强化学习,商业化之路宣告死亡了吗?
文 | Shona
继DeepMind推出AlphaGo已过去7年,强化学习在游戏行业有了不少应用,例如游戏陪玩、AI托管等。
在这过程中,越来越多的公司 / 研究院所为强化学习的研究投入了大量的资源与精力。随之而来的,也有不少质疑,不少人对强化学习的印象还仅仅停留在游戏层面,认为它落地到其他行业是非常之困难的。
到目前为止,我们回顾自热潮掀起,再到质疑声频出,强化学习是否真的挺进各行各业?它创造商业价值了吗?
换句话说,强化学习的商业化之路,是否已宣告死亡?
前不久,这件事情在国外引起了热议。

一位在国外任职“数据科学家”的网友提出,在真实的工业界场景中,似乎很少见到像游戏这样的可以轻松建立agent模拟环境的场景,而一个理想的模拟环境对训练RL来说是非常重要的。商业场景中,应用RL是非常不切实际的。
在实际的工业界场景中,人们通常认为训练强化学习模型会遇到以下几个问题:
1)采样效率低: 强化学习的agent与环境的交互有限,没有办法采样足够多的数据,部分场景常常只能收集一些重复无用的数据。
2)试错成本高: 除了游戏AI行业这类试错成本比较低的行业,在某些领域中,试错成本较高成为强化学习发展的瓶颈。例如,医疗行业、无人驾驶。应用模拟仿真解决问题又会带来数据一致性的挑战。
3)巨大的动作空间: 例如推荐系统存在成千上万的item,电商行业有大量的商品需要推荐,强化学习需要针对各个action做非常充足的探索,此时强化学习的落地需要结合业务背景,如何抽象出强化学习相关的问题显得非常重要。比如,把单个商品或者单个用户当做action可能会有点不切实际,使用用户群体、商品类型的话action space会小很多。
但仅仅靠这几点又不足以说明没有适合RL的商业场景。
帖子的讨论区里,有一些网友试图列举当前RL在商业上成功落地的场景。
1. 网站优化

比如这位网友提到强化学习中经典的MAB(multi-arm bandit)模型可以用于网站优化,并且楼中楼提供了一些现成可用工具,比如Vowpal Wabbit。
2. 推荐系统
强化学习在推荐系统已落地使用的应用较多,其长期价值建模能力、探索能力都让它有足够的优势促进人均时长、商业收入等推荐领域核心指标的提升。不管是在内容推荐上,还是涉及商业化的多介质混排上,强化学习都能出一份力。YouTube、阿里、腾讯、京东、快手等都落地了强化学习推荐算法,其中,实现相对简单,对线上损失小的offline RL应用比online RL更多。
我们知道传统的推荐系统可以看作一个单点预测,即基于用户特征(包含上下文)从海量的候选池中检索出少量的内容,用户对推荐系统的每次请求看作一个独立的过程。强化学习则将整个用户生命周期作为建模的对象,用户整个行为过程视为一个马尔可夫决策过程,从而在一定程度上更能考虑在上下文中的行为对用户心智的影响。
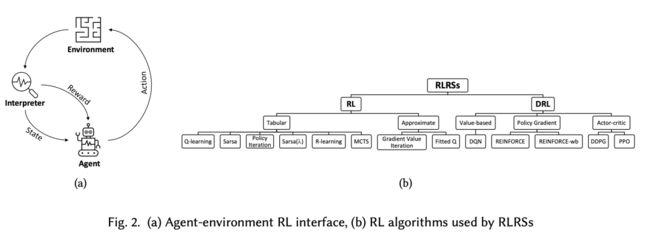
强化学习可以应用在推荐系统的召回、精排、重排的全链路阶段。例如,Youtube的Top-K RL算法通过sample softmax、校准数据权重等方式解决了动作空间过大、在线离线样本分布不一致等问题,提供了强化学习在召回领域的新视角。快手提出了基于强化学习的序列化排序框架,将输出 N 个视频序列的任务建模为 N 次决策过程,依次从候选集中挑选出 N 个视频,完成端到端的排序过程。微信看一看也应用强化学习预测每个内容出现的位置。其中,在重排阶段的落地更多一点,可以更灵活地定义reward,比如,时长、收入、多样性、惊喜度等。
进一步地,如果最大限度地提高混排模型的实时性,强化学习模型也能在手机端通过实时捕捉用户行为进行内容筛选,更有效且更精准地推荐。端重排技术目前在快手、淘宝都有落地。
笔者拿自己用强化学习在推荐领域落地的经验来说,起初一直把强化学习框架的搭建当做一件很复杂的事情(因为太想一步到位),不过还是慢慢调整了思路和心态。为了建模用户更长程的收益,选择了使用RL,但应用到整个序列生成是困难的,只用在多目标融合上行不行?online的框架需要架构和资源支持,降本增效的场景下,我用offline RL可不可以?offline RL的外推误差很严重,Q值总是被过估计,那还可以补充约束,比如BCQ, CQL, IQL等。
3. 控制问题&机器人

