《人工智能及其应用(第6版)》蔡自兴1-6章课后习题.【部分无答案】

第一章 绪论:
1-1什么是人工智能?试从学科和能力两方面加以说明。
人工智能(学科):人工智能(学科)是计算机科学中涉及研究、设计和应用智能机器的一个分支。其近期的主要目标在于研究用机器来模仿和执行人脑的某些智力功能,并开发相关理论和技术。
人工智能(能力):人工智能(能力)是智能机器所执行的通常与人类智能有关的智能行为,如判断、推理、证明、识别、感知、理解、通信、设计、思考、规划、学习和问题求解等思维活动。
1-5为什么能够用机器(计算机)模仿人的智能?
物理符号系统假设:任何一个系统,如果它能够表现出智能,那么它就必定能够执行上述6种功能。反之,任何系统如果具有这6种功能,那么它就能够表现出智能;这种智能指的是人类所具有的那种智能。
推论:既然人是一个物理符号系统,计算机也是一个物理符号系统,那么就能够用计算机来模拟人的活动。因此,计算机可以模拟人类的智能活动过程。
1-7你认为应从哪些层次对认知行为进行研究?
答:应从下面4个层次对谁知行为进行研究:
(1)认知生理学:研究认知行为的生理过程,主要研究人的神经系统(神经元、中枢神经系统和大脑)的活动。
(2)认知心理学:研究认知行为的心理活动,主要研究人的思维策略。
(3)认知信息学:研究人的认知行为在人体内的初级信息处理,主要研究人的认知行为如何通过初级信息自然处理,由生理活动变为心理活动及其逆过程
(4)认知工程学:研究认知行为的信息加工处理,主要研究如何通过以计算机为中心的人工信息处理系统,对人的各种认知行为(如知觉、思维、记忆、语言、学习、理解、推理、识别等)进行信息处理。
1-8人工智能的主要研究和应用领域是什么?
问题求解,逻辑推理与定理证明,自然语言理解,自动程序设计,专家系统,机器学习,神经网络,机器人学,模式识别,机器视觉,智能控制,智能检索,智能调度与指挥,分布式人工智能与Agent,计算智能与进化计算,数据挖掘与知识发现,人工生命。
1-9人工智能研究包括哪些内容?这些内容的重要性如何?
知识表示、知识推理和知识应用是传统人工智能的三大核心研究内容。其中,知识表示是基础,知识推理实现问题求解,而知识应用是目的。
1-10人工智能的基本研究方法有哪几类?它们与人工智能学派的关系如何?
功能模拟法:符号主义学派结构模拟法:连接主义学派行为模拟法:行为主义学派
集成模拟法:各学派密切合作,取长补短
第二章 知识表示方法:
2.1状态空间法、问题归约法、谓词逻辑法和语义网络法的要点是什么?它们有何本质上的联系及异同点?
状态空间法是一种基于解答空间的问题表示和求解方法,它是以状态和操作符为基础的.在利用状态空间图表示时,从某个初始状态开始,每次加一个操作符,递增地建立起操作符的试验序列,直到达到目标状态为止.由于状态空间法需要扩展过多的节点,容易出现“组合爆炸”,因而只适用于表示比较简单的问题.
问题归约法从目标(要解决的问题)出发,逆向推理,通过一系列变换把初始问题变换为子问题集合和子子问题集合,直至最后归约为一个平凡的本原问题集合.这些本原问题的解可以直接得到,从而解决了初始问题,用与或图来有效地说明问题归约法的求解途径.
谓词逻辑法采用谓词合适公式和一阶谓词演算把要解决的问题变为一个有待证明的问题,然后采用消解定理和消解反演来证明一个新语句是从已知的正确语句导出的,从而证明这个新语句也是正确的.
