联邦学习(Federated Learning):技术角度的理解
联邦学习(Federated Learning):技术角度的理解 学习笔记
笔记来源B站学习-链接:B站王树森老师课程
1.背景与动机
例子 Example >>
问题:谷歌希望利用用户移动数据训练模型
可能的解决方案:集中化学习 Centralized Learning
- 搜集用户数据
- 在集群上训练用户模型
挑战:用户拒绝传递他们的数据,尤其是敏感数据,传递到谷歌的服务器上。
即:目前机器学习面临数据孤岛的问题。联邦学习针对这样的问题进行解决。
2.分布式机器学习与联邦学习
参数服务器
过程概述
分布式机器学习中有一个编程模型叫做参数服务器(Parameter Server)。在该编程模型中,有一个Server和若干个Worker。Server和Worker之间可以通过message passing的方式进行通信,如下图:
使用该编程模型进行神经网络或者其他的训练时,worker的工作为计算的工作,Server端存储模型参数并且更新模型参数。训练最小二乘需要做梯度下降或者随机梯度下降,想要让算法收敛需要做很多轮梯度下降,每一轮需要做下面的几个工作:
-
Worker向Server端索要模型参数 -> Server将模型参数发送给Worker
需要通信,通信复杂度是模型的参数数量
-
Worker根据获得的模型参数,在本地计算出模型的梯度或者随机梯度
不需要通信,Worker只需要在本地进行计算即可
-
Worker将计算完的梯度发送给Server
需要通信,通信的复杂度是模型的参数数量(梯度的维度和参数的维度是一样的)
-
Server利用收到的梯度对模型的参数进行更新
如进行一次梯度下降或者随机梯度下降
经过上述过程,一次迭代完成。
总结
在上述过程中,涉及到两次通信:
- Server将模型参数发给Worker
- Worker将计算完的梯度发送给Server
从计算量来看:
- Worker端对梯度进行计算,计算量较大
- Server端对参数进行更新,计算量较小

假如使用这样的分布式机器学习的方式,将每个结点的数据在本机上训练,而不是发送到数据中心。这样用户的数据隐私问题能够得到解决。
联邦学习与分布式机器学习的比较
联邦学习是机器学习的一种。二者主要的区别有下面的几点:
-
用户对自己的数据有绝对的控制权
用户可以随时让自己的设备停止计算和通信。这就类似联邦的概念,每个联邦有很大的自治权。传统分布式机器学习Server对用户设备有绝对的控制权。
-
设备不稳定
进行联邦学习的worker往往是手机、ipad、智能家居等设备。
-
设备的稳定性
联邦学习的设备有可能有断联等问题:设备信号不稳定,断联,或者设备电量耗尽断联等。传统的分布式机器学习的设备往往是机房中的设备,通过高速的带宽相联,专人维护,非常稳定。
-
设备的版本
进行联邦学习的设备可能计算能力不同,譬如不同的手机机型等;但是进行分布式机器学习的设备一般算力相同。不同的计算能力可能造成一系列的问题。
总之,联邦学习的设备不稳定,对分布式计算造成了困难。
-
-
联邦学习的通信代价较大
传统的分布式机器学习通过网线或者高速带宽连接,通信较快。进行联邦学习的设备与服务器的连接往往都是远程连接,甚至设备和服务器不在一个国家。带宽很低,网络延迟很高,发送几千万个模型参数不可能几毫秒完成。
-
联邦学习的数据并非独立同分布
