数据挖掘——时间序列算法之ARIMA模型
数据挖掘——时间序列算法之ARIMA模型
- 前言
- 差分定义
- ARIMA模型
- 实践
-
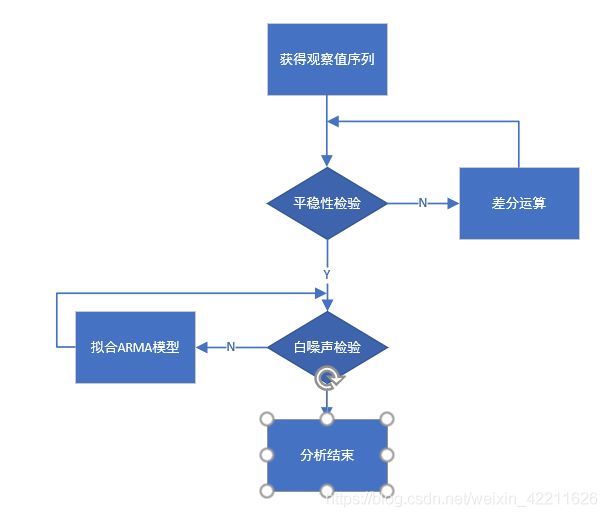
- 1、检验序列的平稳性
- 2、进行一阶差分后,进行平稳性和白噪声检验
- 3、对一阶差分之后的平稳非白噪声序列拟合ARMA模型
-
- 1)人为识别方法
- 2)相对最优模型识别
- 4、使用ARIMA预测
关于时间序列的其他模型,请参考本人的以下博文:
1、平滑法
2、趋势拟合法
3、组合模型
4、AR模型
5、MA模型
6、ARMA模型
7、ARIMA模型
8、ARCH模型
9、GARCH模型及其衍生模型
前言
前面几篇对平稳序列进行分析,然而实际上大多数时间序列都是非平稳的。对非平稳时间序列的分析方法可以分为确定性因素分解的时序分析和随机时序分析两个大类。
- 确定性因素分解的方法把所有序列的变化都归结为4个因素:长期趋势、季节变动、循环变动和随机波动。其中长期趋势和季节变动的规律性信息通常比较容易提取,而由随机因素导致的波动则非常难确定和分析,对随机信息浪费验证,会导致模型拟合精度差。
- 随机时序分析法的发展就是为了弥补确定性因素分解方法的不足。根据时间序列的不同特点,随机时序分析可以建立的模型有ARIMA模型、残差自回归模型、季节模型、异方差模型。
差分定义
相距d期的两个序列值之间的减法运算称为d阶差分运算。(定义这个是为了后面用)
ARIMA模型
ARIMA模型(Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),是时间序列预测分析方法之一
许多非平稳序列差分后会显示出平稳序列的性质,这时非平稳序列为差分平稳序列。对差分平稳序列就可以使用ARMA模型进行拟合了。
ARIMA的数学表达:
x t = μ + φ 1 ∗ x t − 1 + . . . + φ p ∗ x t − p + θ 1 e t − 1 − . . . − θ q e t − q x_{t}= \mu + \varphi_{1}* x_{t-1}+ ...+ \varphi_{p}* x_{t-p} + \theta_{1}e_{t-1}-...-\theta_{q}e_{t-q} xt=μ+φ1∗xt−1+...+φp∗xt−p+θ1et−1−...−θqet−q
很明显哈,ARIMA的实质就是差分运算与ARMA模型的结合。其中, φ \varphi φ是AR模型的参数, θ \theta θ是MA模型的参数。
关于ARIMA的计算方法,这里有一篇比较好的博客,我这里就臭不要脸的在他的上面截图了:

 上面的例子可以很好的帮助理解ARIMA模型。
上面的例子可以很好的帮助理解ARIMA模型。
差分平稳时间序列建模步骤:
实践
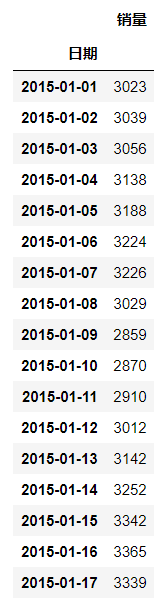
先查看数据长什么样
import pandas as pd
data = pd.read_excel( './data/arima_data.xls', index_col = u'日期')
data
1、检验序列的平稳性
1)画个趋势图,检验序列的平稳性
#时序图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