本质上都是将人工智能问题求解效率提高的知识表示方法,处理不同问题时应视情况采取不同的方法,在表达和求解复杂问题时需要综合使用这些方法。语义网络是知识的一种图解表示,它由节点和弧线或链线组成.节点用于表示实体、概念和情况等,弧线用于表示节点间的关系.语义网络的解答是一个经过推理和匹配而得到的具有明确结果的新的语义网络.语义网络可用于表示多元关系,扩展后可以表示更复杂问题.
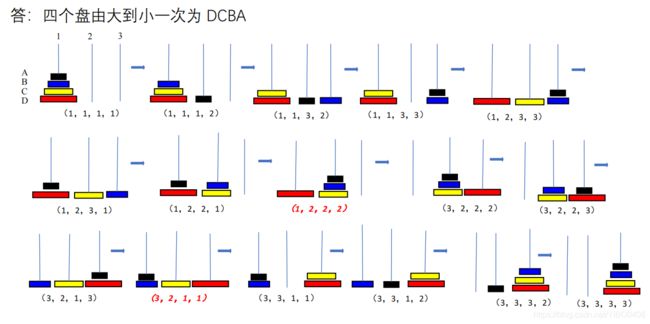
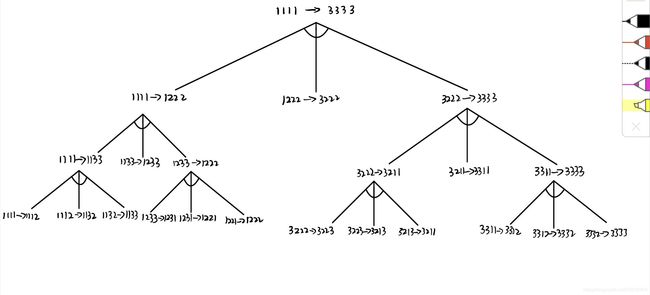
2.5 试用四元数列结构表示四圆盘梵塔问题
2-6用谓词逻辑演算公式表示:A computer system is intelligent if it can perform a task which,if performed by a human, requires intelligence.
P(x,y): x performs y task (x 完成有任务)
Q(y): y requires intelligence (y 需要智能)
C(x): x is a computer system (x 是计算机系统)
I(x): x is intelligent (x 是智能系统)
(∀)(∃y)(()P(, )P(human, )Q() → ())
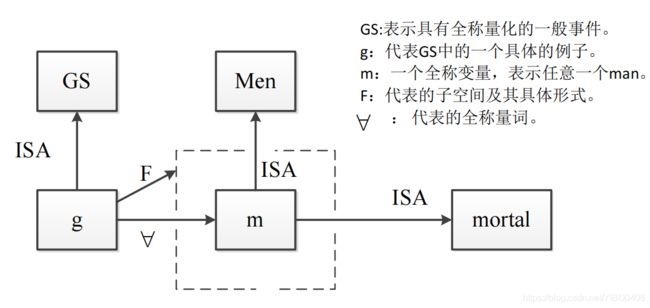
2-7 把下列语句用语义网络描述:
1.All man are mortal.
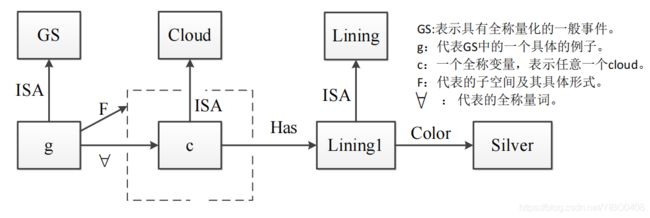
2.Every cloud has a silver lining.
3.All branch managers of DEC participate in a profit-sharing plan.

第三章 搜索推理技术:
3-1什么是图搜索过程,其中,重排OPEN表意味着什么,重排的原则是什么?