联邦学习和参数服务器一样,都是数据并行(data parallelism)的方式。
在传统分布式机器学习中,将数据在机器之间采取shuffle的方式,使得数据在各个结点上是满足独立同分布的条件的。这样有利于设计算法。
但是每个设备的统计数据并不满足统计数据。很多减少通信量的方式不再适用。
-
结点负载不平衡
有的结点数据集大,有的结点数据集小。对建模造成一定的问题:
- 给与每个样本一样的权重:那么模型会很大程度上取决于样本多的设备
- 给与每个设备一样的权重:由于设备的使用时间不同,模型对重度使用用户不平衡。
总之对建模、计算时间都会造成问题。
传统的分布式ML都是要做负载均衡的,但是FL无法做负载均衡。
故,虽然FL是一种分布式机器学习,但是FL有一些难点,FL有了可以研究的前景。特别是上述的不同点2和3,联邦学习的关键点在于减少通信的次数。
3. 研究方向
通信效率 Communication-Efficiency
联邦学习最重要的方向就是如何降低通信次数,哪怕让计算量提升很多,但是如果能减少通信次数,那么也是值得的。已经有了很多种算法去减少通信次数,这些算法的理念都一样:多做计算,少做通信。

基本想法:Worker得到参数后,在本地做很多计算,这样就可以得到比梯度更好的下降方向。Worker将该更好的下降方向传递给Server,Server用这个下降方向来更新参数。由于这个下降方向更好,所以比梯度下降更容易收敛,收敛的次数更少,从而Server和Worker之间的通信减少。
回顾:并行梯度下降
Worker端工作
每一个Worker上有一部分数据,每一轮并行开始的时候,Server将数据发送给Worker结点。
对于第 i i i个结点,在每一轮,做下面的工作:
- 从Server收到模型的参数 w w w
- 使用 w w w和它的本地数据去计算出梯度 g i g_i gi
- 把梯度 g i g_i gi发送给Server
Server端工作
对于Server端,做这样的工作:
-
从 m m m个worker收到梯度 g 1 , . . . , g m g_1,...,g_m g1,...,gm
-
计算 g = g 1 + . . . + g m g = g_1+...+g_m g=g1+...+gm
-
更新模型参数: w ← w − α ⋅ g w\leftarrow w-\alpha·g w←w−α⋅g
其中 α \alpha α是步长,或者称为学习率
然后进行下一次迭代……直到算法收敛。
Federated Averaging Algorithm
与并行梯度下降不太一样,Federated Averaging Algorithm是一种通信高效算法,使用更少的通信次数就能达到收敛。
Worker端工作
每一轮的开始和并行梯度下降一样:Server将数据发送给Worker结点。但是Worker结点的工作就与之前不一样了。
对于worker的第 i i i次迭代:
-
从Server收到模型的参数 w w w
-
重复下面的两个工作:
- (a) 使用 w w w和本地数据去计算梯度 g g g
- (b) 在本地进行更新: w ← w − α ⋅ g w\leftarrow w-\alpha · g w←w−α⋅g
重复1~5个epoch即可。
-
将 w i ~ = w \tilde{w_i}=w wi~=w发送给Server
注意与上面的并行梯度下降进行比较
Server端工作
