调用的平均延迟和每100000次推理的费用。下面的所有组合均满足延迟预置。

可以看到不同托管实例对延迟的影响。对于相同加速器类型,使用更强大的托管实例不会显著改善延迟。然而,附加较大的加速器可降低延迟,因为模型运行在加速器上,且较大的加速器拥有更多的资源,如 GPU 计算和内存。我们应该选择可为应用程序提供足够 CPU 内存的最便宜的托管实例类型。ml.m5.large 或 ml.c5.large 足够用于很多使用案例,但并非全部使用案例。
基于前述标准,本文选择满足延迟要求的两个成本最低的选项,即带有 ml.eia2.medium 的 ml.c5.large 和带有 ml.eia2.medium 的ml.m5.large。对于此使用案例,两者都是可行的。
比较不同实例在 SageMaker 中的推理情况
本文还收集了 CPU 和 GPU 托管实例的延迟和性价比数据,并且还与前述Elastic Inference 基准进行了比较。所用的独立 CPU 实例包括ml.c5.xl、ml.c5.4xl、ml.m5.xl 和 ml.m5.4xl。所用的独立GPU实例包括 ml.p3.2xl、ml.g4dn.xl、ml.g4dn.2xl 和 ml.g4dn.4xl。
下面的汇总表显示了 Elastic Inference 支持的选项的性价比数据,随后显示了独立实例选项。
为了更好地了解 Elastic Inference 在独立 CPU 和 GPU 实例上带来的性价比,我们可以针对每种硬件类型使用图形显示此延迟和成本数据。下面的条形图绘制了每100000次推理的费用,线形图绘制了 P90 推理延迟(以毫秒为单位)。深灰色条形指的是带有 Elastic Inference 加速器的实例,绿色条形指的是独立的 GPU 实例,蓝色条形指的是独立的 CPU 实例。
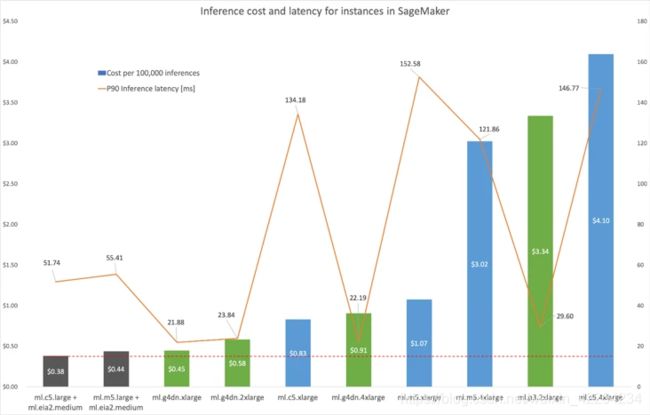
延迟分析
跟预期的一样,CPU 实例的性能不如 GPU 实例的性能。ml.g4dn.xl 实例的速度约比 CPU 实例快7倍。所有的独立 CPU 实例都不满足80ms 的 P90 延迟阈值。
然而这些 CPU 实例在附加了 Elastic Inference 的情况下性能更好,因为它们受益于 GPU 加速。带有 ml.eia2.medium 的 ml.c5.large实例将推理速度提高到独立 CPU 实例的接近3倍。然而独立的 GPU 实例仍然比附加了 Elastic Inference 的 CPU 实例好;ml.g4dn.xl 的速度比带有 ml.eia2.medium 的 ml.c5.large 的速度快两倍多一点。请注意,ml.g4dn.xl、ml.g4dn.2xl和ml.g4dn.4xl 实例的延迟大致相等,差异可忽略不计。全部三个 ml.g4dn 实例都具有相同的GPU,但较大的 ml.g4dn 实例拥有更多的vCPU和内存资源。对于 DenseNet-121 而言,增加 vCPU 和内存资源不会改善推理延迟。
Elastic Inference 和独立的 GPU 实例都满足延迟要求。
成本分析
在成本方面,带有ml.eia2.medium 的 ml.c5.large 表现比较突出。虽然带有 ml.eia2.medium 的 ml.c5.large不具有最低的每小时价格,但它每100000次推理的费用是最低的。有关每小时定价的更多信息,请参阅 Amazon SageMaker 定价。
可以得出结论:每小时成本较低的实例在每次推理时所花费的费用并不一定也低。这是因为它们的每次推理延迟可能会较高。同样地,每次推理时延迟较低的实例可能不会产生较低的每次推理费用。ml.m5.xlarge 和 ml.c5.xlarge CPU 实例拥有最低的每小时价格,但其每次推理的费用仍高于大多数Elastic Inference 和独立 GPU 选项。较大的 ml.m5.4xlarge 和 ml.c5.4xlarge 实例具有较高的延迟、较多的每小时费用,因此,其每次推理的费用高于所有 Elastic Inference 选项。独立的GPU 实例由于 CUDA 操作所利用的高计算并行化,全面实现了最佳延迟。然而 Elastic Inference 的每次推理费用最低。
使用 Amazon Elastic Inference,我们可以获得两全其美的结果,可以最有效地利用GPU提供的并行化和推理加速,获得比 CPU 和 GPU 独立实例更大的成本效益。此外,我们还可以灵活地解耦托管实例和推理加速硬件,以便针对 vCPU、内存和应用程序需要的所有其他资源灵活地优化硬件。
前述测试证明,带有 ml.eia2.medium 的 ml.c5.large 是费用最低的选项,它满足运行 DenseNet-121 的延迟标准和内存使用要求。
本文使用的延迟指标(CloudWatch Metrics 中发布的 ModelLatency)可衡量 Amazon SageMaker 内的延迟。此延迟指标未考虑到从应用程序到 Amazon SageMaker 的延迟。确保在衡量应用程序的基准时考虑到这些延迟。
小结
Amazon Elastic Inference 是一项灵活的低成本解决方案,适用于Amazon SageMaker 上的 PyTorch 推理工作负载。通过将 Elastic Inference 加速器附加到 Amazon SageMaker 实例,我们可以获得类似于 GPU 的推理加速并保持比独立的 Amazon SageMaker GPU 和 CPU 实例更高的成本效益。更多信息请参阅什么是 Amazon Elastic Inference?
reference
https://segmentfault.com/a/1190000023367656?utm_source=tag-newest