opencv yuv保存本地_opencv 读取 普通视频、以YUV数据格式保存的视频 以及 图片序列的方法...
在刚入门opencv的阶段,读取图片以及视频是作为初学者最需要掌握的方法。最近在上智能视频分析这门课程,通过几次实验课,发现针对不同的数据分别对应着不同的载入方式,特此开贴,记录下来,一是可以与人分享,共同进步,二是权当学习笔记记录下来,以供以后回顾。若有谬误,还望各位大佬指正,定不胜感激!!!
一.普通视频的载入方式
这个是入门级的教程,就不多说了。主要是先定义 VedioCapture 这个类,在将视频的每一帧都赋值给一张图片。对视频的处理,就是对每一帧图片循环处理,接处理后的图片显示出来。图像处理是单幅图,视频处理就是多幅图的处理。
#include #include #include using namespace cv;
using namespace std;
int main()
{
Mat img;
VideoCapture cap(0); // 打开电脑摄像头 创建 cap
//VideoCapture cap("1.avi"); // 打开 “1.avi”文件 创建cap
if (!cap.isOpened())
{
cout << "cannot open camera" << endl;
return 0;
}
while (true)
{
cap >> img; //将视视频的每一帧图片赋值给 img
///
// 可以在此处编写对 img 进行各种图像处理的代码
//
///
imshow("image", img);
char key = waitKey(30);
if (key == 27)// 按键“ESC”退出
break;
}
return 0;
}
效果图如下:

二. 读取以YUV形式保存的视频文件,并将其转为RGB图片,然后显示
首先先简单介绍下YUV数据数据格式。YUV,分为三个分量,“Y”表示明亮度(Luminance或Luma),也就是灰度值;而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
YUV码流的存储格式其实与其采样的方式密切相关,主流的采样方式有三种,YUV4:4:4,YUV4:2:2,YUV4:2:0,关于其详细原理,可以通过网上其它文章了解,这里我想强调的是如何根据其采样格式来从码流中还原每个像素点的YUV值,因为只有正确地还原了每个像素点的YUV值,才能通过YUV与RGB的转换公式提取出每个像素点的RGB值,然后显示出来。
用三个图来直观地表示采集的方式吧,以黑点表示采样该像素点的Y分量,以空心圆圈表示采用该像素点的UV分量。

