论文阅读笔记:图卷积网络
Cite: SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
https://arxiv.org/abs/1609.02907
摘要
我们提出了一种可扩展的图结构数据半监督学习方法,该方法基于直接操作于图的卷积神经网络的有效变体。我们通过谱图卷积的局部一阶近似来激励卷积结构的选择。我们的模型在图边的数量上线性伸缩,并学习对局部图结构和节点特征进行编码的隐藏层表示。
1 简介
我们考虑在图中对节点进行分类的问题,其中有标签仅适用于小的节点子集。这个问题可以被定义为基于图的半监督学习,其中标签信息通过某种形式的基于图的显式正则化在图上平滑,例如通过在损失函数中使用图拉普拉斯正则化项:
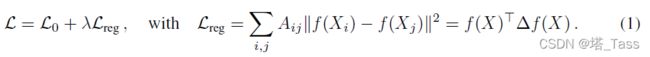
这里,![]() 表示有监督损失。
表示有监督损失。 可以是一个类似可微函数的神经网络,
可以是一个类似可微函数的神经网络, 是加权因子,
是加权因子, 是节点特征向量
是节点特征向量 组成的矩阵。
组成的矩阵。![]() 表示无向图
表示无向图![]() 的非规范化的图Laplacian。等式1的公式依赖于图中连接节点可能共享同一标签的假设。然而,这种假设可能会限制建模能力,因为图的边不一定需要编码节点相似性,而可能包含其他信息 。
的非规范化的图Laplacian。等式1的公式依赖于图中连接节点可能共享同一标签的假设。然而,这种假设可能会限制建模能力,因为图的边不一定需要编码节点相似性,而可能包含其他信息 。
在这项工作中,我们直接使用神经网络模型![]() 对图结构进行编码,并针对所有带标签的节点在监督目标
对图结构进行编码,并针对所有带标签的节点在监督目标![]() 上进行训练,从而避免损失函数中基于图的显式正则化。在图的邻接矩阵上调节将允许模型从监督损失
上进行训练,从而避免损失函数中基于图的显式正则化。在图的邻接矩阵上调节将允许模型从监督损失![]() 中分布梯度信息,并使其能够学习带标签和不带标签的节点表示。
中分布梯度信息,并使其能够学习带标签和不带标签的节点表示。
2 图的快速近似卷积
在本节中,我们将为基于图的神经网络模型![]() (其中X即数据本身,A为表示数据点对联系的邻接矩阵)提供理论依据,我们将在本文的其余部分中使用该模型。我们考虑多层图层卷积网络(GCN),具有如下分层传播规则:
(其中X即数据本身,A为表示数据点对联系的邻接矩阵)提供理论依据,我们将在本文的其余部分中使用该模型。我们考虑多层图层卷积网络(GCN),具有如下分层传播规则:

其中![]() 为加上了连接自己的邻接矩阵(因为加上
为加上了连接自己的邻接矩阵(因为加上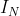 表示以1的权重用自己线性表出自己),其中
表示以1的权重用自己线性表出自己),其中![]() 是
是![]() 的度矩阵,
的度矩阵,![]() 是可训练的权重矩阵,
是可训练的权重矩阵,![]() 是激活函数,
是激活函数,![]() 是来自上一层的激活后的输出,
是来自上一层的激活后的输出,![]() 。在下文中,我们证明了这种传播规则的形式可以通过图的局部谱滤波器的一阶近似来激发。
。在下文中,我们证明了这种传播规则的形式可以通过图的局部谱滤波器的一阶近似来激发。
2.1 谱图卷积
我们考虑图上的谱卷积定义为信号![]() (每个结点的标量)与傅立叶域中用
(每个结点的标量)与傅立叶域中用![]() 参数化的滤波器
参数化的滤波器![]() 的乘积,即:
的乘积,即:
![]()
其中,U表示标准化图拉普拉斯的特征向量组成的矩阵,即![]() ,
, 为特征值组成的对角阵。那么
为特征值组成的对角阵。那么![]() 为对
为对 的图傅里叶变换,
的图傅里叶变换,![]() 则可以认为是对L的特征值进行拟合的函数。这在计算上很昂贵,因为与特征向量矩阵U的乘积为
则可以认为是对L的特征值进行拟合的函数。这在计算上很昂贵,因为与特征向量矩阵U的乘积为![]() 复杂度。此外,对于大型图来说,首先计算L的特征分解代价高昂。为了避免这个问题,Hammond et al.提出,
复杂度。此外,对于大型图来说,首先计算L的特征分解代价高昂。为了避免这个问题,Hammond et al.提出,![]() 可以通过切比雪夫多项式
可以通过切比雪夫多项式![]() 的截断展开式很好地逼近到第k阶:
的截断展开式很好地逼近到第k阶:

其中![]() 是一种缩放,
是一种缩放,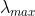 为图拉普拉斯的最大特征值。
为图拉普拉斯的最大特征值。![]() 现在是切比雪夫系数的向量。切比雪夫多项式被递归地定义为:
现在是切比雪夫系数的向量。切比雪夫多项式被递归地定义为:![]() ,其中
,其中![]() 。现在回到谱图卷积的定义,我们有了信号x和近似后的滤波器
。现在回到谱图卷积的定义,我们有了信号x和近似后的滤波器![]() :
:

