Kernel Regression 核回归 详细讲解
Kernel Regression 核回归 详细讲解
目录
- Kernel Regression 核回归 详细讲解
-
- 一、首先介绍一下核函数
- 二、核估计
-
- 举个例子
- 三、核回归
-
- 举个例子
- 四、带宽的影响
传统的线性回归只能拟合一条直线,核回归作为拟合非线性模型的一种方法,本质是利用核函数作为权重函数来建立非线性回归模型的。
先总结一下核回归的结论:
利用核函数计算出 x i x_i xi在 x x x处的权重为: w i = K ( x , x i ) ∑ i = 1 N K ( x , x i ) w_i=\frac{K(x,x_i)}{\sum_{i=1}^{N}K(x,x_i)} wi=∑i=1NK(x,xi)K(x,xi)
x i x_i xi(观测数据点,也就是我们的数据集中的点), x x x(要预测的点)
则在 x x x处预测的 y y y值为所有 y i y_i yi的加权和: y = ∑ i = 1 N w i ∗ y i y=\sum_{i=1}^{N}w_i*y_i y=i=1∑Nwi∗yi
接下来我们就从头开始讨论一下核回归,也称为局部线性回归。
一、首先介绍一下核函数
在非参数统计中,核是一个权重函数,并满足以下性质:
- 核函数是对称的,最大值在曲线中间。下图展示的是高斯核函数:
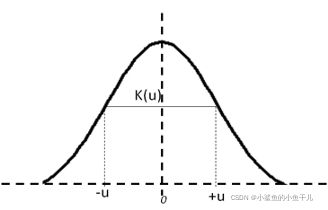
- 函数曲线下方面积必须等于1,即
∫ − ∞ ∞ K ( u ) d u = 1 \int_{-\infty }^{\infty}K(u)du=1 ∫−∞∞K(u)du=1 - 核函数的值必须是非负的,即
K ( u ) ≥ 0 , − ∞ < u < ∞ K(u)\geq0, -\infty
二、核估计
在本篇中,主要讨论使用高斯核函数来拟合数据。高斯核函数的公式如下:
K ( x ) = 1 h 2 π e − 0.5 ( x − x i h ) 2 K(x)=\frac{1}{h\sqrt{2\pi}}e^{-0.5}{(\frac{x-x_i}{h})}^2 K(x)=h2π1e−0.5(hx−xi)2
其中, x i x_i xi 是观察到的数据点, x x x 是需要计算核函数的值(可能表述不准确,但是看到后面就明白了), h h h 是带宽,带宽也叫做核回归的平滑参数。带宽对模型预测的影响稍后讨论。
举个例子
假设这里由6个数据点,代表6个学生某门课的成绩:
x i = { 65 , 75 , 67 , 79 , 81 , 91 } , i = 1 , 2 , 3 , 4 , 5 , 6 x_i=\left \{ 65,75,67,79,81,91\right \}, i=1,2,3,4,5,6 xi={65,75,67,79,81,91},i=1,2,3,4,5,6
现在需要围绕这6个数据点构建核曲线,构建核曲线需要三个输入,分别是:
- 观测数据点 x i x_i xi
- 带宽 h h h的值
- 线性间隔的一系列数据点,包括需要估计 K K K值的观测数据点,如 X j = { 50 , 51 , 52 , . . . , 99 } X_j=\left \{ 50,51,52,...,99\right \} Xj={50,51,52,...,99}。
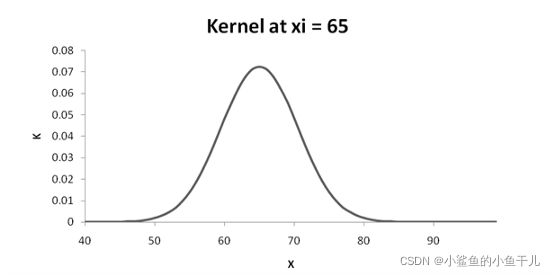
根据给的观测数据点 x i x_i xi和 h h h计算所有 X j X_j Xj的 K K K值,即核函数的值,下图的是观测数据点为 x i = 65 x_i=65 xi=65, h = 5.5 h=5.5 h=5.5时所有 X j X_j Xj的的 K K K值:

将以上数据画图显示出来,横坐标是 X j X_j Xj,纵坐标是 K K K。以 x i x_i xi为均值, h h h为标准差构建的核曲线,可以看到和高斯分布一样
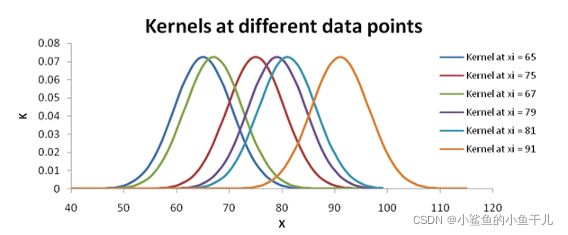
同理,对于所有的6个观测数据点,每个数据点对应一个核曲线,如下图所示。可以看到,对于离 x i x_i xi很远的 X j X_j Xj的 K K K值几乎为0,如当 x i = 65 x_i=65 xi=65是, X j = 99 X_j=99 Xj=99的 K K K值为0.
三、核回归
下面进入重点了,核回归!
上面求出来的核值也就是 K K K值有什么用呢?核值用来计算权重以预测给定输入的输出,那如何计算权重以及如何使用权重来预测输出呢,接下来会详细介绍。
举个例子
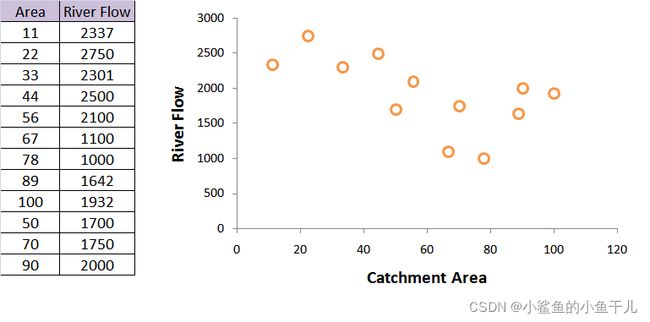
下面给出了不同区域面积对应的河流量数据,区域面积与河流量之间是非线性关系,输入x也就是区域面积,输出y就是河流量。我们要做的就是建立x和y之间的非线性关系。
第一步:核作为权重函数
在上面我们已经讲解过了使用带宽为所有的观测数据点建立核曲线。接下来就要利用这些核曲线计算权重。这个例子中带宽使用了10。这个带宽需要根据数据进行调整以更好的拟合数据。下图展示了在不同x值处的核曲线:

