RGB-D论文复习速读
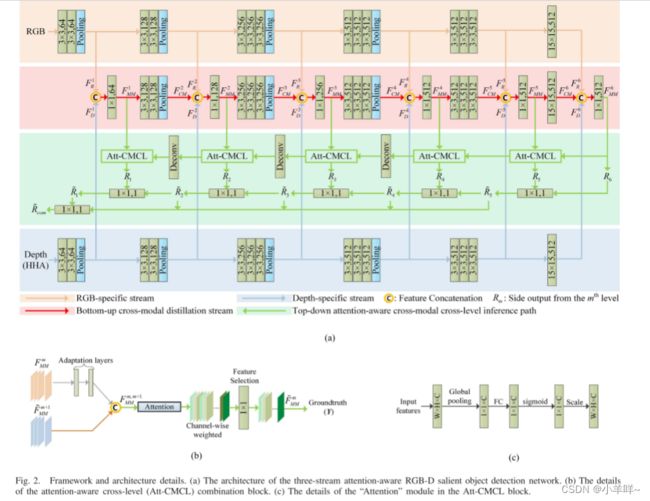
[TANet]Three-stream attention-aware network for RGB-D salient object detection
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 28, NO. 6, JUNE 2019
以往基于卷积神经网络的RGB-D融合系统通常采用双流结构,其中RGB和深度输入是独立学习的。多模态融合阶段通常通过在推理过程中连接每个流的深度特征来执行。由于以下两个局限性,传统的双流体系结构可能会经历不充分的多模式融合:1)跨模式互补很少在自底向上的路径中进行研究,其中,我们认为可以组合跨模态互补来学习新的鉴别特征,以扩大RGB-D表示社区;2)跨模态通道通常通过无差别连接进行组合,这对于选择跨模态互补特征来说似乎是不明确的。在本文中,我们通过提出一种新的三流注意感知多模融合网络来解决这两个局限性。在所提出的架构中,引入了一个跨模式蒸馏流,伴随着特定于RGB和特定于深度的流,以在自底向上路径的每个级别中提取新的RGB-D特征。此外,在跨模态跨层次融合问题中,创新性地引入了通道注意机制,从每个层次的每个模态中自适应地选择互补特征映射。大量实验报告了所提出的架构的有效性,以及相对于最先进的RGB-D显著目标检测方法的显著改进。
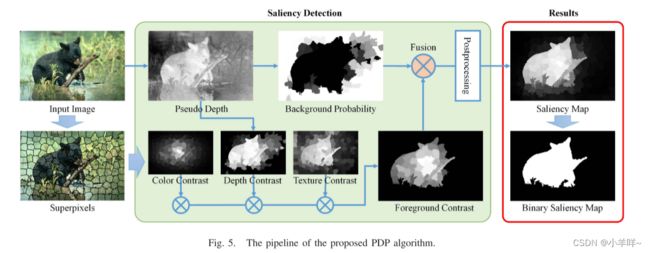
RGB-‘D’ Saliency Detection With Pseudo Depth
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 28, NO. 5, MAY 2019
最近的研究表明了在显着目标检测中使用深度信息的有效性。然而,到目前为止,最常见的图像仍然是不包含深度数据的 RGB 图像。同时,人脑可以从仅 RGB 的图像中提取场景的几何模型,从而提供场景的 3D 感知。受此观察的启发,我们提出了一个名为 RGB-'D' 显着性检测的新概念,它从 RGB 图像中获取伪深度,然后执行 3D 显着性检测。伪深度可以用作图像特征、先验知识、附加图像通道或独立的深度诱导模型,以提高传统 RGB 显着性模型的性能。作为说明,我们开发了一种新的显着对象检测算法,该算法使用伪深度来推导深度驱动的背景先验和深度对比特征。在几个标准数据库上的广泛实验验证了所提出算法的有希望的性能。此外,我们还将两个监督 RGB 显着性模型应用于我们的 RGB-'D' 显着性框架以增强性能。结果进一步证明了所提出的 RGB-'D' 显着性框架的泛化能力。
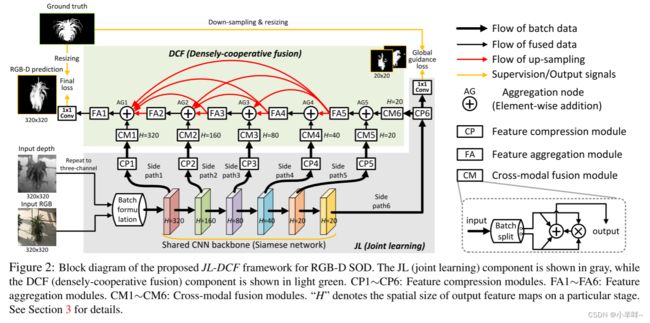
JL-DCF: Joint Learning and Densely-Cooperative Fusion
