CVPR 2018 | 旷视科技物体检测冠军论文——大型Mini-Batch检测器MegDet
全球计算机视觉顶会 CVPR 2018 (Conference on Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议)将于6月18日至22日在美国盐湖城举行。作为大会钻石赞助商,旷视科技研究院也将在孙剑博士的带领下重磅出席此次盛会。而在盛会召开之前,旷视将针对 CVPR 2018 收录论文集中进行系列解读。

论文名称:MegDet: A Large Mini-Batch Object Detector
论文链接:https://arxiv.org/abs/1711.07240
目录
- 导语
- 设计思想
- 方法
- 实验
- 结论
- 参考文献
导语
深度学习时代,计算机视觉领域的基石之一物体检测技术获得一次飞跃式发展,新模型新方法不断涌现。本文从 mini-batch 角度为加速深度神经网络的训练提供了一种新型检测 MegDet,通过把 mini-batch 扩大至 256,从而可以充分利用 128 块 GPU 并大大缩短了训练时间。从技术上讲,warmup 学习率策略和 Cross-GPU 批归一化(CGBN)共同保证了大型 mini-batch 检测器 MegDet 的成功训练,并且时间更短(从 33 小时缩至 4 小时)精度更高。这意味着 MegDet 从精度和速度两个核心维度优化了物体检测技术,为该技术的落地及其他计算机视觉的应用甚至安防、新零售和无人驾驶等领域的发展进一步铺平了道路。
设计思想
R-CNN 之后,Fast/Faster R-CNN,Mask R-CNN, RetinaNet 等一系列新模型层出不穷,这些基于 CNN 的方法在物体检测领域进展巨大,仅仅两年内,COCO AP 由 19.7(Fast R-CNN)拔升至 39.1(RetinaNet),上述进步的背后,是更优的基础网络,更好的检测架构,更佳的 loss design 以及不断改进的池化方法。
CNN 图像分类模型的一个新近趋势是通过大型 mini-batch 大幅缩减训练时间。比如,通过大小分别为 8192 或 16000 的 mini-batch,ResNet-50 可以 1 小时或 31 分钟完成训练,同时精度几乎不掉点。相反,CNN 图像检测模型的 mini-batch 普遍很小,比如 2-16,而一般分类模型的 mini-batch 大小通常为 256。针对这一问题,本文给出一个技术方案,使得大型 mini-batch 同样适用于检测模型。
小型 mini-batch 有何问题?简单说,有三点:首先,训练极其费时;其次,通过小型 mini-batch 训练无法精确统计批归一化(BN);最后,小型 mini-batch 中正、负实例的数量更易失衡。

图 2:带有正负 proposal 的实例图像。(a-b) 两个实例的比率不平衡;(c-d)两个实例比率平衡且中等。
如果简单地增大 mini-batch,又会面临哪些挑战?正如图像分类问题一样,主要困难在于大型 mini-batch 通常需要配置高学习率以保持精度。但是在物体检测中,高学习率很可能导致模型无法收敛;如果使用较低的学习率,获得的结果通常又较差。
为解决上述问题,本文提出了名为 MegDet 的解决方案:
首先,作者提出线形缩放的一种新解释,并在早期阶段借助“warmup”学习率策略逐渐提高学习率;接着,为解决精度和收敛问题,作者引入多 GPU 批归一化(Cross-GPU Batch Normalization/CGBN)以更好地统计 BN。CGBN 不仅会涨点精度,还会使训练更加稳定,从而可以安全无虑地享用业界强大的算力加持,这很有意义。