先记住下面这段话,以后提取每个像素的YUV分量会用到
1.YUV 4:4:4采样,每一个Y对应一组UV分量。
2.YUV 4:2:2采样,每两个Y共用一组UV分量。
3.YUV 4:2:0采样,每四个Y共用一组UV分量。
个人觉得YUV格式主要的优点就是可以压缩图片的数据量,节省内存。可能对单幅图来说节省的内存不是很多,但是对于一段视频来说,省下的内存就是很大了。
下面就以一副RGB24图片为例,如果将其以RGB形式保存的话,需要的size=width*height*3bit . 若是以YUV420保存的话,size=width*height*1.5bit 。
对于一副8*4的图片来说,size=width*height+1/2 *width*height=3/2*width*height=3/2*8*4
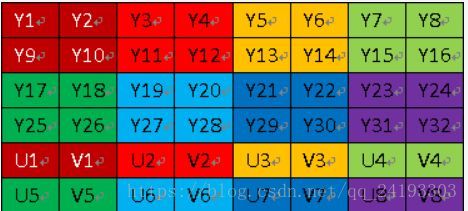
不过缺点就是在将YUV420数据转换为RGB时,会出现图像像素点信息的丢失,不能完全复现出原图。(YUV444可以完全复现,但是数据不会被压缩)
具体代码如下:
#include #include #include #include #include #include #include using namespace std;
using namespace cv;
const int width = 352;
const int height = 288;
const int framesize = width * height * 3 / 2; //一副图所含的像素个数
typedef struct planet
{
char name[framesize];
double population;
double g;
} PLANET;
int main()
{
/
// 计算视频的帧数,怎样替换成c语言形式的?
PLANET pl;
ifstream fin;
fin.open("hall_cif.yuv", ios_base::in | ios_base::binary);
if (fin.fail())
{
cout << "the file is error" << endl;
return -1;
}
fin.seekg(0, ios::end); //设置文件指针到文件流的尾部
streampos ps = fin.tellg(); //指出当前的文件指针
unsigned long NumberPixe = ps;
cout << "file size: " << ps << endl; //输出指针的位置
unsigned FrameCount = ps / framesize; //帧大小
cout << "frameNuber: " << FrameCount; //输出帧数
fin.close();
/
PtrpBgmodel = createBackgroundSubtractorMOG2();
pBgmodel->setVarThreshold(20);
FILE* fileIn = fopen("hall_cif.yuv", "rb+");
unsigned char* pYuvBuf = new unsigned char[framesize]; //一帧数据大小
//存储到图像
namedWindow("yuv", 1);
for (int i = 0; i < FrameCount; ++i)
{
//从数据流中读取 按长度读取数据 下一次循环直接从上一帧的末尾开始读取
fread(pYuvBuf, framesize*sizeof(unsigned char), 1, fileIn); //在整个yuv中截取一帧图像读入
Mat yuvImg;
yuvImg.create(height * 3 / 2, width, CV_8UC1); //创建新的图片的大小
memcpy(yuvImg.data, pYuvBuf, framesize*sizeof(unsigned char));
Mat rgbImg;
cvtColor(yuvImg, rgbImg, CV_YUV2BGR_I420);
char key = waitKey(100);
if (key == 27)// 按键“ESC”退出
break;
imshow("yuv", yuvImg); //只显示y分量
imshow("rgbImg", rgbImg);
printf("第 %d 帧\n", i);
}
fclose(fileIn);
cvDestroyWindow("yuv");
cin.get();
cin.get();
return 0;
}
实验效果图:

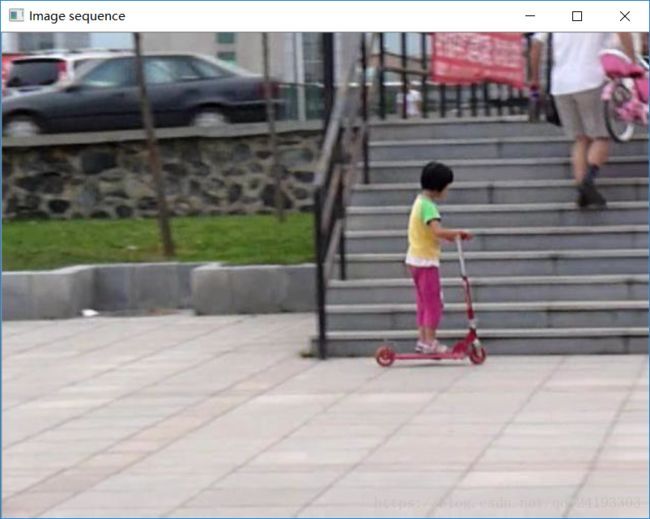
三.读取图片序列
图片序列的格式:

图片的 文件名为 000000xx 所以宽度为8
VideoCapture 的功能真的很强大啊,可以读视频,可以读图片序列
#include #include using namespace cv;
using namespace std;
int main()
{
string first_file = "girl/%8d.jpg"; //%8d代表文件名的宽度 将宽度为8的文件名都读出来
VideoCapture sequence(first_file); // V
Mat image;
namedWindow("Image sequence");
while (1){
sequence >> image;
if (image.empty()) break;
imshow("Image sequence", image);
char key=waitKey(5);//每隔5毫秒再读下一幅图像
if (key == 27)// 按键“ESC”退出
break;
}
cout << "End of Sequence" << endl;
waitKey();
return 0;
}
实验结果: