【编程生活】python实现成绩可视化数据分析
考试成绩可视化分析软件
- 0. 这个软件是做什么的呢?
-
- 设计这个软件的初衷
- 软件要实现的功能
- 1.功能实现
-
- 输入成绩并输出可视化结果
-
- 1. 输入成绩
-
- 1.1 读入数据的类别与小项:
- 1.2 输入成绩:
- 2. 输出记录并输出可视化视图
-
- 2.1 输出成绩记录
- 2.2 输出可视化视图
- 对多次考试的数据进行可视化分析
-
- 1. 对多次的log进行数据读取和分析
- 2.总结和改进方向
-
- 总结
- 程序的不足
- 改进方向
- 完整代码
0. 这个软件是做什么的呢?
设计这个软件的初衷
熟悉我的朋友都很清楚,我做的很多小软件其实都是用来解决我生活中遇到的实际问题的。这一次也一样,我在2021年参加了JLPT日语能力考试,这个软件便是用于我这一次考试的备考的。
同时,这个代码也可以用来练习数据可视化,记录数据并绘制折线图等功能在深度学习(绘制loss和acc等数据曲线),后端分析(访问量,网速等数据曲线绘制)等都有很大用处。现在实现这个代码不但可以用来用作我个人的成绩分析,还可以用于练习这一领域的代码实现。
软件要实现的功能
- 对用户输入的单次测试的各题型成绩进行可视化,帮助用户了解自己在考试中的优势部分和不足部分。
- 对多次考试成绩进行可视化分析,帮助用户针对性制定复习计划。
1.功能实现
本软件主要使用的第三方依赖库是matplotlib,本文将以JLPT模拟测试作为使用情景,应对不同的数据分析情节请灵活更改后使用!
输入成绩并输出可视化结果
1. 输入成绩
1.1 读入数据的类别与小项:
由于试题类别是相对固定的信息,因此可以提前准备好,在本程序中我使用了一个外部txt进行信息读取,格式为如图:

图片内的信息将被自动读取出类别和小项,实现代码如下:
def ReadPart(path):
with open(path,encoding='utf-8') as txt_r:
txt = txt_r.readlines()
classes = []
for line in txt:
MessLine = line.replace('\n','').split(':')
classes.append(MessLine)
return classes
1.2 输入成绩:
程序会读取上述的txt,随后要求用户输入数据,并通过python中的dict类型将数据进行规整并返回类别名和数据,代码如下:
def GetMess(parts):
PartTitle = parts[0]
kinds = parts[1].split(',')
print("现在输入{}部分成绩".format(PartTitle))
print("="*30)
ThisPart = {}
for part in kinds:
s_input = input("请输入{}部分成绩,格式为:正确数,总数 ".format(part))
s = s_input.replace(',','/')
ThisPart[part] = s
return PartTitle,(ThisPart)
返回的数据同样也装载入命名为TotalMess的Dict之中,即所有数据输入完毕后的数据将为:
['类别'1:['小项1-1','小项1-2'],'类别2'['小项2-1','小项2-2'],'类别3['小项3-1','小项3-2']']
2. 输出记录并输出可视化视图
2.1 输出成绩记录
在上面的步骤中我们已经完成了对数据的整理,对于已经完成规整的数据对其进行格式化的输出就是非常简单的了,这里用一个WriteLog方法进行写入:
所有数据收集完毕后就可以对数据进行规整并写出数据记录,代码如下:
def WriteLog(Title,Mess):
WritingPaper = []
for kind in Mess:
WritingPaper.append("{}: \n{}\n".format(kind,'+'*15))
for part in Mess[kind]:
line = " {}:{}\n".format(part,Mess[kind][part])
WritingPaper.append(line)
WritingPaper.append("{}\n".format("="*30))
save_dir = "{}/logs/{}".format(os.getcwd(),Title)
os.mkdir(save_dir)
TxtPath = "{}/logs/{}/{}.txt".format(os.getcwd(),Title,Title)
txtw = open(TxtPath,'w')
for wline in WritingPaper:
txtw.write(wline)
txtw.close()
shutil.copy("{}/logs/parts.txt".format(os.getcwd()),save_dir)
print("记录已完成")
return TxtPath, save_dir+'/'
现在我们已经完成了log文档的写入,可以注意到在上面的代码中有一个copy的代码,这是考虑到题型可能会出现变化,因此要把类别也记录下来。