Framework for RGB-D Salient Object Detection
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
本文提出了一种用于 RGB-D 显着目标检测的新型联合学习和密集协作融合 (JL-DCF) 架构。现有模型通常将 RGB 和深度视为独立信息,并设计单独的网络以从每个信息中提取特征。这种方案很容易受到有限数量的训练数据或过度依赖精心设计的训练过程的限制。相比之下,我们的 JL-DCF 通过 Siamese 网络从 RGB 和深度输入中学习。为此,我们提出了两个有效的组件:联合学习(JL)和密集协作融合(DCF)。 JL 模块提供了强大的显着性特征学习,而后者被引入用于补充特征发现。对四个流行指标的综合实验表明,所设计的框架产生了一个具有良好泛化能力的鲁棒 RGB-D 显着性检测器。结果,JL-DCF 在六个具有挑战性的数据集上将 top-1 D3Net 模型平均提高了 ∼1.9%(S-measure),表明所提出的框架为实际应用提供了潜在的解决方案,并且可以提供更多深入了解跨模态互补任务。
A2dele: Adaptive and Attentive Depth Distiller for
Efficient RGB-D Salient Object Detection
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
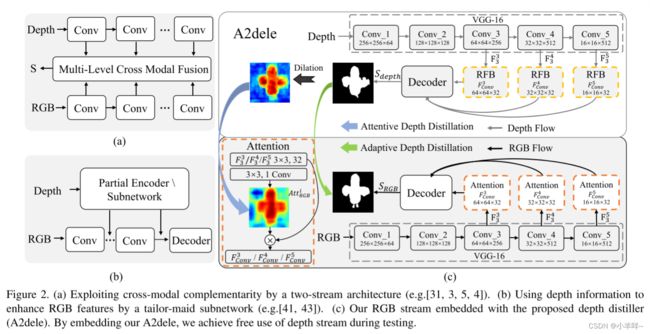
现有的最先进的rgb-d显着对象检测方法依赖于两流架构来探索rgb-d数据,在该架构中,需要一个独立的子网来处理深度数据。这不可避免地会产生额外的计算成本和内存消耗,并且在测试过程中使用深度数据可能会阻碍rgb-d显着性检测的实际应用。为了解决这两个难题,我们提出了一种深度蒸馏器 (A2dele) 来探索使用网络预测和注意力作为两座桥梁将深度知识从深度流传递到RGB流的方法。首先,通过自适应地最小化从深度流和RGB流生成的预测之间的差异,我们实现了对转移到RGB流的像素级深度知识的期望控制。其次,为了将定位知识转移到RGB特征上,我们鼓励深度流的扩展预测与RGB流的注意力图之间保持一致。结果,通过嵌入我们的A2dele,我们在测试时无需使用深度数据即可实现轻量级架构。我们对五个基准进行的广泛的实验评估表明,我们的RGB流实现了最先进的性能,与最佳性能方法相比,它极大地将模型大小最小化了76%,并以12倍的速度运行。此外,我们的A2dele可以应用于现有的rgb-d网络,以显着提高其效率,同时保持性能 (对于DMRA,FPS提高了近两倍,对于CPFP提高了3倍)。
Select, Supplement and Focus for RGB-D Saliency Detection
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