图搜索的一般过程如下:
(1)建立一个搜索图G(初始只含有起始节点S),把S放到未扩展节点表中(OPEN表)中。
(2)建立一个已扩展节点表(CLOSED表),其初始为空表。
(3) LOOP:若OPEN表是空表,则失败退出。
(4)选择OPEN表上的第一个节点,把它从OPEN表移出并放进CLOSED表中。称此节点为节点n,它是CLOSED表中节点的编号
(5)若n为一目标节点,则有解并成功退出。此解是追踪图G中沿着指针从n到S这条路径而得到的(指针将在第7步中设置)
(6)扩展节点n,生成不是n的祖先的那些后继节点的集合M。将M添入图G中。
(7)对那些未曾在G中出现过的(既未曾在OPEN表上或CLOSED表上出现过的)M成员设置一个通向n的指针,并将它们加进OPEN表。
对已经在OPEN或CLOSED表上的每个M成员,确定是否需要更改通到n的指针方向。对已在CLOSED表上的每个M成员,确定是否需要更改图G中通向它的每个后裔节点的指针方向。
(8)按某一任意方式或按某个探试值,重排OPEN表。
(9) GO LOOP
重排OPEN表意味着,在第(6)步中,将优先扩展哪个节点,不同的排序标准对应着不同的搜索策略。
重排的原则当视具体需求而定,不同的原则对应着不同的搜索策略,如果想尽快地找到一个解,则应当将最有可能达到目标节点的那些节点排在OPEN表的前面部分,如果想找到代价最小的解,则应当按代价从小到大的顺序重排OPEN表。
3-3
任一谓词演算公式可以化成一个子句集。其变换过程由下列九个步骤组成:
(1)消去蕴涵符号,将蕴涵符号化为析取和否定符号
(2)减少否定符号的辖域,每个否定符号最多只用到一个谓词符号上,并反复应用狄·摩根定律
(3)对变量标准化,对哑元改名以保证每个量词有其自己唯一的哑元
(4)消去存在量词,引入Skolem函数,消去存在量词+如果要消去的存在量词不在任何一个全称量词的辖域内,那么我们就用不含变量的Skolem函数即常量。
(5)化为前束形,把所有全称量词移到公式的左边,并使每个量词的辖域包括这个量词后面公式的整个部分。
前束形=(前缀)(母式) 前缀=全称量词串 母式=无量词公式
(6)把母式化为合取范式+反复应用分配律,将母式写成许多合取项的合取的形式,而每一个合取项是一些谓词公式和(或)谓词公式的否定的析取
(7)消去全称量词+消去前缀,即消去明显出现的全称量词
(8)消去连词符号(合取),用{合取项1,合取项2}替换明显出现的合取符号
(9)更换变量名称,更换变量符号的名称,使一个变量符号不出现在一个以上的子句中
3-4如何通过消解反演求取问题的答案?
给出一个公式集S和目标公式L,通过反证或反演来求证目标公式L,其证明步骤如下:(1)否定L,得~L;(2)把~L添加到S中去;
(3)把新产生的集合{~L,S}化成子句集;
(4)应用消解原理,力图推导出一个表示矛盾的空子句NIL。
3-7 用有界深度优先搜索方法求解图3.34所示八数码难题。

3-9试比较宽度优先搜索试比较宽度优先搜索有界深度优先搜索及有序搜索的搜索效率并以实例数据加以说明。
广度优先搜索:广度优先搜索是按照树的层次进行的搜索,如果此层没有搜索完成的情况下不会进行下一层的搜索。以二叉树做例子,
深度优先搜索:深度优先搜索是按照树的深度进行搜索的,所以又叫纵向搜索,在每一层只扩展一个节点,直到为树的规定深度或叶子节点为止。这个便称为深度优先搜索。
广度优先搜索,适用于所有情况下的搜索,但是深度优先搜索不一定能适用于所有情况下的搜索。因为由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。所以,深度优先搜索策略是不完备的。广度优先搜索适用范围:在未知树深度情况下,用这种算法很保险和安全。在树体系相对小不庞大的时候,广度优先也会更好些。深度优先搜索适用范围:刚才说了深度优先搜索又自己的缺陷,但是并不代表深度优先搜索没有自己的价值。在树深度已知情况下,并且树体系相当庞大时,深度优先搜索往往会比广度优先搜索优秀,因为比如8*8的马踏棋盘中,如果用广度搜索,必须要记录所有节点的信息,这个存储量一般电脑是达不到的。然而如果用深度优先搜索的时候却能在一个棋盘被判定出来后释放之前的节点内存。当让具体情况还是根据具体的实际问题而定,并没有哪种绝对的好。所关于找最优解的问题,如果不依靠其他的辅助算法来说,其实对于广度优先搜索和深度优先搜索来说是一样的,说白了找最优解就是个遍历过程,所以没有哪种算法找最优解更好。但是如果有辅助的启发式算法或者别的算法就另当别论了。
3-12



第四章 计算智能:
4-1 计算智能的含义是什么?它涉及哪些研究分支?