对于Server端,做这样的工作:
- 从m个worker接收到 w 1 ~ … w m ~ \tilde{w_1}\dots \tilde{w_m} w1~…wm~
- 更新模型的参数为: w ← 1 m ( w 1 ~ + . . . + w m ~ ) w\leftarrow \frac{1}{m}(\tilde{w_1}+...+\tilde{w_m}) w←m1(w1~+...+wm~)
由于模型更新参数使用的是平均值,所以该算法称作Federated Averaging Algorithm。下一轮迭代开始时,再将新的参数发送给各个Worker。
并行梯度下降 vs. 联邦平均算法
Communication-Loss曲线
使用通信次数作为横轴,损失Loss作为纵轴,将并行梯度下降和联邦平均算法的Communication-Loss曲线绘制如下:
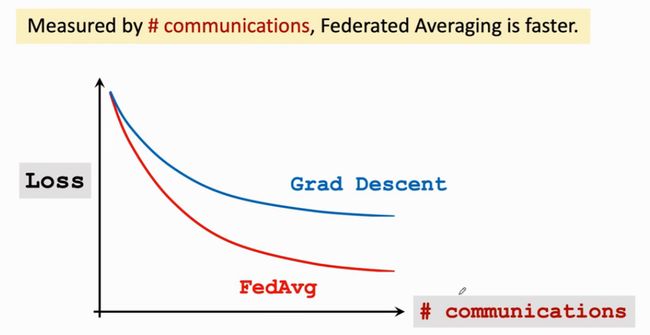
由上图实验结果可知:联邦平均学习(Federated averaging)实现了用更少的通信次数更快的收敛的效果。
Epoch-Loss曲线
另一方面,使用epoch作为横轴,损失Loss作为纵轴,将并行梯度下降和联邦平均算法的Epoch-Loss曲线绘制如下:
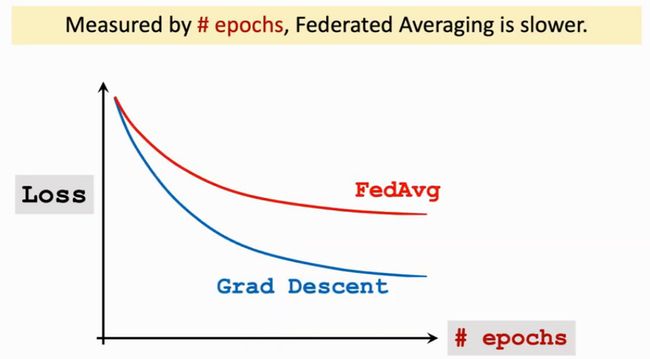
Epoch意为将数据扫一遍,故epoch的数量可以代表计算量的多少。
由上图实验结果可知:联邦平均学习(Federated averaging)和并行梯度下降在使用了相同epoches的情况下,Loss值更大。即让Worker结点做相同的计算量,Federated Averaging的收敛比并行梯度下降要慢。
Federated Averaging减少了通信量,但是增加了计算量。即以牺牲计算量为代价,换取减少通信量。而在联邦学习中,计算代价较小,通信代价较高,所以Federated Averaging还是有效的。
隐私保护方向 Privacy
隐患:梯度反推数据
无论是并行梯度下降还是federated averaging Algorithm,在Server和Worker之间传递的只有模型参数或者梯度,用户的隐私数据并不会传递。
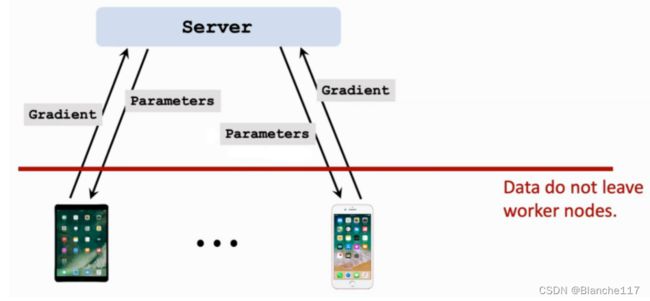
但是这样是否真的能够彻底保证用户隐私?事实上,用户的隐私数据可能会被间接地泄露出去:梯度或者随机梯度是本地的数据计算出来的,计算梯度时,本质是使用了一个函数,将用户的数据映射到了梯度。即梯度携带了数据的信息——梯度可以反推出数据。

防御方式:保护方式
Differencial Privacy方式:向梯度中加入噪声
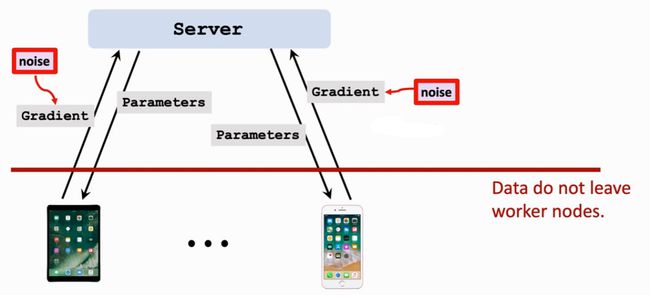
存在问题:
- 噪声过强:训练无法继续
- 噪声过弱:还是能够从梯度反推数据
鲁棒性方向
拜占庭将军问题
故障结点会给其他结点发送错误信息。联邦学习也会存在拜占庭将军问题:若某一个结点故意将数据标签进行修改,那么传给Server的信息就是有害的,会对模型造成影响。

总结:很有必要研究响应的算法。攻击很有效,但是防御较困难。
4.总结
- FL是分布式机器学习的一种。
- 特点:结点间训练模型而不共享数据
- 联邦学习的挑战:
- 通信效率
- 数据独立同分布
- 研究方向
- 通信效率
- 隐私保护
- 鲁棒性