pytorch 深度学习实践 第8讲 加载数据集
第8讲 加载数据集 dataset and dataloader
pytorch学习视频——B站视频链接:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
以下是视频内容笔记以及小练习源码,笔记纯属个人理解,如有错误欢迎路过的大佬指出 。
前言:dataset——构造数据集,数据集应该支持索引操作;dataloader——为训练提供mini-batch数据
1. 基本概念理解
-
mini-batch的定义及作用
将数据分成若干个批次,遍历一个批次的数据集计算一次损失函数,然后计算函数对各个参数的梯度,更新参数。使用mini-batch可以有效解决鞍点问题,同时也降低了随机性(和训练一个数据更新参数比较)。
-
epoch
一个周期:所有样本都进行了一次前馈、反馈和更新的过程,也就是所有样本都参与了一次训练。
-
batch-size
批量大小:训练一次所需要的样本数量,也就是一个mini-batch的大小。
-
iteration
迭代次数:一个mini-batch经过多少次迭代把所有样本训练完一次,直观上来看就是总的batch所包含的mini-batch的数量。
如图所示:

-
Dataloader
shuffle=True表示打乱样本顺序;然后将样本分成2个一组batch。如图所示
2. 代码说明
- Dataset是一个抽象类,不能被实例化,需要 定义一个类继承自 Dataset类——>DiabetesDataset类
- 定义的DiabetesDataset类需要实现Dataset类的getitem和len方法
- _getitem_ (魔法函数):为数据集增加索引,可以通过索引将数据集的某一个数据取出
- _len_:获取整个数据的长度/数量
- _init_:初始化数据集时有两种方式:第一种是直接将所有数据读入内存,适用于数据容量不大的时候;第二种是将各个数据样本的文件名读取到列表中,使用索引来读取数据集,不一次性读取所有数据。
源码 dataset_and_dataloader.py
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
# 新定义一个类继承自Dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
# 直接取xy数据集的形状的行,表示长度,即样本数量
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[ :, :-1])
self.y_data = torch.from_numpy(xy[ :, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# 实例化数据集对象
dataset = DiabetesDataset('../dataset/diabetes.csv.gz')
# 加载数据集
# dataset是数据集对象,batch-size是批次大小,shuffle表示是否打乱样本顺序,num_workers表示使用多线程
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
# self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
loss_list = []
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. 准备数据
inputs, labels = data
# 2. 前馈
y_pred = model(inputs)
loss = criterion(y_pred, labels)
# print(epoch, i, loss.item())
# 3. 反馈
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, loss.item())
loss_list.append(loss.item())
print(loss_list)
plt.plot(range(100), loss_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
结果怎么是这个鬼样子:
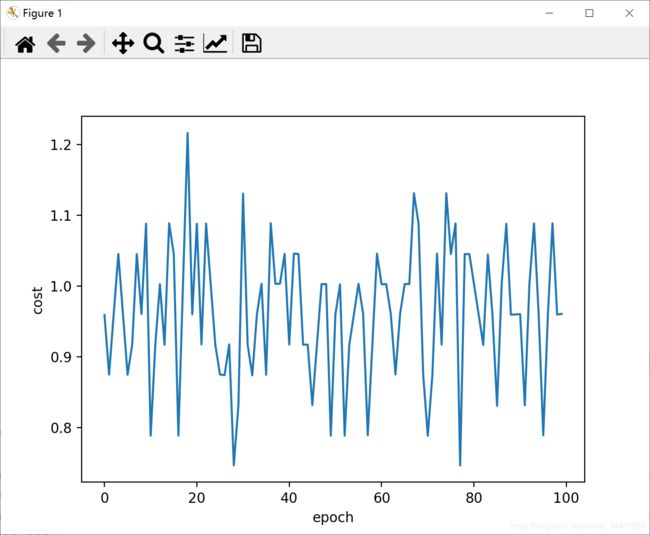
(以上代码已经在pycharm上经过测试,笔记纯属个人理解,如有错误勿介或者欢迎路过的大佬指出 嘻嘻嘻。)
——未完待续……