贝兹德克认为计算智能取决于制造者提供的数值数据,而不依赖于知识。计算智能是智力的低层认知。
主要的研究领域为神经计算,模糊计算,进化计算,人工生命。
4-2 试述计算智能(CI)、人工智能(AI)和生物智能(BI)的关系。
计算智能(Computational Intelligence)是借鉴仿生学的思想,基于人们对生物体智能机理的认识,采用数值计算的方法去模拟和实现人类的智能。
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
生物智能(Biological Intelligence),就是指各种生物动植物所表现出来的智能,尤其是动物和人类,这一篇我们着重讨论简单生物的智能。
4-3 人工神经网络为什么具有诱人的发展前景和潜在的广泛应用领域?
人工神经网络具有如下至关重要的特性:
(1) 并行分布处理
适于实时和动态处理
(2) 非线性映射
给处理非线性问题带来新的希望
(3) 通过训练进行学习
一个经过适当训练的神经网络具有归纳全部数据的能力,能够解决那些由数学模型或描述规则难以处理的问题
(4) 适应与集成
神经网络的强适应和信息融合能力使得它可以同时输入大量不同的控制信号,实现信息集成和融合,适于复杂,大规模和多变量系统
(5) 硬件实现
一些超大规模集成是电路实现硬件已经问世,使得神经网络成为具有快速和大规模处理能力的网络。
4-4简述生物神经元及人工神经网络的结构和主要学习算法。
生物:树突,轴突,突触
人工:
递归(反馈)网络(feedback network,recurrent network)多个神经元互连组织成一个互连神经网络
前馈(多层)网络(feedforward network)具有递阶分层结构,同层神经元间不存在互连
主要学习算法:
有师学习算法:能够根据期望的和实际的网络输出(对应于给定输入)间的差来调整神经元间连接的强度或权。
无师学习算法:不需要知道期望输出。
强化学习算法:采用一个“评论员”来评价与给定输入相对应的神经网络输出的优度(质量因数)。
强化学习算法的一个例子是遗传算法(GA)。
4-6 构造一个神经网络,用于计算含有2个输入的XOR函数,指明所用单元的类型。

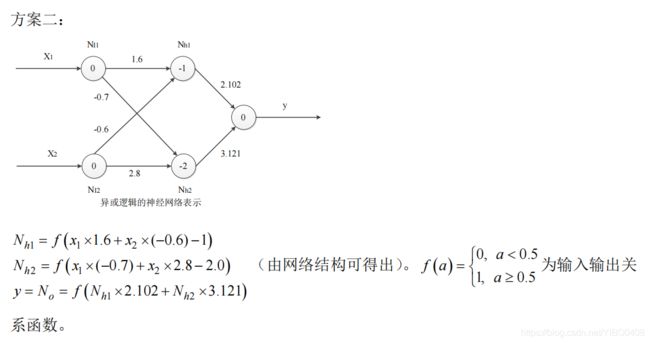
4-14试述遗传算法的基本原理,并说明遗传算法的求解步骤。
遗传算法的基本原理如下:通过适当的编码方式把问题结构变为位串形式(染色体),在解空间中取一群点作为遗传开始的第一代,染色体的优劣程度用一个适应度函数来衡量,每一代在上一代的基础上随机地通过复制、遗传、变异来产生新的个体,不断迭代直至产生符合条件的个体为止。迭代结束时,一般将适应度最高的个体作为问题的解。
一般遗传算法的主要步骤如下:
(1)随机产生一个由确定长度的特征字符串组成的初始群体。
(2)对该字符串群体迭代的执行下面的步 (a) 和 (b) ,直到满足停止标准:
(a) 计算群体中每个个体字符串的适应值;
(b) 应用复制、交叉和变异等遗传算子产生下一代群体。
(3) 把在后代中出现的最好的个体字符串指定为遗传算法的执行结果,这个结果可以表示问题的一个解。
第五章 专家系统:
5-1 什么叫做专家系统?它具有哪些特点与优点?