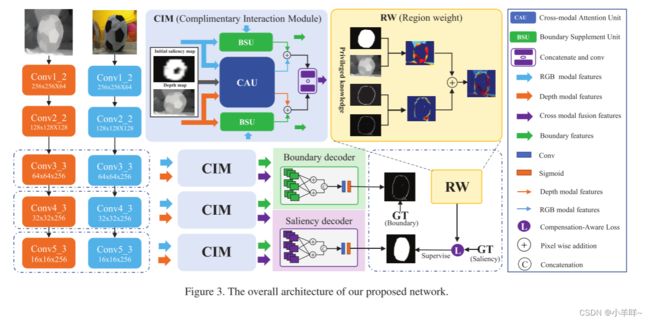
已证明在位置上包含优势判别力的深度数据有利于准确的显着性预测。然而,RGB-D 显着性检测方法也受到深度图或沿对象边界随机分布的错误或缺失区域的负面影响。这提供了通过精心设计的模型实现更有效推理的可能性。在本文中,我们提出了一个新的框架,用于精确的 RGB-D 显着性检测,考虑到两种模式的全局位置和局部细节互补性。这是通过设计一个互补交互模块 (CIM) 来从 RGB 和深度数据中有区别地选择有用的表示,并有效地集成跨模态特征来实现的。受益于所提出的 CIM,融合特征可以准确定位具有精细边缘细节的显着对象。此外,我们提出了一种补偿感知损失,以提高网络检测硬样本的信心。对六个公共数据集的综合实验表明,我们的方法优于 18 种最先进的方法。
RGBD Salient Object Detection via Disentangled
Cross-Modal Fusion
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 29, 2020
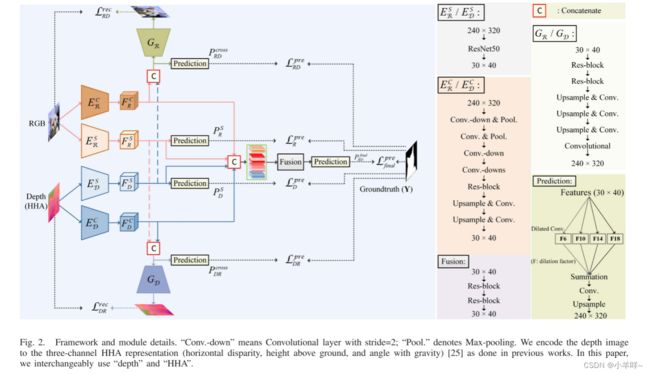
Depth由于其额外的显著性线索,有利于显著目标检测(SOD)。现有的RGBD-SOD方法侧重于裁剪复杂的跨模态融合拓扑,虽然取得了令人鼓舞的性能,但在研究跨模态互补性时存在过度拟合和模糊的高风险。与这些传统方法完全结合跨模态特征而不进行区分不同,我们专注于解耦不同的跨模态互补,以简化融合过程并增强融合充分性。我们认为,如果跨模态异构表示可以被明确地分离,跨模态融合过程可以保持较少的不确定性,同时具有更好的适应性。为此,我们设计了一个分离的跨模态融合网络,通过跨模态重建来揭示两种模态的结构和内容表示。对于不同的场景,分离的表示允许融合模块轻松识别和合并信息多模态融合所需的补充。大量实验表明,我们的设计是有效的,并且比最先进的方法有很大的优越性。
ICNet: Information Conversion Network for RGB-D Based Salient Object Detection
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 29, 2020
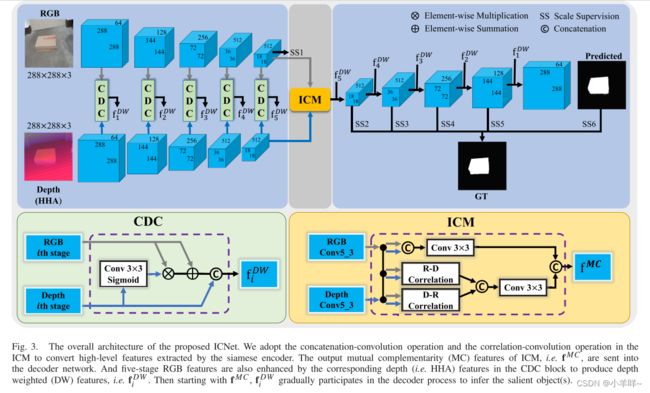
基于 RGB-D 的显着目标检测 (SOD) 方法利用深度图作为有价值的补充信息,以获得更好的 SOD 性能。 以前的方法主要在三个融合域中利用 RGB 图像和深度图之间的相关性:输入图像、提取的特征和输出结果。 然而,这些融合策略并不能完全捕捉到 RGB 图像和深度图之间的复杂相关性。 此外,这些方法没有充分挖掘信息的跨模态互补性和跨层次连续性,对不同来源的信息一视同仁。 在本文中,为了解决这些问题,我们提出了一种新颖的信息转换网络(ICNet),用于基于 RGB-D 的 SOD,采用带有编码器-解码器架构的连体结构。 