【学习率】torch.optim.lr_scheduler学习率10种调整方法整理
学习率是网络训练过程中非常重要的参数,好的学习率可加速模型,并且避免局部最优解,这几天陷入了怪圈,被学习率折磨了,遂记录一下lr_scheduler中的学习率调整方法。
学习率调整在网络中的位置以及当前学习率查看方法
import torch
import torch.nn as nn
import torch.optim
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9,
weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, 20, eta_min=0, last_epoch=-1)
for epoch in range(100):
now_lr = optimizer.state_dict()['param_groups'][0]['lr'] # 当前学习率查看
train(...)
test(...)
scheduler.step() # 学习率更新
1. LambdaLR()
LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
(1)学习率调整为:初始lr乘以给定函数。
(2)通用参数:
[1] optimizer:优化器;
[2] last_epoch:默认为-1,学习率设置为初始值;
[3] verbose:默认为False,若为True,则每次学习率更新打印信息;
(3)参数:
[1] lr_lambda:给定函数;
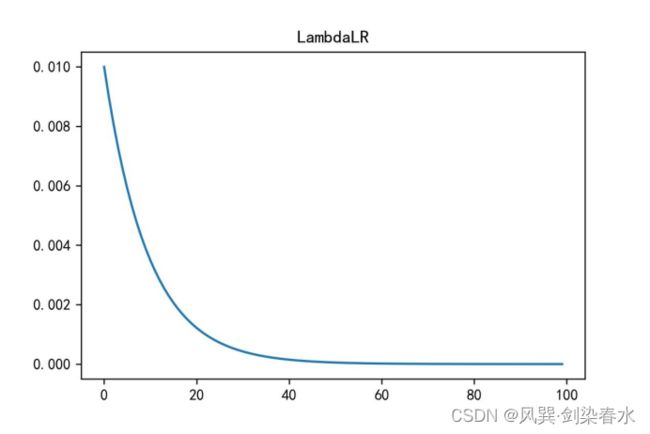
import torch
import torch.nn as nn
import torch.optim
import matplotlib.pyplot as plt
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.01, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
lambda1 = lambda epoch: 0.9 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('LambdaLR')
2. MultiplicativeLR()
MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
(1)学习率调整为:当前lr乘以给定函数。
(2)参数:
[1] lr_lambda:给定函数;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.01, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
lambda1 = lambda epoch: 0.9 ** epoch
scheduler = torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda=lambda1)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('MultiplicativeLR')

3. StepLR()
StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
(1)学习率调整为:以固定间隔成倍衰减初始学习率。
(2)参数:
[1] step_size:固定间隔;
[2] gamma:衰减倍数;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.1)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('StepLR')

4. MultiStepLR()
MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1, verbose=False)
(1)学习率调整为:以设置的间隔成倍衰减初始学习率。
(2)参数:
[1] milestones:设置间隔的索引,必须是递增的;
[2] gamma:衰减倍数;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[40, 70], gamma=0.5)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('MultiStepLR')

5. ExponentialLR()
ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
(1)学习率调整为:指数衰减初始学习率。(lr = lr * gamma**epoch)
(2)参数:
[1] gamma:指数衰减的底数;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.5)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('ExponentialLR')

