AI算法工程师 | 01人工智能基础-快速入门
文章目录
- 一、我们身处人工智能的时代
-
- 人工智能的时代
- 人工智能的应用
- 二、人工智能的流程和基本概念
-
- 人工智能常见流程
- 人工智能基本概念与区别
- 三、人工智能的常见任务和本质
-
- 有监督机器学习任务与本质
- 无监督机器学习任务与本质
一、我们身处人工智能的时代
人工智能的时代

互联网时代的发展
站在互联网的角度理解人工智能:人工智能AI(artificial intelligence)是互联网时代发展的必然趋势。
人们从早期做web开发,到移动端的开发;之后随着数据量的增大,人们开始研究高并发的问题;当数据量不断的增大,而人们希望数据不被浪费时,产生了大数据的技术,包括:大数据的如何存储以及大量数据的如何计算分析;由于计算分析和存储需要资源,互联网便发展到通过云计算进行存储与计算,包括虚拟化的计算,如:docker,k8s;再到后来,人们不是仅仅局限于将数据进行存储和简单分析,更多的是想从数据中挖掘出价值,人们便想到了人工智能,因为人工智能中有很多的算法,可以帮助人们从数据中挖掘出价值。
注意,区分大数据和人工智能的概念:
① 大数据:专注于已有的数据的存储和计算,生成分析报表;
② 人工智能:专注于利用已有数据挖掘规律,对未来进行预测。
人工智能领域的技术
在人工智能领域中,其技术的发展具体有如下内容:
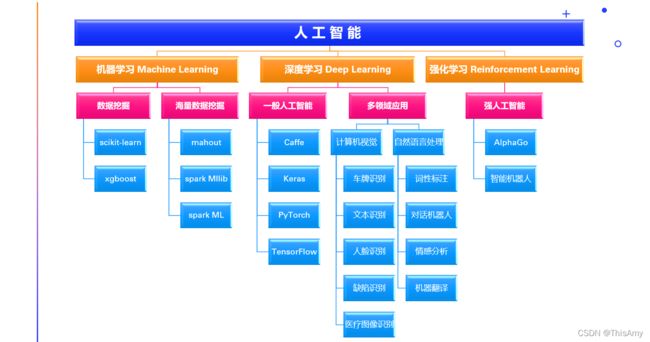
人工智能从早期的使用机器学习的算法来做数据挖掘,到分布式的进行数据挖掘;再到进一步的把算法研究得更加深入,走向了深度学习的领域,于是人们开始发现深度学习可以使更加复杂的问题(如:计算机视觉、自然语言处理)变得更加的准确,于是有了各种各样的应用;在人工智能发展过程中还存在强化学习,比如:利用强化学习的技术,在前几年有AlphaGo这样下围棋的机器人,近几年有各种各样的智能制造中使用到的机器人。这些都是应用人工智能产生的一些产业。
所以,人工智能是现在互联网中发展的一个大的趋势:如何更好的利用数据去挖掘数据中的价值,把挖掘到的数据的价值(规律)进行更好的应用,并对各行各业加以帮助。
人工智能的应用

人工智能已经逐步渗透到生产生活中的方方面面,无论是医疗、教育、交通、物流,还是传统生产制造、金融、农业设置是军事、游戏,人工智能的身影无处不在,并发挥着越来越重要的作用。