专家系统是一种模拟人类专家解决领域问题的智能计算机程序系统,其内部含有大量的某个领域专家水平的知识与经验,能够利用人类专家的知识和解决问题的方法来处理该领域问题。也就是说,专家系统是一个具有大量的专门知识与经验的程序系统,它应用人工智能技术和计算机技术,根据某领域一个或多个专家提供的知识和经验,进行推理和判断,模拟人类专家的决策过程,以便解决那些需要人类专家处理的复杂问题。
特点:
(1) 启发性
专家系统能运用专家的知识与经验进行推理、判断和决策
(2) 透明性
专家系统能够解释本身的推理过程和回答用户提出的问题,以便让用户能够了解推理过程,提高对专家系统的信赖感。
(3) 灵活性
专家系统能不断地增长知识,修改原有知识,不断更新。
优点:
(1) 专家系统能够高效率、准确、周到、迅速和不知疲倦地进行工作。
(2) 专家系统解决实际问题时不受周围环境的影响,也不可能遗漏忘记。
(3) 可以使专家的专长不受时间和空间的限制,以便推广珍贵和稀缺的专家知识与经验。
(4) 专家系统能促进各领域的发展,它使各领域专家的专业知识和经验得到总结和精炼,能够广泛有力地传播专家的知识、经验和能力。
(5) 专家系统能汇集多领域专家的知识和经验以及他们协作解决重大问题的能力,它拥有更渊博的知识、更丰富的经验和更强的工作能力。
(6) 军事专家系统的水平是一个国家国防现代化的重要标志之一。
(7) 专家系统的研制和应用,具有巨大的经济效益和社会效益。
(8) 研究专家系统能够促进整个科学技术的发展。专家系统对人工智能的各个领域的发展起了很大的促进作用,并将对科技、经济、国防、教育、社会和人民生活产生极其深远的影响。
5-2 专家系统由哪些部分构成?各部分的作用为何?
(1) 知识库(knowledge base)
知识库用于存储某领域专家系统的专门知识,包括事实、可行操作与规则等。
(2) 综合数据库(global database)
综合数据库又称全局数据库或总数据库,它用于存储领域或问题的初始数据和推理过程中得到的中间数据(信息),即被处理对象的一些当前事实。
(3) 推理机(reasoning machine)
推理机用于记忆所采用的规则和控制策略的程序,使整个专家系统能够以逻辑方式协调地工作。推理机能够根据知识进行推理和导出结论,而不是简单地搜索现成的答案。
(4) 解释器(explanator)
解释器能够向用户解释专家系统的行为,包括解释推理结论的正确性以及系统输出其它候选解的原因。
(5) 接口(interface)
接口又称界面,它能够使系统与用户进行对话,使用户能够输入必要的数据、提出问题和了解推理过程及推理结果等。系统则通过接口,要求用户回答提问,并回答用户提出的问题,进行必要的解释。
5-3 建造专家系统的关键步骤是什么?