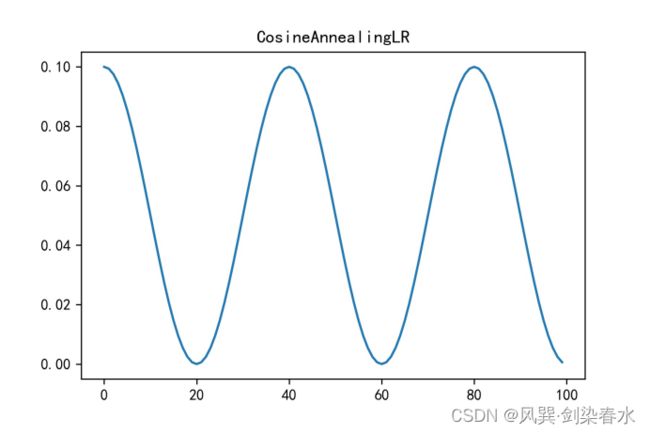
6. CosineAnnealingLR()
CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
(1)学习率调整为:余弦函数式变化,最高点为初始lr,最低点为eta_min,半周期为T_max。
(2)参数:
[1] T_max:余弦函数学习率调整的半周期;
[2] eta_min:默认为0,最小学习率;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('CosineAnnealingLR')
7. ReduceLROnPlateau()
ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, threshold=1e-4, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-8, verbose=False)
(1)学习率调整为:当某一指标不再提升时,降低学习率。
(2)参数:
[1] mode:模式选择,min为指标不再降低,如loss,max为指标不再升高,如准确率;
[2] factor:学习率衰减因子:new_lr = lr * factor;
[3] patience:容忍度,最多可以多少个epoch没有学习率变化;
[4] threshold:阈值,用来关注显著变化;
[5] threshold_mode:阈值模式,有rel和abs两种;
若为rel,
mode=max,则dynamic_threshold=best * ( 1 + threshold )
mode=min,则dynamic_threshold=best * ( 1 - threshold )
若为abs,
mode=max,则dynamic_threshold = best + threshold
mode=min,则dynamic_threshold=best - threshold
[6] cooldown:冷却时间,当调整学习率之后,等多少个epoch,再重启监测模式;
[7] min_lr:学习率下限,可为float或list,当有多个参数组时,可用list进行设置;
[8] eps:学习率最小衰减值,当学习率变化小于eps时,则不调整学习率;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
val_loss = 0.9
y.append(lr)
scheduler.step(val_loss)
plt.figure(dpi=300)
plt.plot(y)
plt.title('ReduceLROnPlateau')

8. CyclicLR()
CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode=‘triangular’, gamma=1., scale_fn=None, scale_mode=‘cycle’, cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1, verbose=False)
(1)学习率调整为:周期调整学习率,按iteration周期调整而不是epoch,iteration为在一个epoch中,根据batch_size的大小,学习率会更新的次数。
(2)参数:
[1] base_lr:初始学习率,学习率调整的下界;
[2] max_lr:每个周期中,学习率调整的上界,即周期振幅为(max_lr - base_lr);
[3] step_size_up:在递增的半周期内的训练迭代次数;
[4] step_size_down:在递减的半周期内的训练迭代次数;
[5] mode:模式,有{triangle, triangular2, exp_range}三种;
triangle:没有振幅缩放的基本三角形循环
triangular2:一个基本的三角形周期,每个周期将初始振幅降低一半
exp_range:在每次循环迭代时将初始振幅降低:gamma**(循环迭代)
[6] gamma:exp_range模式中缩放函数中的常量;
[7] scale_fn:由单个参数lambda函数定义的自定义缩放策略,其中0 <= scale_fn(x) <= 1 for all x >= 0。如果指定,则’mode’将被忽略;
[8] scale_mode:有cycle和iterations两种,定义scale_fn是按cycle计算还是按cycle iterations计算;
[9] cycle_momentum:若为True:动量与学习速率成反比在’base_momentum’ 和 ‘max_momentum’ 之间循环;
[10] base_momentum:动量下边界;
[11] max_momentum:动量上边界;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,
step_size_up=5, step_size_down=15)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(5):
for batch in range(20):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('CyclicLR-triangular')

model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,
mode = 'triangular2',
step_size_up=5, step_size_down=15)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(5):
for batch in range(20):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('CyclicLR-triangular2')

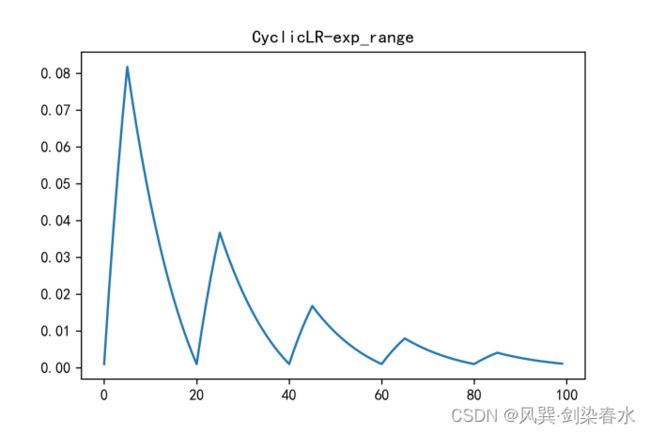
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,
mode = 'exp_range', gamma = 0.95,
step_size_up=5, step_size_down=15)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(5):
for batch in range(20):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('CyclicLR-exp_range')
9. CosineAnnealingWarmRestarts()
CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
(1)学习率调整为:余弦退火方式。
(2)参数:
[1] T_0:第一次restart时epoch的数值;
[2] T_mult:每次restart后,学习率restart周期增加因子;
[3] eta_min:最小的学习率;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=15, T_mult=2)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(100):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('CosineAnnealingWarmRestarts')