二、人工智能的流程和基本概念
人工智能常见流程
人工智能是拟人
灵魂三连问:
- 为什么说 “人工智能是拟人” ?因为人工智能的流程与思考的过程非常相像。
- 如何看现在的人工智能做得有多好?其越像人的思考过程,越和人的准确率接近,则该人工智能做得越好。
- 怎么理解人工智能是 “拟人” 这两个字?且看下文讲解 ↓↓↓
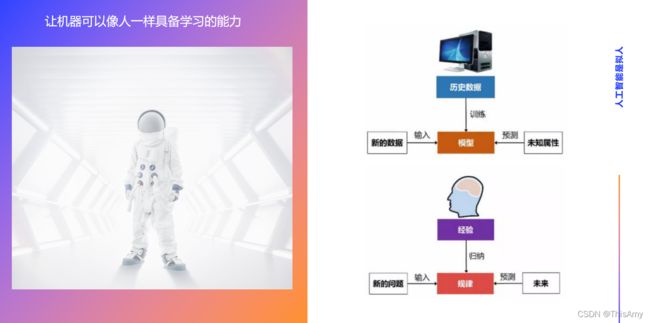
首先,需要理解的是何为人工智能?通俗来讲,人工智能就是让机器像人一样具备学习的能力。
其次,人工智能 AI 包含三大块内容,分别是:机器学习 ML(Machine Learning)、深度学习 DL(Deep Learning)、强化学习 RL(Reinforcement Learning)。
在早期的人工智能,人们会称为机器学习,是一些经典机器学习算法的统称。关于 “机器学习” ,可以用 “让机器像人一样具备学习的能力” 这句话来解释。但如何让机器像人一样具备学习的能力,做到人工智能呢?这需要先了解人类的思考过程。
- 人类的思考过程:人的大脑根据生活中的经验,归纳和总结出相对应的规律。这些规律可以使人们未来碰到新的问题时,能够将新的问题代入到脑海中,根据已有的规律来思考——当未来碰到该新问题时,应该给出什么样的预测结果,需进行怎样的决策。
- 人工智能流程对比人类思考的过程:
- 对于机器,它的大脑是计算能力(如CPU和内存,这些帮助机器来计算的,实际上就是它的大脑),而历史数据相当于人类的经验;
- 将数据交给计算机进行训练,训练的过程相当于像人一样归纳和总结相对应的规律;
- 在人工智能中,这些规律就是模型;
- 未来出现新的问题,即碰到新的数据,将新的数据代入到模型中去预测未知的属性,得到的结果便是预测值。
从中可以发现:这种对已有的数据进行训练得出某种模型,利用此模型预测结果的这一过程,与人类的思考过程非常类似。
人工智能的流程与本质

人工智能的流程:把数据代入到算法中,生成对应的模型,最终把模型上线,来进行预测。(即:数据预处理 → 算法求解 → 模型评估 → 模型上线)
人工智能的本质:把X、y代入公式中计算出参数(解方程组算出参数),当未来有新的X时,将其代入公式中得到预测的y(ŷ,叫做y hat)。
怎么才能猜的更准?“数据为王” 的思想。若拿到的历史数据,其数据质量越高,数据量越大,得到的参数就越可靠,于是通过该参数算出的值会越准确。
做工人智能的目的是——做预测;目标为——生成模型,而想要生成模型,需要数据和算法。
因此,对于人工智能来说,为了得到更好的模型结果,要不就是改算法(公式),要不就是找到更多等好的数据。
算法工程师:
① 核心任务是生成可以预测准确的模型
② 具备相关的代码能力
人工智能基本概念与区别
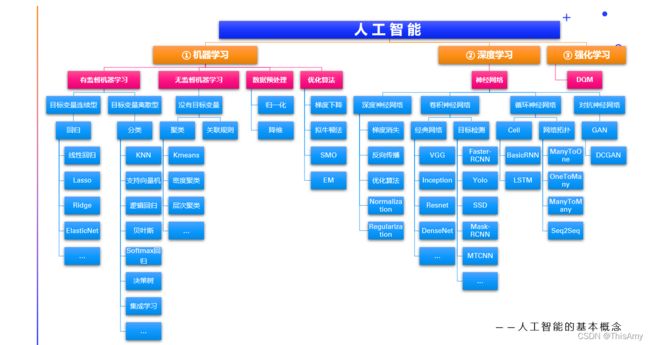
深度学习以前是机器学习的分支,因为深度学习是基于神经网络算法衍生出来的,由于近些年发展的很快,所有往往单独拎出来成为一门学科。
强化学习以前也只是机器学习的分支,随着现在深度强化学习(深度学习结合强化学习)的流行,也成为了一门学科,强化学习将来有望成为人工智能未来的明星。
机器学习不同的学习方式
人工智能中的核心是机器学习(Machine Learning,ML)。其原因是:机器学习研究的是各种各样的算法,算法是核心。
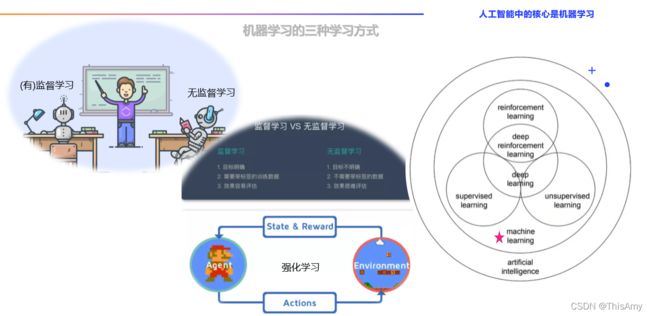
从学习方式上看,机器学习分为:有监督学习、无监督学习、强化学习
- 有监督学习(Supervised Learning, SL)
- 指原始数据中既有特征值也有标签值的机器学习
- 特点:① 目标明确 ② 需要带标签的训练数据 ③ 效果容易评估
- 无监督学习(Unsupervised Learning, UL)
- 其中没有需要预测或估计的目标变量(或标签值)
- 特点:① 目标不明确 ② 不需要带标签的训练数据 ③ 效果很难评估
- 强化学习(Reinforcement Learning, RL)
- 含义:让智能体与环境进行互动,不断学习以便调整策略的过程,这使智能体变得越来越聪明。
人工智能按照学习方式可分为:a. 有监督学习(数据集中有x和y)、b. 无监督学习(有x)、c. 半监督学习(有x和一部分y)、d. 强化学习(智能体与环境互动过程中产生数据,再代入算法中生成模型)。
深度学习比传统机器学习有优势
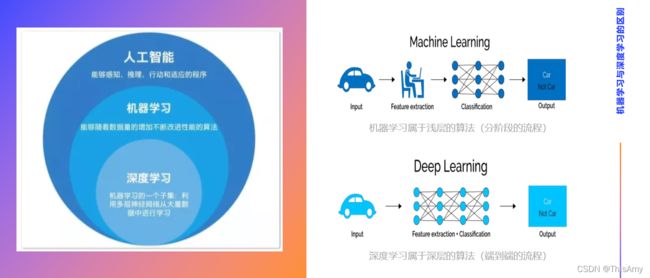
机器学习:人们更多的是把数据拿过来做特征的抽取(特征处理),这个过程更多的会有人为的参与,如:人为的选择用哪些算法,使用哪些数据做特征抽取。人为更多的参与预处理,将预处理后的数据交给后续的算法去生成算法中的参数。
机器学习和深度学习的区别:
① 机器学习属于浅层的算法(算法的公式不是特别复杂,更像分阶段的流程);
② 深度学习属于深层的算法(将提取特征的阶段放到整个神经网络中,更像端到端的流程)。
深度学习相比机器学习的优势:
① 是更端到端的学习方式;
② 由于网络层次更深,其可训练的参数更多(可以学习如何更好提取特征);
③ 可以解决更复杂的问题。
理解 —— 有多少人工就有多少智能(人工智能的本质)
- 机器学习:在特征工程中做的多好,最后的算法就能预测的有多准;
- 深度学习:设计的网络有多好,模型预测的就有多准确。
三、人工智能的常见任务和本质