为了以交互和自适应的方式融合高级 RGB 和深度特征,我们提出了一种新颖的信息转换模块 (ICM),其中包含连接操作和相关层。 此外,我们设计了一个跨模态深度加权组合 (CDC) 块来区分来自不同来源的跨模态特征,并在每个级别使用深度特征增强 RGB 特征。 对五个常用测试数据集的广泛实验证明了我们的 ICNet 优于 15 种基于 RGB-D 的 SOD 方法,并验证了所提出的 ICM 和 CDC 块的有效性。
DPANet: Depth Potentiality-Aware Gated Attention
Network for RGB-D Salient Object Detection
IEEE TRANSACTIONS ON IMAGE PROCESSING 2020
RGB-D显着目标检测有两个主要问题:(1)如何有效整合跨模态RGB-D数据的互补性; (2)如何防止不可靠深度图的污染效应。事实上,这两个问题是联系在一起的,相互交织,但之前的方法往往只关注第一个问题,而忽略了对深度图质量的考虑,这可能会使模型陷入次优状态。在本文中,我们在一个整体模型中协同解决这两个问题,并提出了一个名为 DPANet 的新型网络,以明确建模深度图的潜力并有效整合跨模态互补性。通过引入深度潜能感知,网络可以基于学习的方式感知深度信息的潜能,引导两种模态数据的融合过程,防止污染的发生。融合过程中的门控多模态注意模块利用门控控制器的注意机制从跨模态的角度捕获远程依赖关系。在 8 个数据集上与 16 种最先进的方法进行比较的实验结果在数量和质量上证明了所提出方法的有效性。
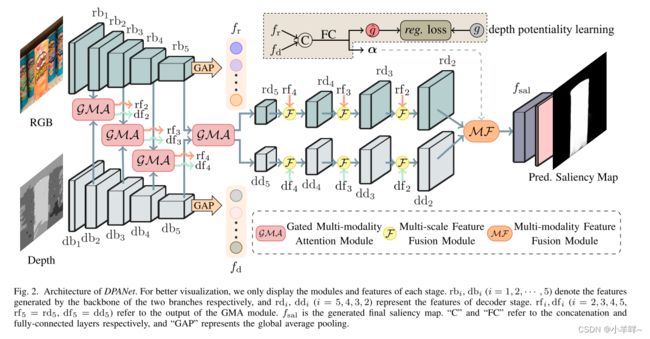
Cross-modality Discrepant Interaction Network for RGB-D
Salient Object Detection
arXiv:2108.01971v1 [cs.CV] 4 Aug 2021
深度图的流行和推广为显着目标检测(SOD)带来了新的生机和活力,大量RGB-D SOD算法被提出,主要集中在如何更好地融合RGB图像和深度的跨模态特征地图。对于特征编码器中的跨模态交互,现有方法要么不加区别地处理RGB和深度模态,要么只习惯性地利用深度线索作为RGB分支的辅助信息。与它们不同的是,我们重新考虑了两种模态的状态,并提出了一种新的用于 RGB-D SOD 的跨模态差异交互网络 (CDINet),它根据不同层的特征表示对两种模态的依赖关系进行差分建模。为此,设计了两个组件来实现有效的跨模态交互:1)RGB 诱导的细节增强(RDE)模块利用 RGB 模态在低级编码器阶段增强深度特征的细节。 2)深度诱导语义增强(DSE)模块将目标定位和深度特征的内部一致性传递到高级编码器阶段的RGB分支。此外,我们还设计了一种密集解码重建(DDR)结构,该结构通过结合多级编码器特征来构建语义块,以升级特征解码中的跳过连接。对五个基准数据集的广泛实验表明,我们的网络在数量和质量上都优于 15 种最先进的方法。