自动写入的log格式如下,后续的可视化代码如果您有自己的代码可以直接根据这个这个格式设置分割后直接替换。
文字:
+++++++++++++++
音转汉:2/5
汉转音:4/5
汉字使用:2/3
近义词:5/7
词语解释:3/5
词语使用:4/5
==============================
文法:
+++++++++++++++
选词填空:7/12
排词造句:2/5
完形:4/4
==============================
读解:
+++++++++++++++
片段:2/5
中篇:9/9
双段:2/2
长篇:1/3
信息检索:2/2
==============================
听解:
+++++++++++++++
信息接收:1/5
信息获取:5/5
无印接收:1/5
无印应答:10/11
无印篇章:2/3
==============================
2.2 输出可视化视图
本代码中使用的是一个彩色条形图,不同的颜色代表不同的大类。这一部分我将其封装为了一个类,其思想是对上一步输出的log进行读取,然后通过matplotlib以来哭进行绘图,具体代码如下:
class Ana:
def __init__(self,txt):
self.txt = txt
def TxT2Arr(self):
paper = ""
data = {}
for line in self.txt:
paper += line
Pmess = paper.split("="*30)
del Pmess[-1]
for part in Pmess:
mess = part.split('+'*15)
Ptitle = mess[0].replace(' ','').replace("""\r""","").replace(':','')
sorce = mess[1].replace(' ','').split('''\n''')
del sorce[0]
del sorce[-1]
data[Ptitle] = sorce
return data
def draw(self,path,colors):
data = self.TxT2Arr()
x_lines = []
y_lines = []
titles = []
kinds = []
for kind in data:
kinds.append(kind)
topices = data[kind]
x_line = []
y_line = []
title = []
for topic in topices:
mess = topic.split(':')
name = ""
time = 0
for w in mess[0]:
time+=1
name+=w
if(time>=2):
time = 0
name += '''\n'''
x_line.append(name)
title.append(mess[1])
score = int(mess[1].split('/')[0])/int(mess[1].split('/')[1])
y_line.append(score)
x_lines.append(x_line)
y_lines.append(y_line)
titles.append(title)
assert (len(x_lines) == len(y_lines))
plt.figure(dpi=1024)
for n in range(len(x_lines)):
x = x_lines[n]
y = y_lines[n]
title = titles[n]
plt.bar(x,y,fc=colors[n],align='center',label=kinds[n].replace('''\n''',''))
time = 0
for a, b in zip(x, y):
plt.text(a, b + 0.005, "{}".format(title[time]), ha='center', va='bottom', fontsize=10)
time += 1
plt.legend(loc = 'best')
plt.title("Question type correct rate")
plt.xticks(fontsize=6)
# for a, b in zip(x_line, y_line):
# plt.text(a, b + 0.005, "{}".format(titles[time]), ha='center', va='bottom', fontsize=10)
# time += 1
plt.savefig("{}Question type correct rate.png".format(path))
# plt.show()
以上的代码是从log中读取内容的,这是为了类本身可以和上一部的代码保持一个相对的独立性,以便可以单独摘取使用某一个功能使用和改编。
上面的成绩数据的可视化效果如下:
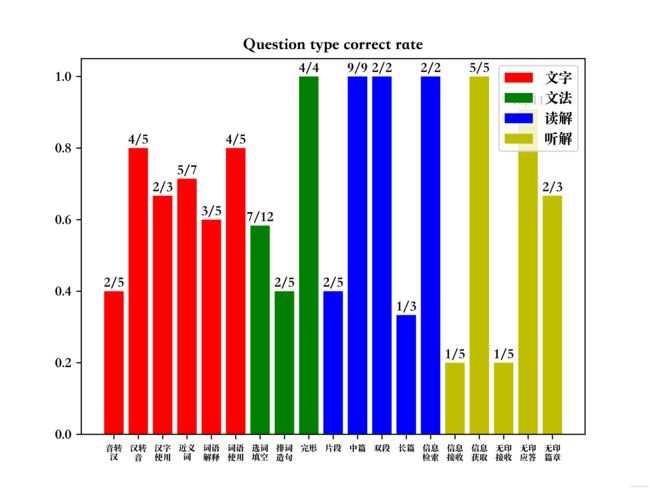
对多次考试的数据进行可视化分析
1. 对多次的log进行数据读取和分析
这部分代码需与上面的代码配合使用,如果需要配合其他代码或数据请修改读取逻辑!