是否拥有大量知识是专家系统成功与否的关键,因而知识表示就成为设计专家系统的关键
(1) 设计初始知识库
问题知识化, 知识概念化, 概念形式化, 形式规则化, 规则合法化
(2) 原型机(prototype)的开发与试验
建立整个系统所需要的实验子集,它包括整个模型的典型知识,而且只涉及与试验有关的足够简单的任务和推理过程
(3) 知识库的改进与归纳
反复对知识库及推理规则进行改进试验,归纳出更完善的结果
5-4 专家系统程序与一般的问题求解软件程序有何不同?开发专家系统与开发其它软件的任务有何不同?
一般应用程序与专家系统的区别在于:前者把问题求解的知识隐含地编入程序,而后者则把其应用领域的问题求解知识单独组成一个实体,即为知识库。知识库的处理是通过与知识库分开的控制策略进行的。
更明确地说,一般应用程序把知识组织为两级:数据级和程序级;大多数专家系统则将知识组织成三级;数据、知识库和控制。
在数据级上,是已经解决了的特定问题的说明性知识以及需要求解问题的有关事件的当前状态。
在知识库级是专家系统的专门知识与经验。是否拥有大量知识是专家系统成功与否的关键,因而知识表示就成为设计专家系统的关键。
在控制程序级,根据既定的控制策略和所求解问题的性质来决定应用知识库中的哪些知识。
5-5 基于规则的专家系统是如何工作的?其结构为何?
系统的主要部分是知识库和推理引擎。
知识库由谓词演算事实和有关讨论主题的规则构成。"知识工程师"与应用领域的专家共同工作以便把专家的相关知识表示成一种形式,由一个知识采集子系统协助,输入到知识库。
推理引擎由所有操纵知识库来演绎用户要求的信息的过程构成-如消解、前向链或反向链。
用户接口可能包括某种自然语言处理系统,它允许用户用一个有限的自然语言形式与系统交互。也可是用带有菜单的图形接口界面。
解释子系统分析被系统执行的推理结构,并把它解释给用户。
5-6 什么是基于框架的专家系统?与面向目标编程有何关系?
基于框架的专家系统采用了面向目标的编程技术,以提高系统的能力和灵活性。它们共享许多特征。
面向目标的编程其所有数据结构均以目标形式出现,每个目标含有两种基本信息:描述目标的信息和说明目标能做什么的信息。面向目标的编程为表示实际世界目标提供了一种自然的方法。
应用专家系统的术语来说,每个目标具有陈述性知识和过程知识。
5-7 基于框架的专家系统结构有何特点?其设计任务是什么?
基于框架的专家系统结构的主要特点在于基于框架的专家系统采用框架而不是规则来表示知识。框架提供一种比规则更丰富的获取问题知识的方法,不仅提供某些目标的包描述,而且还规定了该目标如何工作。
开发基于框架的专家系统的主要任务有
(1) 定义问题(对问题和结论的考察与综述)
(2) 分析领域(定义事物,事物特征,事件和框架结构)
(3) 定义类及其特征
(4) 定义例及其框架结构
(5) 确定模式匹配规则
(6) 规定事物通信方法
(7) 设计系统界面
(8) 对系统进行评价
(9) 对系统进行扩展,深化和扩宽知识。
5-8 为什么要提出基于模型的专家系统?试述神经网络专家系统的一般结构。
有一种关于人工智能的观点认为:人工智能是对各种定性模型的获得、表达及使用的计算方法进行研究的学问。根据这一观点,一个知识系统中的知识库是由各种模型综合而成的,而这些模型又往往是定性的模型。
采用各种定性模型来设计专家系统,一方面它增加了系统的功能,提高了性能指标,另一方面,可独立地深入研究各种模型及其相关问题,把获得的结果用于改进系统设计。
第六章 机器学习:
6-1 什么是学习和机器学习?为什么要研究机器学习?