有监督机器学习任务与本质
做人工智能时,首先要明确需求是什么?预测的东西是什么?即:先明确有哪些任务,再选择相对应的算法。
回归、分类、聚类、降维都是机器学习中具体的任务。其中,① 回归和分类属于有监督机器学习;② 聚类和降维属于无监督机器学习。
回归 Regression
- 本质:拟合历史已有的数据,根据拟合出来的函数走势预测未来
- 目标:预测-inf 到+inf 之间具体的值,连续值
- 应用:股票预测(如:股票值的预测)、房价预测
分类 Classification
- 本质:找到分界,根据分界对新来的数据进行分类
- 目标:对新的数据预测出是各个类别的概率,正确的类别概率越大越好,最后通过选择概率最大的类别为最终类别,类别号 label 是离散值
- 应用:图像识别(如:识别该人是否戴安全帽)、情感分析(如:分析是正面情感还是负面情感)、银行风控(如:预测该人可承受怎样的风险,推荐不同的理财产品)
总结:
① 回归是做拟合,分类是找分界对应的超平面(通常超平面指:点、线、面)。
② 回归(连续型)和分类(离散型):有监督机器学习。具体看预测的值是离散型的还是连续型的,对应不同的分类。
③ 注意:股票预测中,若要预测未来某股票是会涨还是跌—— 分类任务,则需找分类所对应的算法去求相对应的分界线/面。
无监督机器学习任务与本质
无监督机器学习问题主要有两种:聚类、降维
聚类 Clustering
- 本质:根据样本和样本之间的相似度归堆
- 目标:将一批数据划分到多个组
- 应用:用户分组、异常检测、前景背景分离
降维 Dimensionality Reduction
- 本质:去掉冗余信息量或噪声
- 目标:将数据的维度减少
- 应用:数据的预处理、可视化、提高模型计算速度
总结:
① 聚类就是分组(归堆);降维类似于换个角度去审视原来的数据。
② 由于维度越多,速度越慢。所以,为提高模型运行速度,通常会做降维的任务。