图 1:当 mini-batch 大小分别为 16(8 GPUs)和 256(128 GPUs)时,COCO 数据集上训练的同一 FPN 物体检测器的验证集精度。大型 mini-batch 检测器更为精确,训练速度也快了近一个数量级。
MegDet 通过 128 块 GPU 可在 4 小时内完成 COCO 训练,甚至精度更高;相比之下,小型 mini-batch 需要 33 小时完成训练,并且精度更低。这意味着可以把创新周期几乎缩短一个数量级,甚至性能更优。基于 MegDet,旷视夺得 COCO 2017 物体检测挑战赛第一名。
方法
MegDet 作为一个大型 mini-batch 检测器既可以更短时间完成训练,又可实现精度涨点,本节将介绍其方法原理。
由于小型 mini-batch 存在若干问题,而简单增大 mini-batch 必须处理精度与收敛之间的权衡,为此作者引入了针对大型 mini-batch 的学习率策略(warmup)。虽然这在一定程度上优化了收敛,但是对于较大的 mini-batch 比如 128 或者 256 来说,依然有所欠缺。接着作者引入 CGBN,它是大型 mini-batch 训练的关键所在。
CGBN
批归一化是一项训练深度卷积神经网络的重要技术,本文试图将其应用于物体检测。值得一提的是,分类网络的输入图像通常是 224 × 224 或者 299 × 299,一块内存 12G 的 NVIDIA TITAN Xp GPU 足以处理 32 张以上这样的图片。由此,可在每个设备上单独计算 BN。但是对于物体检测来说,检测器需要处理不同尺寸的物体,因此需要输入较高分辨率的图像,并在多块 GPU 执行批归一化以从更多样本中搜集足够的统计信息。
跨 GPU 执行批归一化需要计算所有设备的汇总均值/方差统计信息。绝大多数现有深度学习框架使用 cuDNN 中的 BN 实现,但是只提供高级 API 而无法修改内部统计信息。因此需要初级数学表达式来执行 BN,并通过 AllReduce 操作汇总统计信息。这些细粒度表达式通常显著增加运行时间的开销,而 AllReduce 操作在大多数框架中是缺失的。CGBN 实现如图 3 所示:
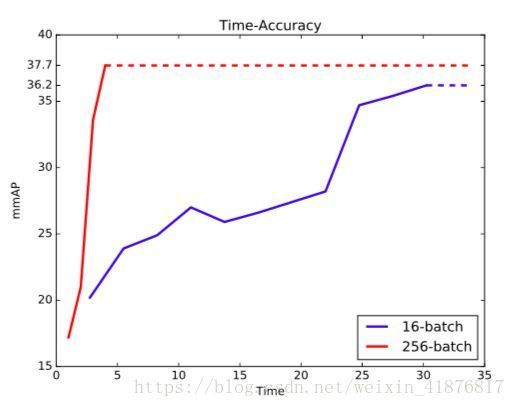
图 3:CGBN 实现。椭圆表示设备之间的同步,圆角框表示多个设备的并行计算。
实验
这次实验使用的数据集是 COCO Detection,它分为训练集,验证集和测试集,涵盖 80 个类别和超过 250000 张图像。Backbone 是在 ImageNet 上完成预训练的 ResNet-50;检测框架是特征金字塔网络(FPN)。训练集图像数量超过 118000 张,验证集为 5000 张图像,SGD optimizer momentum 为 0.9,weight decay 为 0.0001,mini-batch 16 的基础学习率是 0.02。实验的主要结果如表 3 所示:

表 3:不同 mini-batch、BN 大小、GPU 数量和训练策略的训练对比。
除此之外,本文还有以下发现。首先,在 mini-batch 增加的过程中,精度几乎保持在同一水平,这持续优于基线(16-base)。同时,较大的 mini-batch 通常会缩短训练周期。第二,BN 的最佳大小是 32。如果图像太少,比如 2,4,8,BN 统计信息会非常不准确,从而导致更差的性能。然而,如果把大小增加至 64,精度会掉点。这证明了图像分类与物体检测之间的不匹配。

图 4:16-batch 和 256-batch 的验证集精度,使用长期训练策略。两个检测器的 BN 大小相同。垂直的虚线表示学习率衰减的时刻。
第三,如表 3 最后一部分所示,本文调查了长期训练策略。较长的训练时间会带来精度的轻微涨点。最后,如图 4 所示,256-batch 在早期阶段的 epochs 中表现欠佳,但是在最后阶段反超了 16-batch(第二次学习率衰减之后)。这一情况大不同于图像分类,其中精度曲线和收敛分值在不同大小的 mini-batch 设置中非常接近。
结论
本文提出了一种大型 mini-batch 检测器 MegDet,可在更短时间内实现更高精度。这项工作意义重大,极大地缩短了研究周期。借助 MegDet,旷视科技摘取了 COCO 2017 检测挑战赛的桂冠,一些细节如下:


图 5:MegDet 在 COCO 数据集上的示例。

表 4:(增强的)MegDet 在 COCO test-dev 上的结果。
本文的技术贡献主要有 4 个方面:
- 基于保持相等损失方差的假设,本文在物体检测的语境中为线性缩放规则提出一种新解释。
- 本文实现首次在物体检测框架中训练 BN;实验证明 CGBN 不仅有助于精度的涨点,还会使训练更易收敛,尤其是对于大型 mini-batch 来讲。
- 本文首次(基于 ResNet-50)使用 128 块 GPU 在 4 小时内完成 COCO 训练,并实现更高精度。
- MegDet 作为 backbone 在 COCO 2017 物体检测夺冠中发挥了关键作用。
参考文献
- R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea- ture hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014.
- P. Goyal, P. Dolla ́r, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch SGD: Training ImageNet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- A. Krizhevsky. One weird trick for parallelizing convolutional neural networks. arXiv preprint arXiv:1404.5997, 2014.
- K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask R-CNN. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar. Focal loss for dense object detection. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.