图像分割篇-FCN论文精读
第一部分:论文部分
共提炼出三个创新点:
·对经典网络改编-卷积替换全连接
·对前向特征图补偿-跳跃连接
·对特征图尺寸恢复-反卷积
1、CNN与FCN的比较
CNN 在传统的CNN网络中,在最后的卷积层之后会连接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如ALexNet网络最后输出一个1000维的向量表示输入图像属于每一类的概率.
FCN FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。与经典CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,上采样的特征图进行像素的分类。
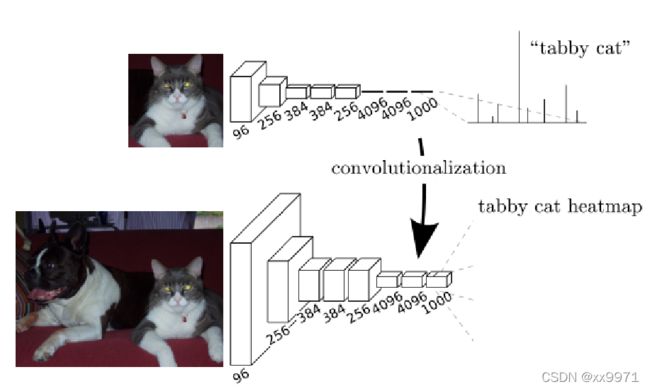
可以看出,FCN在CNN的基础上将全连接层转换为卷积层可以使分类网输出热图。添加层和空间损失产生了端到端密集学习的高效机器。
2、跳跃连接
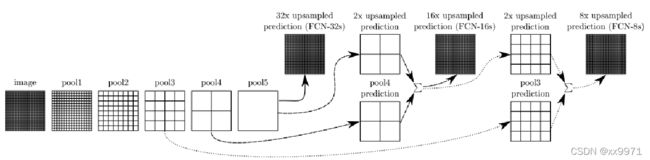
将在卷积的前几层提取到的特征图分别和后面的上采样层相连,然后再相加继续网上往上上采样,上采样多次之后就可以得到和原图大小一致的特征图了,这样可以在还原图像的时候能够得到更多原图所拥有的信息。对第5层的输出执行32倍的反卷积得到原图,得到的结果不是很精确,论文中同时执行了第4层和第3层输出的反卷积操作(分别需要16倍和8倍的上采样),再把这3个反卷积的结果图像融合,提升了结果的精确度。
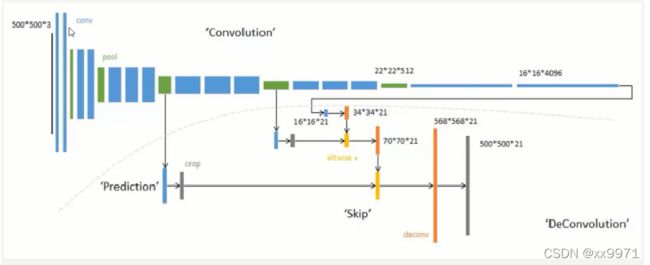
使用跃层结构融合多层输出,使得网络能够预测更多的位置信息。因为在浅层网络位置信息等保留的比较好,将他们加入到深层输出中,就可以预测到更精细的信息。