RL在这个领域的应用潜力也得到了楼中楼若干网友的肯定。
说到机器人,就不得不提明星公司“波士顿动力”了,他家经常因为惊艳的demo视频吸引大众的眼球,但不得不说....商业化之路看起来并不明朗。
潜力是一方面,真正的商业化落地又是另一方面了。
4. 组合优化问题&NP-hard问题
这个场景还是让读者感到有些耳目一新的。但也有网友指出,对于“旅行商问题”这种已经被求解的比较好的组合优化问题,RL可能不太占优势,很可能不如线性规划好使。
楼中楼网友进一步补充了RL求解组合优化问题的优势:

即:
1. RL求解可能比线性规划快得多
2. RL往往可以扩展到更大规模的场景
3. RL对于新问题有更强的解决能力
除此之外,还有网友指出一些research topic也可以用RL求解。
但不得不说,除了推荐这个场景以外,其他几个场景的商业价值只能说“想像力有限”。
笔者这里也补充几个工业界应用RL解决问题的例子,这几个场景也是相对来说有较大商业价值的。
广告行业: 在广告场景中的应用与推荐类似,阿里、京东等都落地了基于强化学习的流量预估与分配、实时竞价等算法。
芯片行业: 谷歌利用基于强化学习的方案,6小时即可完成芯片布局的设计,能力超过人类。论文被刊登在Nature,成为首个具有泛化能力的芯片布局方法,轰动业界。

自动驾驶: 运动规划是无人驾驶系统的核心模块之一,但由于自动驾驶场景的复杂性与不确定性,常规算法的迭代效率较低。强化学习在解决时序性决策问题方面的优势与智能驾驶的决策过程非常契合。Waymo的ChauffeurNet强化学习自动驾驶模型成功应用于实车的模仿学习,实现了可以在一个没有其他车辆、行人的乡村环境中安全巡航的实车驾驶系统。百度 Apollo 也基于动力学仿真落地了强化学习决策算法。
当然,引入强化学习或其他智能算法后,如何提高自动驾驶系统安全性与稳定性依然是悬而未决的问题,但起码辅助驾驶强化学习还是可以帮上忙的~
其他行业,比如化学分子逆合成和新药设计,DeepMimic运动机器人,对话系统,也都能找到强化学习算法的身影。
 ▲图片来自网络
▲图片来自网络
想了解RL更多应用场景的小伙伴,可以看这位网友贴的一本书:
工业界应用:
传送门:
https://rl-book.com/applications/
从以上列举的诸多RL落地场景来看,强化学习还是一个成长中的领域,大部分前沿方法和实际落地还相差较远,能撑起商业想象空间的场景更是乏善可陈,但在一些问题契合的场景,RL创造了一些价值。
如今,距离AlphaGO诞生已经7年了,人们和资本对于RL的热情已经褪去了不少。尽管这些年学术界和工业界都付出了巨大的努力,但RL的商业化却似乎总让人觉得差点意思。
强化学习的商业化之路,未来还会有更大的想象空间吗?
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群