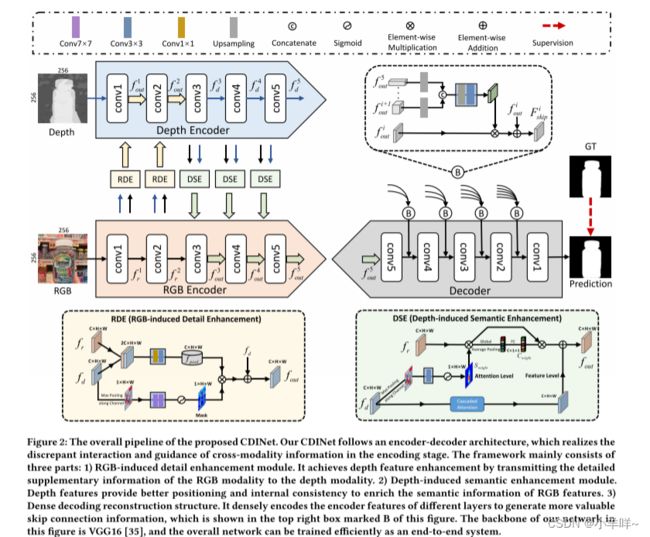
Rethinking RGB-D Salient Object Detection:
Models, Data Sets, and Large-Scale Benchmarks
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 32, NO. 5, MAY 2021
近年来,RGB-D 信息在显着目标检测 (SOD) 中的应用得到了广泛的探索。然而,在现实世界人类活动场景中使用 RGB-D 对 SOD 进行建模的努力相对较少。在本文中,我们通过对 RGB-D SOD 做出以下贡献来填补这一空白:1) 我们仔细收集了一个新的显着人物 (SIP) 数据集,该数据集由覆盖不同现实世界场景的 ∼1 K 高分辨率图像组成从不同的视角、姿势、遮挡、照明和背景; 2)我们进行了大规模(也是迄今为止最全面的)基准比较当代方法,该方法在该领域长期缺失,可以作为未来研究的基线,我们系统地总结了 32 个流行模型并评估7 个数据集的 32 个模型中的 18 个部分,总共包含约 97k 幅图像; 3)我们提出了一种简单的通用架构,称为深度净化器网络(D3Net)。它由深度净化器单元(DDU)和三流特征学习模块(FLM)组成,分别执行低质量深度图过滤和跨模态特征学习。这些组件形成一个嵌套结构,并经过精心设计以共同学习。 D3Net 在所考虑的所有五个指标上都超过了任何先前竞争者的表现,因此成为推进该领域研究的强大模型。我们还展示了 D3Net 可用于有效地从真实场景中提取显着对象掩码,从而在单个 GPU 上以 65 帧/秒的速度实现有效的背景更改应用程序。
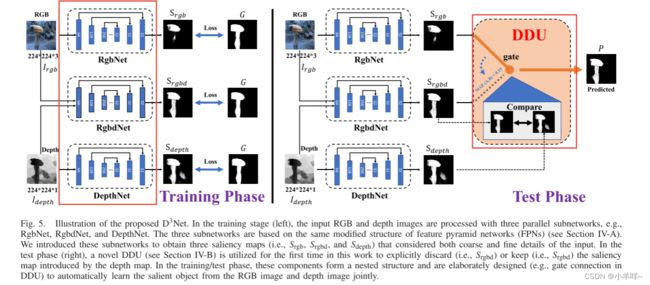
Cross-Modal Weighting Network for
RGB-D Salient Object Detection
ECCV2020
深度图包含辅助显著目标检测(SOD)的几何线索。在本文中,我们提出了一种新的跨模态加权(CMW)策略,以鼓励RGB-D SOD的RGB和深度通道之间的全面交互。具体来说,我们开发了三个RGB深度交互模块,即CMW-L、CMW-M和CMW-H,分别用于处理低、中、高级别的跨模态信息融合。这些模块使用深度到RGB权重(DW)和RGB到RGB权重(RW),允许不同网络块生成的要素层之间进行丰富的跨模态和跨尺度交互。为了有效地训练所提出的跨模态加权网络(CMWNet),我们设计了一个复合损失函数,总结了不同尺度上中间预测和真值之间的误差。通过所有这些新组件的协同工作,CMWNet有效地融合了来自RGB和深度通道的信息,同时探索了跨尺度的对象定位和细节。全面评估表明,CMWNet在七个流行基准上始终优于15种最先进的RGB-D SOD方法。