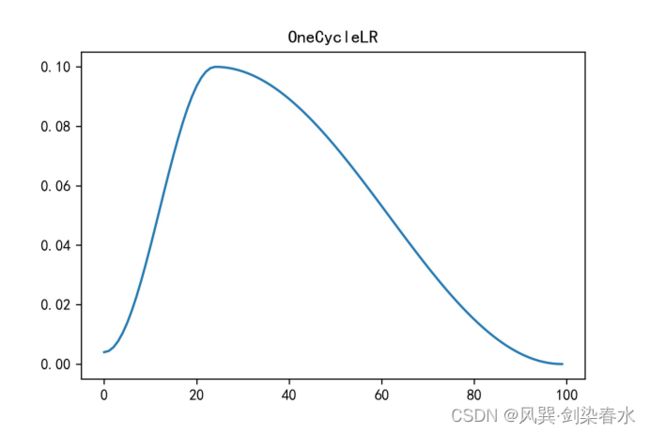
10. OneCycleLR()
OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy=‘cos’, cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25., final_div_factor=1e4, three_phase=False, last_epoch=-1, verbose=False)
(1)学习率调整为:根据“1cycle”策略,设置各参数组的学习率。1cycle策略将学习率从初始学习率退火到最大学习率,然后从最大学习率退火到远低于初始学习率的最小学习率。
(2)参数:
[1] max_lr:周期中学习率上界;
[2] total_steps:周期中的总步数;
[3] epochs:训练epoch数;
[4] steps_per_epoch:每个epoch中需要的训练步数;
[5] pct_start:周期中学习率上升占比;
[6] anneal_strategy:退火策略,可为cos和linear;
[7] cycle_momentum:若为True:动量与学习速率成反比 在’base_momentum’ 和 ‘max_momentum’ 之间循环
[8] base_momentum:动量下边界;
[9] max_momentum:动量上边界;
[10] div_factor:通过initial_lr = max_lr/div_factor确定初始学习率;
[11] final_div_factor:通过min_lr = initial_lr/final_div_factor确定最小学习率;
[12] three_phase:若为True,则使用第三阶段根据’final_div_factor’来消除学习率,而不是修改第二阶段;
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, pct_start=0.25,
steps_per_epoch=20, epochs=5)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(5):
for batch in range(20):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('OneCycleLR')
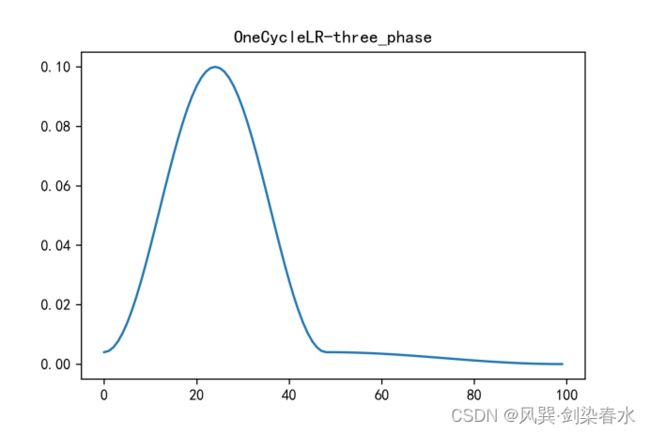
model = [nn.Parameter(torch.randn(4, 4, requires_grad=True))]
optimizer = torch.optim.SGD(model, lr=0.1, momentum=0.9, weight_decay=1e-5)
# -----------------------------------------------------------------------------------
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, pct_start=0.25,
steps_per_epoch=20, epochs=5, three_phase=True)
# -----------------------------------------------------------------------------------
y = []
for epoch in range(5):
for batch in range(20):
lr = optimizer.state_dict()['param_groups'][0]['lr']
y.append(lr)
scheduler.step()
plt.figure(dpi=300)
plt.plot(y)
plt.title('OneCycleLR-three_phase')