医学病例命名实体识别案例
引言:NLP技术目前在社会各个领域都在应用,其中在命名实体识别方面应用很广泛,也是极具特色的。
一、利用NLP技术训练模型,来识别病例里面的关键信息。
1、搜集数据(训练数据、验证数据、测试数据还有一个字典(key:命名实体,value:实体类型)):
训练数据、验证数据、测试数据都是些病例文本信息,字典是我们要识别出来的命名实体,该字典会添加到,jieba分词工具里面,这样才能分出我们要的命名实体。
2、清洗、提取训练数据的特征
这个过程比较繁琐,这里就简单叙述一下:
1、创建一个词典
该词典是个dict,key是字的下标,value是字,这里每个字都是训练数据里面的,就相当于给训练数据里面每个字加一个索引,其中代表当句长不够,要添加的;代表在训练集中未出现的字,如下图:
![]()
2、创建一个实体类型字典:
![]()
如上图,key代表词性,value代表索引。
3、数据封装:
有了上述2个字典、训练数据和初始给的一个字典(key:命名实体,value:实体类型),我们可以封装一下测试数据:
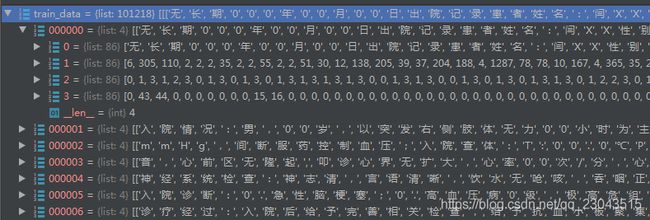
如上图:训练数据是一个101218行的数组train_data,每行是一个长度为4的数组train_arr,train_arr代表一句文本,**train_arr[0]**文本内容,**train_arr[1]**每句文本里的词在词典里面对应下标;**train_arr[2]**每个字在jieba分词里的短语顺序;**train_arr[3]**代表每个字的词性。
三、创建模型:
1、模型初始化主体信息,还有些模型参数在这里就不一一列出来了:
#字下标输入层
class DataModel{
#config 模型参数
def __init__(self, config):
# 字下标输入层 train_arr[1]
self.char_inputs = tf.placeholder(dtype=tf.int32, shape=[None, None], name="CharInPuts")
# 字所在句子中分词短语的顺序
self.seg_inputs = tf.placeholder(dtype=tf.int32, shape=[None, None], name="SegInPuts")
# 字对应的词性
self.targets = tf.placeholder(dtype=tf.int32, shape=[None, None], name="TargetOuts")
# dropout参数
self.dropout = tf.placeholder(dtype=tf.float32, name="Dropout")
# 句子的真实长度
self.lengths = tf.cast(tf.reduce_sum(tf.sign(tf.abs(self.char_inputs)), reduction_indices=1), tf.int32)
'''
其他数据变化操作
'''
}
2、下面具体描述模型中其他的数据变化:
a、嵌入层
embedding = self.embedding_layer(self.char_inputs, self.seg_inputs, config)
#1、输入self.char_inputs和self.seg_inputs
#2、创建一个shape=[self.num_chars, self.char_dim]的矩阵;self.num_chars总的词数,每个词用一个self.char_dim维度的向量表示
#3、创建一个shape=[self.num_segs, self.seg_dim]的矩阵;self.numsegs词的顺序(0,1,2,3),每个顺序数组用一个self.seg_dim维度的向量表示
#4、把这两个矩阵合并最后生成一个shape=[?,?,self.char_dim+self.seg_dim]的矩阵并返回
def embedding_layer(self, char_inputs, seg_inputs, config, name=None):
embedding = []
self.char_inputs_test=char_inputs
self.seg_inputs_test=seg_inputs
with tf.variable_scope("char_embedding" if not name else name), tf.device('/cpu:0'):
self.char_lookup = tf.get_variable(
name="char_embedding",
shape=[self.num_chars, self.char_dim],
initializer=self.initializer)
embedding.append(tf.nn.embedding_lookup(self.char_lookup, char_inputs))
#self.embedding1.append(tf.nn.embedding_lookup(self.char_lookup, char_inputs))
if config["seg_dim"]:
with tf.variable_scope("seg_embedding"), tf.device('/cpu:0'):
self.seg_lookup = tf.get_variable(
name="seg_embedding",
#shape=[4*20]
shape=[self.num_segs, self.seg_dim],
initializer=self.initializer)
embedding.append(tf.nn.embedding_lookup(self.seg_lookup, seg_inputs))
embed = tf.concat(embedding, axis=-1)
self.embed_test=embed
self.embedding_test=embedding
return embed
b、下面将使用双向lstm方法提取特征信息:
bilstm_outputs = self.biLSTM_layer(model_inputs, self.lstm_dim, self.lengths)
#1、用for循环生成forward(前向)和backward(后向)2层lstm,lstm_dim代表h和c的维度,真实句长为lengths
#2、把前向和后向2层、每层节点数lstm_dim和真实句长,传入tf.nn.bidirectional_dynamic_rnn,返回outputs, final_states
#3、outputs代表每时刻的输出,final_states代表最后的输出
#4、这里我们取outputs数据,outputs是一个tuple(元组),元组里面有2个shape=(?,?,100)的Tensor,因为这是双向lstm,一个是前向输出,一个是后向输出,最后把outputs元组中2个Tensor在最后一个维度拼接,返回一个shape=(?,?,lstm_dim*2)的Tensor