data.plot()
plt.show()
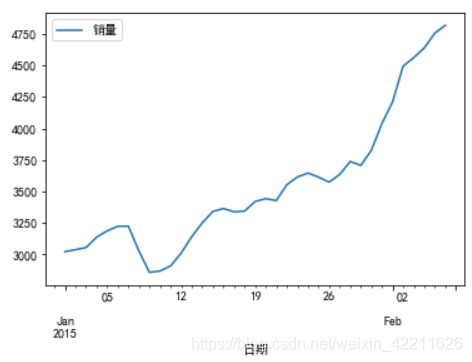
从原始数据的趋势图中很明显的看出,该序列具有单调递增趋势,可以判断为是非平稳数据。
2)再看下原始数据的自相关图
#自相关图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data).show()
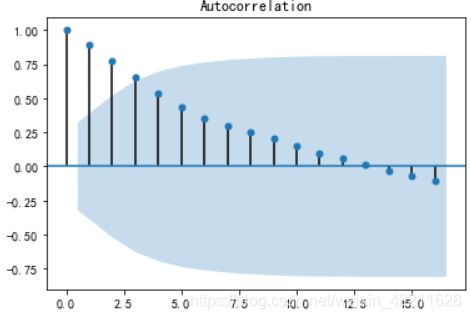 上面的自相关图显示自相关系数长期大于0,说明序列间具有很强的长期相关性。
上面的自相关图显示自相关系数长期大于0,说明序列间具有很强的长期相关性。
3)再来看原始数据的单位根检验
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))
#返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore
结果如下:
![]() 整理成表格:
整理成表格:
| ADF | cValue | p值 |
|---|---|---|
| 1.8138 | 1%:-3.7112;5%:-2.9812;10%:-2.6301 | 0.9984 |
结论:上表中表明,单位根检验统计量对应的p值显著大于0.05,最终将该序列判断为非平稳序列,并且非平稳数据一定不是白噪声数据。
2、进行一阶差分后,进行平稳性和白噪声检验
1)对一阶差分后的序列再次做平稳性判断
#差分后的结果
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
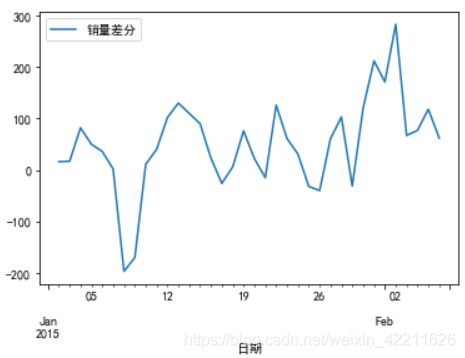
D_data.plot() #时序图
plt.show()
2)自相关图
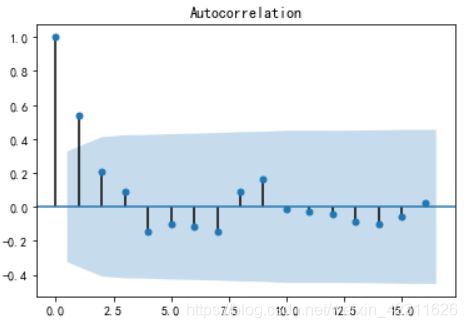
plot_acf(D_data).show() #自相关图
3)单位根检验
print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) #平稳性检测
![]()
| ADF | cValue | p值 |
|---|---|---|
| -3.1561 | 1%:-3.6327;5%:-2.9485;10%:-2.6130 | 0.0227 |
结果显示:
- 一阶差分后的序列的时序图在均值附近比较平稳的波动
- 自相关图有很强的短期相关性
- 单位根检验p值小于0.05
结论:一阶差分之后的序列是平稳序列。
上面已经证明了一阶差分后的序列是平稳序列了,那么就需要对该平稳的一节差分做白噪声检验:
#白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) #返回统计量和p值
![]()
| stat | p值 |
|---|---|
| 11.304 | 0.007724 |
结论:输出的p值小于0.05,所以一阶差分之后的序列是平稳非白噪声序列。
3、对一阶差分之后的平稳非白噪声序列拟合ARMA模型
下面进行模型定阶,也就是确定ARMA的p和q。