3、上采样-反卷积
卷积操作的逆运算,反卷积并不能复原因卷积操作造成的值的损失,它仅仅将卷积过程中的步骤反向变换一次,因此它还可以被成为转置卷积。
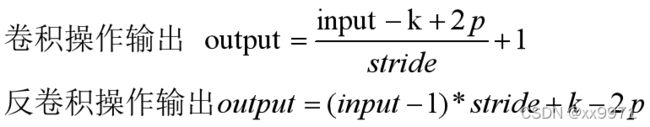
反卷积和普通卷积的区别:
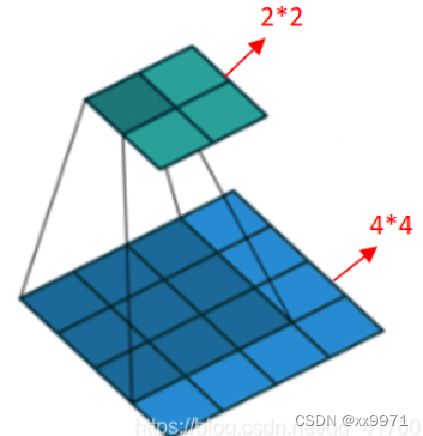
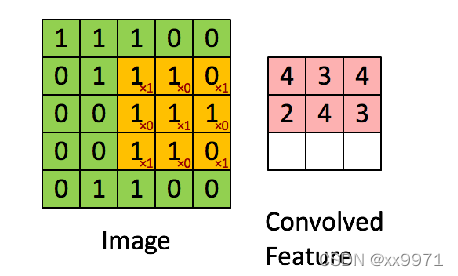
普通的卷积操作,会使得分辨率降低,如下图3*3的卷积核去卷积4*4得到2*2的输出
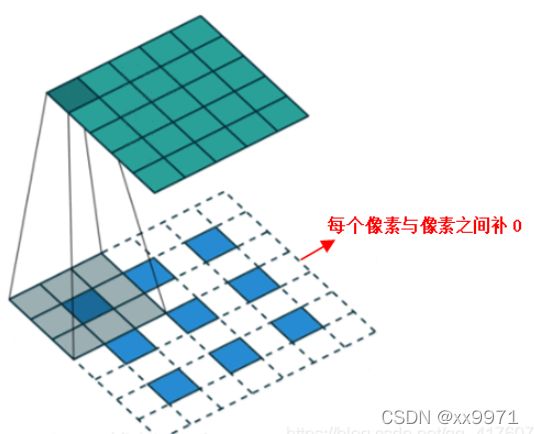
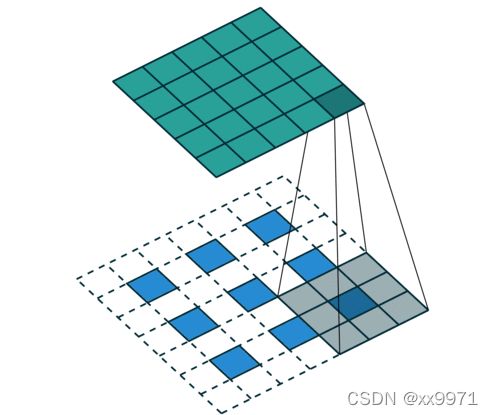
反卷积,首先对特征图各神经元之间进行0填充,即上池化;然后再进行卷积运算
反卷积函数:
ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0.**args)
![]()
假设输出扩大S倍,则步长为S,卷积核大小为2S,填充为S/2. O=(I-1)*S+2S-S=S*I
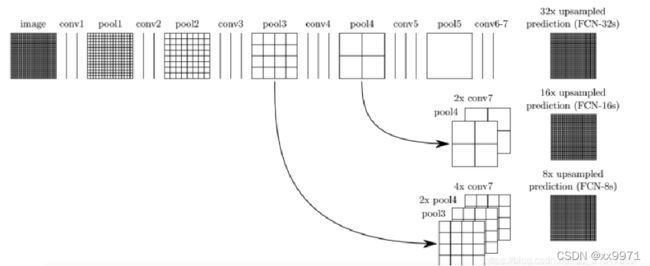
FCN-32s:其实就是第一层,con6-7之后直接进行32倍上采样至原图大小。
FCN-16s:把con6-7之后的网络先进行2倍上采样恢复至原图的1/16,再结合pool4中1/16的特征图,最后两个一起进行16倍上采样恢复至原图大小。
FCN-8s:则是在FCN-16s的基础上再加上pool3的特征图,最后一起进行8倍上采样。
如果我们想让特征图缩放为原来的32倍,那么此时我们的stride就应该设置为32,padding0的方式为每个featuremap的像素每隔一个填充stride-1个,也就是填充31个0.