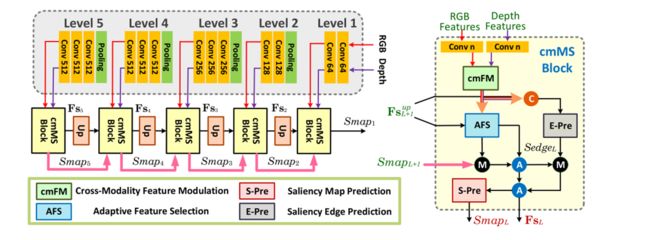
RGB-D Salient Object Detection with Cross-Modality Modulation and Selection
具有跨模态调制和选择的 RGB-D 显着目标检测
ECCV 2020
我们提出了一种有效的方法来逐步整合和完善RGB-D显著目标检测(SOD)的跨模态互补性。该网络主要解决了两个具有挑战性的问题:1)如何有效地集成RGB图像及其对应深度图的互补信息,2)如何自适应地选择更多显著性相关的特征。首先,我们提出了一种跨模态特征调制(cmFM)模块,通过将深度特征作为先验来增强特征表示,该模块对RGB-D数据的互补关系进行建模。其次,我们提出了一种自适应特征选择(AFS)模块来选择与显著性相关的特征并抑制劣质特征。AFS模块利用多模态空间特征融合,考虑了信道特征的自模态和跨模态相互依赖性。第三,我们采用显著引导位置边缘注意力(sg PEA)模块来鼓励我们的网络更加关注显著相关区域。上述模块作为一个整体,称为cmMS块,有助于以从粗到精的方式细化显著性特征。再加上自底向上的推理,细化的显著性特征可以实现精确和边缘保持的SOD。大量实验表明,我们的网络在六种流行的RGB-D SOD基准上优于最先进的显著性检测器。
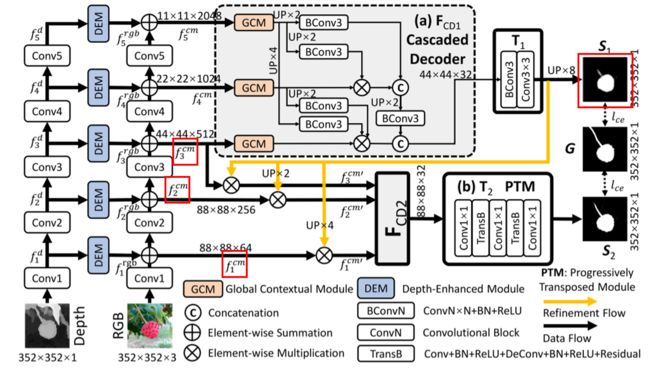
Bifurcated Backbone Strategy for RGB-D Salient Object Detection
RGB-D显著目标检测的分叉主干策略
ECCV2020
多级特征融合是计算机视觉中的一个基本课题。它已被用来检测、分割和分类不同尺度的对象。当多级特征满足多模态提示时,最优特征聚合和多模态学习策略就成了烫手山芋。在本文中,我们利用RGBD显着目标检测固有的多模态和多级性质来设计一种新颖的级联细化网络。特别是,首先,我们建议使用分叉骨干策略 (BBS) 将多层次特征重新组合为教师和学生特征。其次,我们引入了深度增强模块 (DEM),以从通道和空间视图中挖掘信息深度提示。然后,RGB和深度模态以互补的方式融合。我们的架构称为分叉骨干策略网络 (BBS-Net),简单,高效且与骨干无关。广泛的实验表明,在5个评估措施下,BBS-Net在8个具有挑战性的数据集上显著优于18个SOTA模型,证明了我们的方法的优越性 (S-measure相对于排名靠前的模型的4% 改进: DMRA-iccv2019)。此外,我们对不同rgb-d数据集的泛化能力进行了全面分析,并为将来的研究提供了强大的训练集。
CFIDNet: cascaded feature interaction decoder for RGB-D salient object detection
CFIDNET:用于RGB-D显著目标检测的级联特征交互解码器
Neural Computing and Applications (2022)