def biLSTM_layer(self, model_inputs, lstm_dim, lengths, name=None):
with tf.variable_scope("char_BiLSTM" if not name else name):
lstm_cell = {}
for direction in ["forward", "backward"]:
with tf.variable_scope(direction):
lstm_cell[direction] = tf.contrib.rnn.CoupledInputForgetGateLSTMCell(
lstm_dim, #代表h和c的维度
use_peepholes=True,
initializer=self.initializer,
state_is_tuple=True)
outputs, final_states = tf.nn.bidirectional_dynamic_rnn(
lstm_cell["forward"],
lstm_cell["backward"],
model_inputs,
dtype=tf.float32,
sequence_length=lengths)
return tf.concat(outputs, axis=2)
从上面我们得到 bilstm_outputs 输出,接下来我们计算分类:
self.logits = self.project_layer_bilstm(bilstm_outputs)
#1、传入我们从lstm中得到的lstm_outputs
#2、“hidden”里面先是把lstm_outputs通过reshape,变成2维度的,shape=[-1, lstm_dim*2];再是接一个全连接,并在output结果加个tanh激活函数,W、b都是模型参数,W的shape=(lstm_dim*2,lstm_dim),b的shape=(lstm_dim)
#3、“logits”里面也是一个全连接层,W的shape=(lstm_dim,num_tags),b的shape=(num_tags),num_tags是词性的类别数
#4、最后pred要重新映射为3维的,tf.reshape(pred, [-1, self.num_steps, self.num_tags]),num_steps是句长,num_tags是词性的类别数
def project_layer_bilstm(self, lstm_outputs, name=None):
with tf.variable_scope("project" if not name else name):
with tf.variable_scope("hidden"):
W = tf.get_variable("W", shape=[self.lstm_dim*2, self.lstm_dim],
dtype=tf.float32, initializer=self.initializer)
b = tf.get_variable("b", shape=[self.lstm_dim], dtype=tf.float32,
initializer=tf.zeros_initializer())
output = tf.reshape(lstm_outputs, shape=[-1, self.lstm_dim*2])
hidden = tf.tanh(tf.nn.xw_plus_b(output, W, b))
# project to score of tags
with tf.variable_scope("logits"):
W = tf.get_variable("W", shape=[self.lstm_dim, self.num_tags],
dtype=tf.float32, initializer=self.initializer)
b = tf.get_variable("b", shape=[self.num_tags], dtype=tf.float32,
initializer=tf.zeros_initializer())
pred = tf.nn.xw_plus_b(hidden, W, b)
return tf.reshape(pred, [-1, self.num_steps, self.num_tags])
c、计算损失
self.loss = self.loss_layer(self.logits, self.lengths)
#传入我们计算的类别self.logits和句子的真实长度self.lengths
#这里不使用交叉熵做损失计算,用的是条件随机场,因为这里有状态转移做限制
def loss_layer(self, project_logits, lengths, name=None):
with tf.variable_scope("crf_loss" if not name else name):
'''矩阵拼接'''
small = -1000.0
start_logits = tf.concat(
[small * tf.ones(shape=[self.batch_size, 1, self.num_tags]), tf.zeros(shape=[self.batch_size, 1, 1])], axis=-1)
pad_logits = tf.cast(small * tf.ones([self.batch_size, self.num_steps, 1]), tf.float32)
logits = tf.concat([project_logits, pad_logits], axis=-1)
logits = tf.concat([start_logits, logits], axis=1)
targets = tf.concat(
[tf.cast(self.num_tags*tf.ones([self.batch_size, 1]), tf.int32), self.targets], axis=-1)
#crf_log_likelihood在一个条件随机场里面计算标签序列的log-likelihood
#inputs: 一个形状为[batch_size, max_seq_len, num_tags] 的tensor,
#一般使用BILSTM处理之后输出转换为他要求的形状作为CRF层的输入.
#tag_indices: 一个形状为[batch_size, max_seq_len] 的矩阵,其实就是真实标签.
#sequence_lengths: 一个形状为 [batch_size] 的向量,表示每个序列的长度.
#transition_params: 形状为[num_tags, num_tags] 的转移矩阵
self.trans = tf.get_variable(
"transitions",
shape=[self.num_tags + 1, self.num_tags + 1],
initializer=self.initializer)
#一般使用BILSTM处理之后输出转换为他要求的形状作为CRF层的输入.