举例图像的反卷积过程
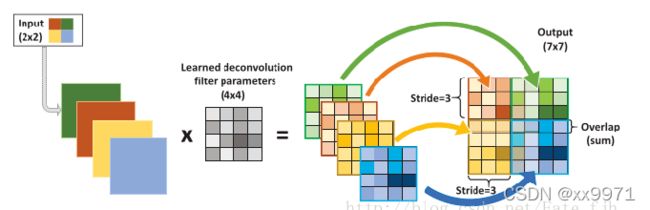
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7 即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
注:full卷积 滑动步长为1,图片大小为2x2,卷积核大小为3x3,卷积后图像大小:4x4
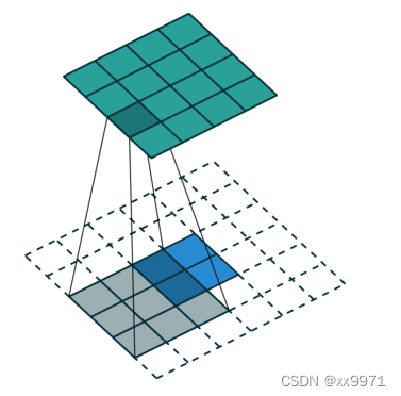
另一种反卷积:原图是3X3,首先使用上采样让图像变成7X7,可以看到图像多了很多空白的像素点。使用一个3X3的卷积核对图像进行滑动步长为1的valid卷积(如左图),得到一个5X5的图像,使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富
4、损失函数
推导过程:


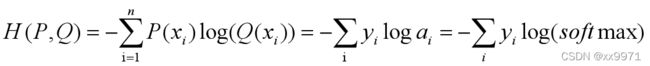
NLLLoss:负对数似然损失函数 --计算方式与交叉熵相同
例:在三分类任务中,输入input=[-1.233,2.657,0.534],真实标签类别class=2,one-hot编码[0,0,1],则loss=-0.534,就是在对应类别的输出上取一个负号。
本实验损失函数是在最后一层的 spatial map上的 pixel 的 loss 和,在每一个 pixel 使用 softmax loss
损失计算:
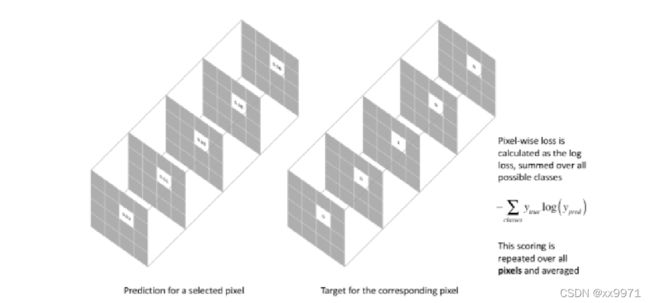
交叉熵的损失函数单独评估每个像素矢量的类预测,然后对所有像素求平均值。 FCN 在每个通道加权该损失
第二部分:代码部分
· 数据预处理
· FCN模型
· 相关指标计算
· 训练集、验证集、测试集
1、标签编码
对应算法与数据结构中的哈希算法,哈希算法是为了形成一种多对一或一对一的映射关系,从而加快检索和查询效率。
Encode_lable_color(colormap)函数形成颜色到标签的一一对应关系
例:使用类似256进制的方法映射每一个colormap里的像素带你到它所对应的类别
希函数:(cm[0]*256+cm[1]*256+cm[2]
哈希映射:cm2lbl[(cm[0]*256+cm[1])*256+cm[2]]=i
哈希表:cm2lbl 一个像素点如p(128,64,128)由编码函数(p[0]*256+p[1])*256+p[2]转化为整数(8405120),将这个数字作为一个像素点P在cm2lbl[8405120]去查询像素点p(128,64,128)所对应的类别i。
2、FCN模型
class FCN(nn.Module):
def __init__(self, num_classes):
super().__init__()
# 从vgg中分别提取五个下采样块
self.stage1 = pretrained_net.features[:7]
self.stage2 = pretrained_net.features[7:14]
self.stage3 = pretrained_net.features[14:24]
self.stage4 = pretrained_net.features[24:34]
self.stage5 = pretrained_net.features[34:]
# 分数图 分别对应32s、16s、8s
self.scores1 = nn.Conv2d(512, num_classes, 1)
self.scores2 = nn.Conv2d(512, num_classes, 1)
self.scores3 = nn.Conv2d(128, num_classes, 1)
self.conv_trans1 = nn.Conv2d(512, 256, 1)
self.conv_trans2 = nn.Conv2d(256, num_classes, 1)
# ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0.**args)
self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False)
self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16) # 使用双线性插值的方法初始化卷积层中卷积核的权重参数
self.upsample_32x = nn.ConvTranspose2d(512, 512, 64, 32, 16, bias=False)