注意:需要在所有的输入值x处建立核曲线,因为核回归的计算本质就是:给一个数据 x i x_i xi,要预测其 y y y值,就是计算所有观测数据 y y y值的加权和,而每个观测数据 y y y的权重就是其核曲线在 x i x_i xi处的那个值。
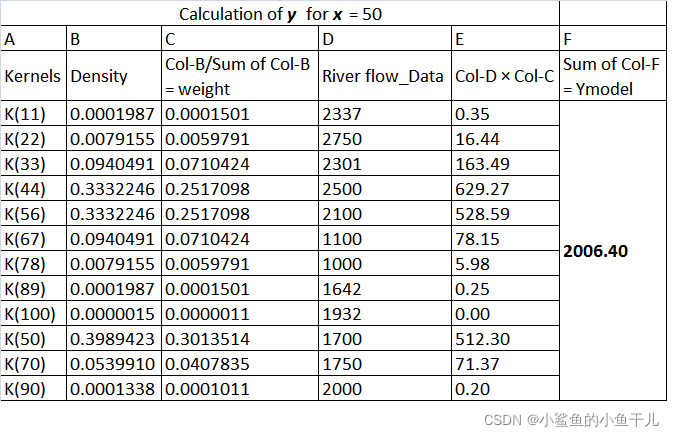
结合上面那个图,我们计算一下当 x i = 50 x_i=50 xi=50的时候,如何预测它对应的y值。所有的核曲线在 x i = 50 x_i=50 xi=50处的值就是上图中标星星的位置:

就用这些K值来计算权重,每一个K值都是在0~1之间(因为核函数的性质,上面提到了),计算权重的公式如下:
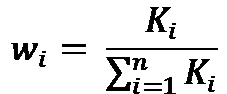
w i w_i wi就是输入数据i的权重,n是观测数据的总数,所以当 x i = 50 x_i=50 xi=50的时候,其预测对应的y值等于:

( y 11 y_{11} y11表示区域面积是11的时候的河流量, w 11 w_{11} w11是对应的权重,根据上面那个式子计算出来的)
具体的计算数据由下表给出:
同理,对于任何 x x x的值都由上面的过程估计,计算相应的 y y y值,就可以绘出下图:

到这里,关于核回归大家应该都了解清楚了,之前的疑惑应该也消失了。那么进入最后一个部分,带宽的影响。
四、带宽的影响
上面的计算是基于 h = 10 h=10 h=10的,带宽对于预测的效果时有很大影响的,下图显示了带宽等于5,10,15的效果:

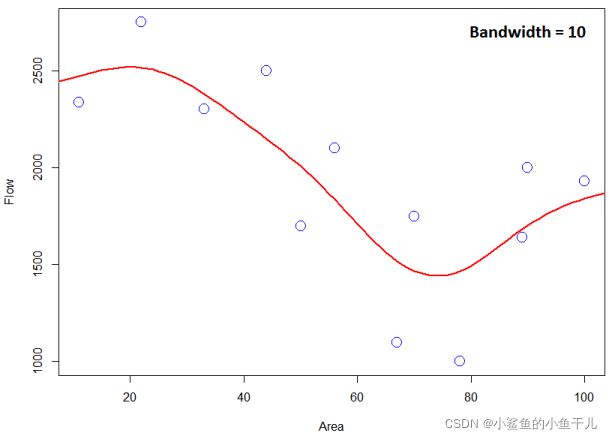
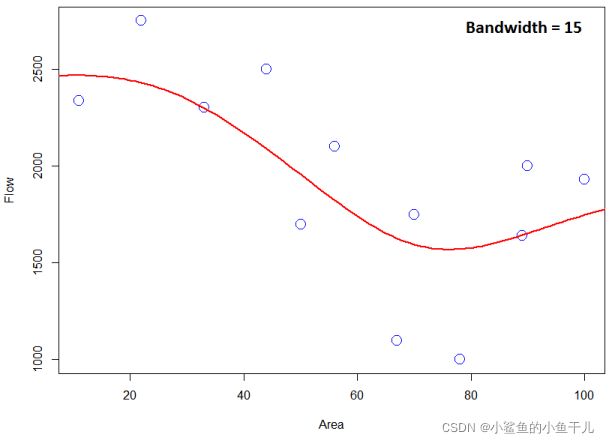
可以看到较小的带宽值会过拟合数据,因为带宽小,核曲线就会变窄,预测 x i x_i xi处的y值的时候, y i y_i yi会被赋予很高的权重,相当于核曲线只关注了与 x i x_i xi很近距离的y值,所以产生了过拟合。而当带宽过大时,预测曲线又会变得过渡平滑,欠拟合了没有办法表达出真实的输入与输出之间的关系。所以一般在核回归中带宽也是在回归过程中被优化的变量。
到这里,本文就结束了,希望可以帮助你。
参考:Kernel Regression