首先,我们要先整理好我们需要分析哪几次考试,我在demo中抽取了6次模拟考的成绩进行分析,这一部分只需要应用一个预设好的list和一个for循环就可以实现(这个list可以改成外部传参实现交互甚至GUI)
WaitingLogs = ['201007','201307','201312','201907','201912','202012']#需要分析的试卷名
Num = []
for log in WaitingLogs:
txt_path = ("{}/{}/{}.txt".format(log_path,log,log))
txt = ReadTxt(txt_path)
TxtMess = Ana(txt).TxT2Arr()
datas, Totles = MessPacket2Total(TxtMess)
for n,k in enumerate(DataBase):
if(len(DataBase) - n < 2):
DataBase[k].append(Totles)
else:
DataBase[k].append(datas[n])
随后,程序将读取预设的所有log,并算出每个大类的总正确率,随后将成绩按大类归档如Dict中,代码如下:
def MessPacket2Total(packet):
totles = []
nums = []
for kind in packet:
datas = packet[kind]
NumC,NumT = [],[]
for data in datas:
m = data.split(':')[-1]
NumC.append(m.split('/')[0])
NumT.append(m.split('/')[1])
NumC = [int(i) for i in NumC]
NumT = [int(i) for i in NumT]
nums.append(sum(NumC)/sum(NumT))
totles.append(sum(nums)/4)
return nums,totles
在这个MessPacket2Total方法中,返回值nums为整理出来的单次测试的大类平均数据(demo中为四个大类),totles(没错这个变量名我拼错了= =)则是“总成绩”大类。
通过for循环对所有预备好的log数据进行解析之后,我们得到了一个总表,随后只需要将总表绘制成折线图就可以了,这里我用了一个DrawLineChart方法进行实现,代码如下:
def DrawLineChart(Data,Titles):
colors = ['r', 'g', 'b', 'y','m']
plt.figure(dpi=1024)
for n, name in enumerate(Data):
plt.plot(Titles,Data[name],label=name,color=colors[n])
plt.legend(loc='best')
plt.savefig("{}/logs/{}-{}Changes.png".format(os.getcwd(),Titles[0],Titles[-1]))
现在我们的趋势图已经绘制完成了,让我们看看效果

可以看到各项的变化被非常清晰的表达出来了,对着这样一张图进行针对性复习是非常有效的,至少我就通过这个程序的决策辅助考过了JLPT N2并成功拿到资格证啦~~
2.总结和改进方向
总结
- 本代码对于自用而言是满足需求的,是一个从需求出发制作的软件,很好的锻炼了我的软件设计能力。
- 代码虽然是用于考试成绩分析,但实际上里面的很多方法可以稍作修改后就用于深度学习的loss绘图,数据库应用中的大数据可视化等,可以作为代码储备。
- 学习了matplotlib依赖库的使用。
程序的不足
- 没有GUI和封装,必须要有开发环境和一定的开发素养才能使用本代码。
- 代码泛用性不足,写死了颜色类型的数量,变相限制了大类的数量。
改进方向
- 对程序进行封装,最好是做成一个web程序。
- 目前log和图片分开的输出方式对于非开发人群而言有点不友好,完全可以输出为一份PDF报告。
完整代码
GitHub链接:点击此处
如果有需求希望我帮忙定制一个基于这个程序的GUI分析软件或是其他定制需求的朋友可以发邮件至[email protected]联系,我可以有偿帮您开发
感谢观看,愿你平安~!