self.upsample_32x.weight.data = bilinear_kernel(512, 512, 64)
self.upsample_16x = nn.ConvTranspose2d(512, 512, 32, 16, 8, bias=False)
self.upsample_16x.weight.data = bilinear_kernel(512, 512, 32)
self.upsample_2x_1 = nn.ConvTranspose2d(512, 512, 4, 2, 1, bias=False)
self.upsample_2x_1.weight.data = bilinear_kernel(512, 512, 4)
self.upsample_2x_2 = nn.ConvTranspose2d(256, 256, 4, 2, 1, bias=False)
self.upsample_2x_2.weight.data = bilinear_kernel(256, 256, 4)
def forward(self, x): # 352,480,3
s1 = self.stage1(x) # 176,240,64
s2 = self.stage2(s1) # 88,120,128
s3 = self.stage3(s2) # 44, 60,256
s4 = self.stage4(s3) # 22,30,512
s5 = self.stage5(s4) # 11,15,512
q1 = self.upsample_32x(s5) # 352,480,512
scores1 = self.scores1(q1) #352,480,12
s5 = self.upsample_2x_1(s5) #22,30,512
add1 = s4+s5 #22,30,512
q2 = self.upsample_16x(add1) #352,480,512
scores2 = self.scores2(q2) #352,480,12
add1 = self.conv_trans1(add1) #22,30,256
add1 = self.upsample_2x_2(add1) #44,60,256
add2 = add1+s3 #44,60,256
add2 = self.conv_trans2(add2) #44,60,12
scores3 = self.upsample_8x(add2) #352,480,12
return scores33、混淆矩阵
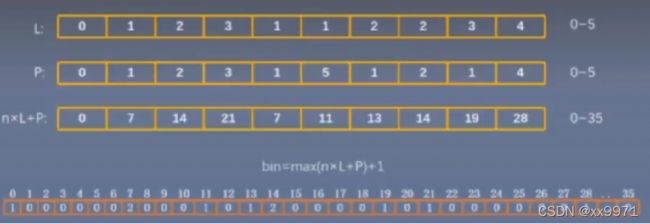
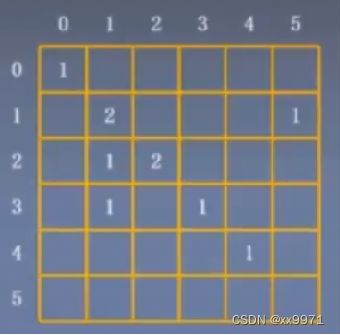
4、计算指标
交并比
平均交并比
像素准确度
类精度
平均类精度
举例
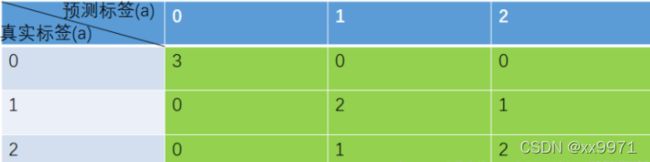
PA = 对角线元素之和 / 矩阵所有元素之和 = (3 + 2 + 2) / (3 + 2 + 2 + 0 + 0 + 0 + 0 + 1 + 1= 0.78
CPA:Pi = 对角线值 / 对应列的像素总数
P类别1 = 3 / ( 3 + 0 + 0) = 1
P类别2 = 2 / ( 0 + 2 + 1) = 0.67
P类别3 = 2 / ( 0 + 1 + 2) = 0.67
MPA = sum(Pi) / 类别数 = ( P类别1 + P类别2 + P类别3 ) / 3 = 0.78
IOU交并比:真实值和预测的交集/真实和预测的并集=对角线/行和+列和-对角线
IoUi = 对角线值 / 与该值有关元素的求和
第一种求法:(混淆矩阵) 第二种求法(代码中用的求法:SAUB = SA + SB - SA∩B) IoU类别1 = 3 / (3 + 0 + 0 + 0 + 0) = 1 IoU类别1 = 3 / [(3 + 0 + 0 ) + ( 3 + 0 + 0) - 3] = 1
IoU类别2 = 2 / (0 + 2 + 1 + 0 + 1) = 0.5 IoU类别2 = 2 / [(0 + 2 + 1 ) + (0 + 2 + 1) - 2] = 0.5
IoU类别3 = 2 / (0 + 1 + 2 + 0 + 1) = 0.5 IoU类别3 = 2 / [(0 + 1 + 2 ) + (0 + 1 + 2) - 2] = 0.5
MIoU = sum(IoUi) / 类别数 = (1 + 0.5 + 0.5) / 3 = 0.67
欢迎大家批评指正!!!!