与RGB显著目标检测(SOD)方法相比,RGB-D SOD模型通过利用深度图中嵌入的空间信息,在许多具有挑战性的场景中表现出更好的性能。然而,现有的RGB-D SOD模型往往忽略模态的特定特征,通过简单的元素加法或乘法融合多模态特征。因此,当遇到不准确或模糊的深度图像时,它们可能会导致噪声退化的显著性图。此外,许多模型采用U形架构,逐层集成多层次特征。尽管低级别特征可以逐渐完善,但对高级特征的增强却很少关注,这可能会导致次优结果。本文提出了一种新的网络CFIDNet来解决上述问题。具体来说,我们设计了特征增强模块,从深度图像中挖掘出信息丰富的深度线索,并利用RGB和深度模式之间的互补信息来增强RGB特征。此外,我们还提出了特征细化模块,利用多层次特征之间的多尺度互补信息,并利用残差连接对这些特征进行细化。然后提出了级联特征交互解码器(CFID)来迭代地细化多级特征。配备了这些提出的模块,我们的CFIDNet能够准确地分割突出的对象。在7个广泛使用的基准数据集上的实验结果验证了我们的CFIDNet在8个评估指标方面,在15个最先进的模型上实现了极具竞争力的性能。我们的源代码将在https://github.com/clelouch/CFIDNet.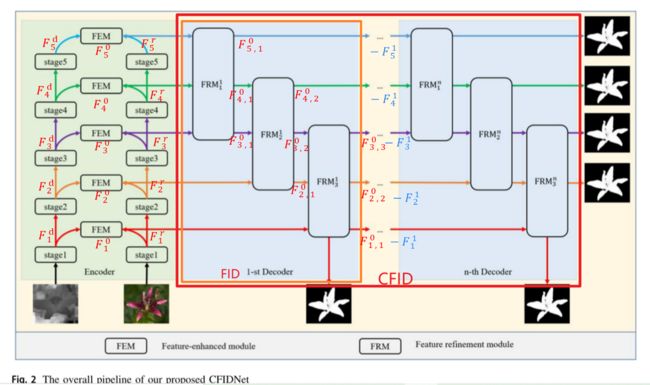
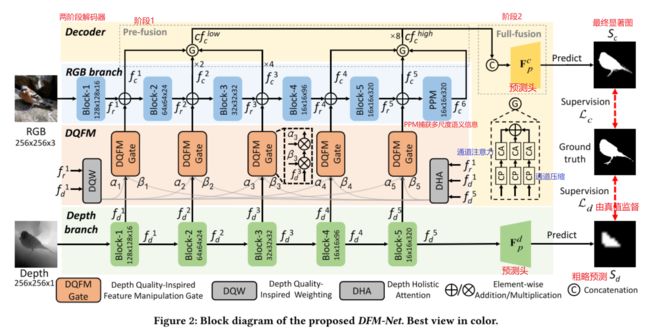
Depth Quality-Inspired Feature Manipulation for Efficient RGB-D Salient Object Detection
用于高效 RGB-D 显着目标检测的深度质量启发特征操作
ACM MM2021
RGB-D 显显著对象检测 (SOD) 最近通过使传统的 RGB SOD 受益于额外的深度信息而引起了越来越多的研究兴趣。 然而,现有的 RGB-D SOD 模型在效率和准确性方面往往表现不佳,这阻碍了它们在移动设备上的潜在应用和实际问题。 一个潜在的挑战是,当模型被简化为只有很少的参数时,模型的准确性通常会降低。 为了解决这一难题,并且受到深度质量是影响精度的关键因素这一事实的启发,我们提出了一种新颖的深度质量启发特征操作 (DQFM) 过程,该过程本身很有效,并且可以用作过滤深度的门控机制 功能大大提高了准确性。 DQFM 借助低级 RGB 和深度特征的对齐,以及深度流的整体关注来明确控制和增强跨模态融合。 我们嵌入 DQFM 以获得称为 DFM-Net 的高效轻量级模型,我们还设计了一个定制的深度骨干网和一个两级解码器,以进一步考虑效率。 大量实验结果表明,与现有的非高效模型相比,我们的 DFM-Net 实现了最先进的精度,同时在 CPU 上以 140 毫秒的速度运行(比之前最快的高效模型快 2.2 倍),只有 ∼8.5Mb 模型大小(之前最轻的 14.9%)。 我们的代码将在 https://github.com/zwbx/DFM-Net 上提供。