按照人工智能大师西蒙的观点,学习就是系统在不断重复的工作中对本身能力的增强或者改进,使得系统在下一次执行同样任务或类似任务时,会比现在做得更好或效率更高。
机器学习是研究如何使用机器来模拟人类学习活动的一门学科,是机器学习是一门研究机器获取新知识和新技能,并识别现有知识的学问。这里所说的“机器”,指的就是计算机。
现有的计算机系统和人工智能系统没有什么学习能力,至多也只有非常有限的学习能力,因而不能满足科技和生产提出的新要求。
6-5试说明归纳学习的模式和学习方法。
归纳是一种从个别到一般,从部分到整体的推理行为。 归纳学习的一般模式为:
给定:观察陈述(事实)F,假定的初始归纳断言(可能为空),及背景知识 求:归纳断言(假设)H,能重言蕴涵或弱蕴涵观察陈述,并满足背景知识。 学习方法 (1) 示例学习
它属于有师学习,是通过从环境中取得若干与某概念有关的例子,经归纳得出一般性概念的一种学习方法。示例学习就是要从这些特殊知识中归纳出适用于更大范围的一般性知识,它将覆盖所有的正例并排除所有反例。 (2) 观察发现学习
它属于无师学习,其目标是确定一个定律或理论的一般性描述,刻画观察集,指定某类对象的性质。它分为观察学习与机器发现两种,前者用于对事例进行聚类,形成概念描述,后者用于发现规律,产生定律或规则。
6-7 试述解释学习的基本原理、学习形式和功能
解释学习(Explanation-Based Learning, 简称EBL)是一种分析学习方法,在领域知识指导下, 通过对单个问题求解实例的分析, 构造出求解过程的因果解释结构, 并获取控制知识,以便用于指导以后求解类似问题。
解释学习是把现有的不能用或不实用的知识转化为可用的形式,因此必须了解目标概念的初始描述。1986年米切尔(Mitchell)等人为基于解释的学习提出了一个统一的算法EBG,该算法建立了基于解释的概括过程,并运用知识的逻辑表示和演绎推理进行问题求解。
6-13 什么是知识发现?知识发现与数据挖掘有何关系?
根据费亚德的定义,数据库中的知识发现是从大量数据中辨识出有效的,新颖的,潜在有用的,并可被理解的模式的高级处理过程。
数据挖掘是知识发现中的一个步骤,它主要是利用某些特定的知识发现算法,在一定的运算效率内,从数据中发现出有关的知识。
6-14试说明知识发现的处理过程。
费亚德的知识发现过程包括 (1) 数据选择 根据用户需求从数据库中提取与知识发现相关的数据 (2) 数据预处理 检查数据的完整性与数据的一致性,对噪音数据进行处理,对丢失的数据利用统计方法进行填补,进行发掘数据库 (3) 数据变换 利用聚类分析和判别分析,从发掘数据库里选择数据 (4) 数据挖掘 (5) 知识评价 对所获得的规则进行价值评定,以决定所得到的规则是否存入基础知识库 知识发现的全过程,可进一步归纳为三个步骤,即数据挖掘预处理,数据挖掘,数据挖掘后处理。
6-15 有哪几种比较常用的知识发现方法?试略加介绍。
常用的知识发现方法有:
(1) 统计方法。统计方法是从事物外在数量上的表现去推断事物可能的规律性,包括传统方法,模糊集,支持向量机,粗糙集;
(2) 机器学习方法。包括规则归纳,决策树,范例推理,贝叶斯信念网络,科学发现,遗传算法;
(3) 神经计算方法。常用的有多层感知器,反向传播网络,自适应映射网络;
(4) 可视化方法。使用有效的可视化界面,可以快速,高效地与大量数据打交道,以发现其中隐藏的特征,关系,模式和趋势。