决策树之C4.5算法
1. 采用信息增益率
因为 ID3 在计算的时候,倾向于选择取值多的属性。为了避免这个问题,C4.5 采用信息增益率的方式来选择属性。信息增益率 = 信息增益 / 属性熵,具体的计算公式这里省略。当属性有很多值的时候,相当于被划分成了许多份,虽然信息增益变大了,但是对于 C4.5 来说,属性熵也会变大,所以整体的信息增益率并不大。
2. 采用悲观剪枝
ID3 构造决策树的时候,容易产生过拟合的情况。在 C4.5 中,会在决策树构造之后采用悲观剪枝(PEP),这样可以提升决策树的泛化能力。
悲观剪枝是后剪枝技术中的一种,通过递归估算每个内部节点的分类错误率,比较剪枝前后这个节点的分类错误率来决定是否对其进行剪枝。这种剪枝方法不再需要一个单独的测试数据集。
3. 离散化处理连续属性
C4.5 可以处理连续属性的情况,对连续的属性进行离散化的处理。比如打篮球存在的“湿度”属性,不按照“高、中”划分,而是按照湿度值进行计算,那么湿度取什么值都有可能。该怎么选择这个阈值呢,C4.5 选择具有最高信息增益的划分所对应的阈值。
4. 处理缺失值
针对数据集不完整的情况,C4.5 也可以进行处理。假如我们得到的是如下的数据,你会发现这个数据中存在两点问题。第一个问题是,数据集中存在数值缺失的情况,如何进行属性选择?第二个问题是,假设已经做了属性划分,但是样本在这个属性上有缺失值,该如何对样本进行划分?
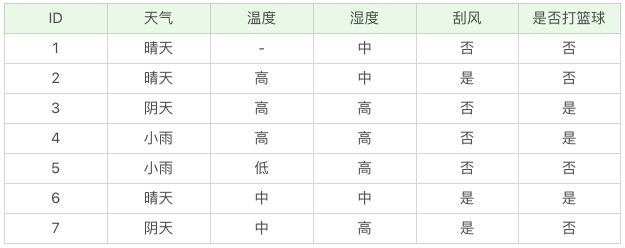
我们不考虑缺失的数值,可以得到温度 D={2-,3+,4+,5-,6+,7-}。温度 = 高:D1={2-,3+,4+} ;温度 = 中:D2={6+,7-};温度 = 低:D3={5-} 。这里 + 号代表打篮球,- 号代表不打篮球。比如 ID=2 时,决策是不打篮球,我们可以记录为 2-。
针对将属性选择为温度的信息增益为:
Gain(D′, 温度)=Ent(D′)-0.792=1.0-0.792=0.208,
属性熵 =-3/6log3/6 - 1/6log1/6 - 2/6log2/6 = 1.459,
信息增益率 Gain_ratio(D′, 温度)=0.208/1.459=0.1426。
D′的样本个数为 6,而 D 的样本个数为 7,所以所占权重比例为 6/7,所以 Gain(D′,温度) 所占权重比例为 6/7,所以:Gain_ratio(D, 温度)=6/7*0.1426=0.122。这样即使在温度属性的数值有缺失的情况下,我们依然可以计算信息增益,并对属性进行选择。
ID3 算法的优点是方法简单,缺点是对噪声敏感。训练数据如果有少量错误,可能会产生决策树分类错误。
C4.5 在 ID3 的基础上,用信息增益率代替了信息增益,解决了噪声敏感的问题,并且可以对构造树进行剪枝、处理连续数值以及数值缺失等情况,但是由于 C4.5 需要对数据集进行多次扫描,算法效率相对较低。
在决策树的构造中,一个决策树包括根节点、子节点、叶子节点。在属性选择的标准上,度量方法包括了信息增益和信息增益率。ID3 是基础的决策树算法,C4.5 在它的基础上进行了改进,也是目前决策树中应用广泛的算法。