这里有两种方法可以确定出p和q,即人为识别的方法和相对最优模型识别。
1)人为识别方法
使用该方法确定p和q时,一定要知道AR模型和MA模型的性质,这在我的博文里面有说,详见本文开始部分处的链接。
回顾下一阶差分后的自相关图:
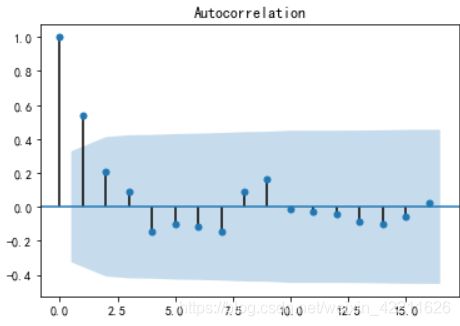 可见一阶差分后的自相关图显示出了1阶截尾 (记为结论1)
可见一阶差分后的自相关图显示出了1阶截尾 (记为结论1)
再看一阶差分后的偏自相关图:
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(D_data).show() #偏自相关图
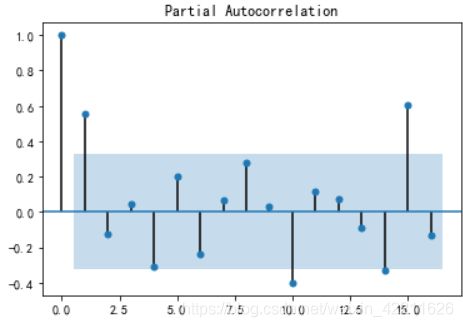
可见一阶差分后的偏自相关图显示出了拖尾性 (记为结论2)
(关于截尾和拖尾,看此篇文章,或者简要的看下下面的图)
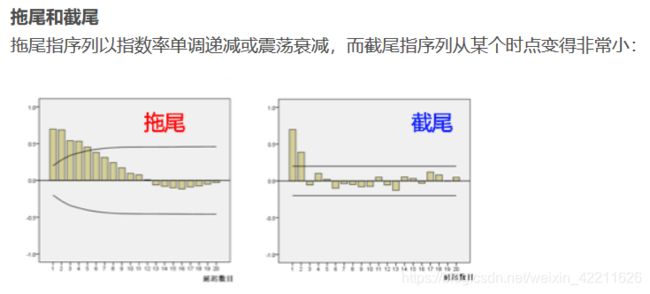
综合结论1和结论2 ,可以考虑用MA(1)模型拟合1阶差分后的序列,即对袁术序列建立ARIMA(0,1,1)模型。
2)相对最优模型识别
使用该方法必须了解BIC和AIC的含义,可以看此篇文章:ARIMA模型原理及实现,这块截一段主要介绍:

计算ARMR(p,q)。当p和q均小于等于3的所有组合的BIC信息量,取其中BIC信息量达到最小的模型阶数。
from statsmodels.tsa.arima_model import ARIMA
data[u'销量'] = data[u'销量'].astype(float)
#定阶
pmax = int(len(D_data)/10) #一般阶数不超过length/10
qmax = int(len(D_data)/10) #一般阶数不超过length/10
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(data, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值
bic_matrix
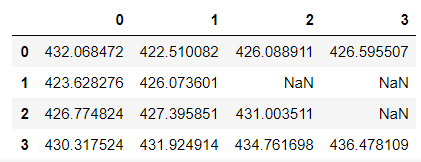 可以看到在p=0,q=1的时候BIC是最小的,为422.51…。用下面的代码找出
可以看到在p=0,q=1的时候BIC是最小的,为422.51…。用下面的代码找出
p,q = bic_matrix.stack().idxmin() #先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
![]()
4、使用ARIMA预测
上面已经得到了p=0,q=1,那么就应用ARIMA(0,1,1)对原始数据即某餐厅的显瘦数据作为为期5天的预测。
model = ARIMA(data, (p,1,q)).fit() #建立ARIMA(0, 1, 1)模型
model.summary2() #给出一份模型报告
model.forecast(5) #作为期5天的预测,返回预测结果、标准误差、置信区间。
预测结果如下:
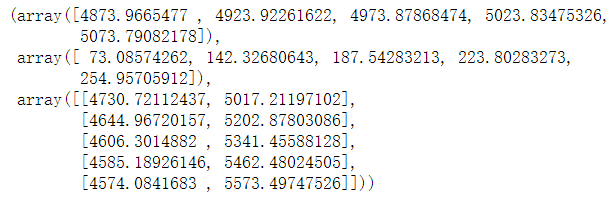
需要注意:利用模型向前预测的时期越长,预测误差将会越大,这是时间预测的典型特点。