#log_likelihood: 标量,crf_log_likelihood在一个条件随机场里面计算标签序列的log-likelihood
#self.trans 生成的转移矩阵
#inputs: 一个形状为[batch_size, max_seq_len, num_tags] 的tensor
#tag_indices: 一个形状为[batch_size, max_seq_len] 的矩阵,其实就是真实标签
#transition_params: 形状为[num_tags, num_tags] 的转移矩阵
#sequence_lengths: 一个形状为 [batch_size] 的向量,表示每个序列的长度
log_likelihood, self.trans = crf_log_likelihood(
inputs=logits,
tag_indices=targets,
transition_params=self.trans,
sequence_lengths=lengths+1)
return tf.reduce_mean(-log_likelihood)
d、建立优化器,优化损失
with tf.variable_scope("optimizer"):
optimizer = self.config["optimizer"]
if optimizer == "sgd":
self.opt = tf.train.GradientDescentOptimizer(self.lr)
elif optimizer == "adam":
self.opt = tf.train.AdamOptimizer(self.lr)
elif optimizer == "adgrad":
self.opt = tf.train.AdagradOptimizer(self.lr)
else:
raise KeyError
e、梯度下降:
为了防止在梯度下降的时候,出现梯度爆炸和梯度消失,这里把梯度控制在 -clip和clip之间
with tf.variable_scope("optimizer"):
#反向传播
grads_vars = self.opt.compute_gradients(self.loss)
#梯度截断
capped_grads_vars = [[tf.clip_by_value(g, -self.config["clip"], self.config["clip"]), v]for g, v in grads_vars]
#梯度下降
self.train_op = self.opt.apply_gradients(capped_grads_vars, self.global_step)
f、保存模型:
保存所有模型参数
self.saver = tf.train.Saver(tf.global_variables(), max_to_keep=5)
四、模型训练
for i in range(100):
for batch in train_manager.iter_batch(shuffle=True):
#train_manager是一个迭代器
step, batch_loss = model.run_step(sess, True, batch)
loss.append(batch_loss)
if step % FLAGS.steps_check == 0:
iteration = step // steps_per_epoch + 1
logger.info("iteration:{} step:{}/{}, "
"NER loss:{:>9.6f}".format(
iteration, step%steps_per_epoch, steps_per_epoch, np.mean(loss)))
loss = []
#每训练一轮,用验证数据验证一次
best = evaluate(sess, model, "dev", dev_manager, id_to_tag, logger)
if i%7==0:
save_model(sess, model, FLAGS.ckpt_path, logger) #保存模型
五、验证
请输入句子:
患者神志清,精神可,无发热、无恶心、呕吐,无抽搐。进食夜眠好,二便正常。查体:Bp129/75mmHg,头颅无畸形,双侧瞳孔正大等圆,对光反射灵敏,右侧胸壁腋前线伤口外敷料固定好,无渗出,胸壁局部软组织无明显肿胀,无压痛。双肺叩清音,未闻及湿性啰音。腹软,无压痛,肠鸣音正常。病情好转,今日出院。
{'string': '患者神志清,精神可,无发热、无恶心、呕吐,无抽搐。进食夜眠好,二便正常。查体:Bp129/75mmHg,头颅无畸形,双侧瞳孔正大等圆,对光反射灵敏,右侧胸壁腋前线伤口外敷料固定好,无渗出,胸壁局部软组织无明显肿胀,无压痛。双肺叩清音,未闻及湿性啰音。腹软,无压痛,肠鸣音正常。病情好转,今日出院。', 'entities': [{'word': '发热', 'start': 11, 'end': 13, 'type': 'SYM'}, {'word': '恶心', 'start': 15, 'end': 17, 'type': 'SYM'}, {'word': '抽搐', 'start': 22, 'end': 24, 'type': 'SYM'}, {'word': '二便正常', 'start': 31, 'end': 35, 'type': 'SYM'}, {'word': '头颅', 'start': 52, 'end': 54, 'type': 'REG'}, {'word': '畸形', 'start': 55, 'end': 57, 'type': 'SGN'}, {'word': '双侧瞳孔', 'start': 58, 'end': 62, 'type': 'REG'}, {'word': '光反射灵敏', 'start': 68, 'end': 73, 'type': 'SGN'}, {'word': '右侧', 'start': 74, 'end': 76, 'type': 'REG'}, {'word': '胸壁', 'start': 76, 'end': 78, 'type': 'ORG'}, {'word': '腋前线伤口', 'start': 78, 'end': 83, 'type': 'DIS'}, {'word': '渗出', 'start': 91, 'end': 93, 'type': 'SYM'}, {'word': '明显', 'start': 102, 'end': 104, 'type': 'DEG'}, {'word': '肿胀', 'start': 104, 'end': 106, 'type': 'SYM'}, {'word': '压痛', 'start': 108, 'end': 110, 'type': 'SGN'}, {'word': '双肺', 'start': 111, 'end': 113, 'type': 'REG'}, {'word': '叩清音', 'start': 113, 'end': 116, 'type': 'SGN'}, {'word': '啰音', 'start': 121, 'end': 124, 'type': 'SGN'}, {'word': '腹软', 'start': 125, 'end': 127, 'type': 'SYM'}, {'word': '压痛', 'start': 129, 'end': 131, 'type': 'SGN'}, {'word': '肠鸣音', 'start': 132, 'end': 135, 'type': 'SGN'}]}