其中![]() ,这是显然的,因为
,这是显然的,因为![]() 。注意到上式是K阶近邻局部化的(因为这里是K阶截断近似),即它仅取决于离中心节点最大K步的那些节点。此时复杂度为
。注意到上式是K阶近邻局部化的(因为这里是K阶截断近似),即它仅取决于离中心节点最大K步的那些节点。此时复杂度为![]() ,即与边的数量呈线性关系。
,即与边的数量呈线性关系。
2.2 Layer-wise线性模型
因此,基于图卷积的神经网络模型可以通过叠加多个切比雪夫近似形式的卷积层来建立,每一层后面都是逐点非线性。现在,假设我们将逐层卷积运算限制为K=1(见上式),即L上的线性函数。
通过这种方式,我们仍然可以通过叠加多个这样的层来恢复丰富的卷积滤波函数类,但我们不限于切比雪夫多项式等给出的显式参数化。这种分层线性公式允许我们构建更深层次的模型,这一实践已知可以提高许多领域的建模能力。
在GCN的线性模型中,我们进一步近似![]() (规范化图拉普拉斯最大特征值约为1,再加上self-loop的单位阵于是为2)。在这些近似下,图卷积简化为:
(规范化图拉普拉斯最大特征值约为1,再加上self-loop的单位阵于是为2)。在这些近似下,图卷积简化为:
![]()
这里有两个自由变量![]() 和
和 ![]() ,可以共享权重,令
,可以共享权重,令![]() 有:
有: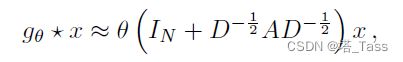
![]() 取值范围在[0,2],在深度模型多次应用该图卷积算子的时候导致代数不稳定和梯度爆炸、消失。通过重规范化的技巧:
取值范围在[0,2],在深度模型多次应用该图卷积算子的时候导致代数不稳定和梯度爆炸、消失。通过重规范化的技巧:![]() ,
,
其中 ![]() ,
,![]() 。于是重规范化后变为:
。于是重规范化后变为:
![]()
这便是k=1阶的第一层卷积。其中输入信号![]() ,滤波器参数
,滤波器参数![]() ,卷积后
,卷积后![]() 。该滤波器的计算复杂度为
。该滤波器的计算复杂度为![]() 。
。
3 半监督节点分类
引入了一个简单但灵活的模型来实现图的有效信息传播,我们可以回到半监督节点分类问题。正如引言中所概述的,我们可以通过在数据X和底层图结构的邻接矩阵A上调节我们的模型,来放松基于图的半监督学习中通常做出的某些假设。我们预计,在邻接矩阵包含数据X中不存在的信息的情况下,这种设置尤其强大,例如引用网络中文档之间的引用链接或知识图中的关系。整体模型是一个用于半监督学习的多层GCN,如图1所示。
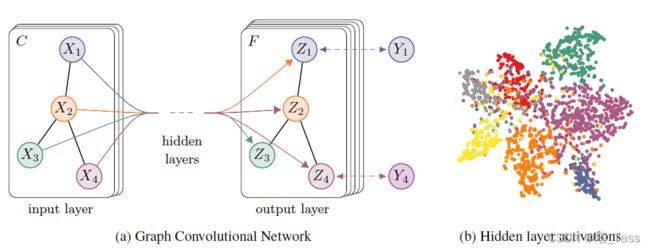
3.1 举例
以两层GCN为例,我们有对称邻接矩阵A,在预处理步骤我们首先计算![]() ,前向传播为:
,前向传播为:
![]()
其中![]() 为每层的权重矩阵,然后我们用交叉熵对所有有标签的节点计算损失:
为每层的权重矩阵,然后我们用交叉熵对所有有标签的节点计算损失:
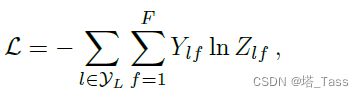
其中![]() 为有标签的数据点index组成的集合。采用梯度下降法训练神经网络权值。在这项工作中,我们在每次迭代中加载整个数据集执行梯度下降。A为用稀疏表示时,内存需求为
为有标签的数据点index组成的集合。采用梯度下降法训练神经网络权值。在这项工作中,我们在每次迭代中加载整个数据集执行梯度下降。A为用稀疏表示时,内存需求为![]() ,即与边数线性相关。培训过程中的随机性是通过dropout引入的。我们将使用小批量随机梯度下降的高效内存扩展留给未来的工作。
,即与边数线性相关。培训过程中的随机性是通过dropout引入的。我们将使用小批量随机梯度下降的高效内存扩展留给未来的工作。
4 相关工作
略
5 实验
5.1 数据集

5.2 实验设置
默认使用双层GCN(事实上,由于退化问题和近邻搜索范围爆炸,GCN根本深不了),并在1000个标记示例的测试集上评估预测精度。我们在附录中使用了多达10层的更深层模型(见下图)。我们仅在Cora上优化超参数,并对Citeser和Pubmed使用相同的参数集。我们使用Adam对所有模型进行最多200个epoch的训练,学习率为0.01,为防止过拟合,Early stop=10,也就是说,如果连续10个阶段的验证损失没有减少,我们将停止训练。我们使用Glorot&Bengio中描述的初始化来初始化权重,并相应地(行)规范化输入特征向量。

5.3 Baseline
略
6 实验
6.1 半监督分类
报告的数字以百分比表示分类准确率。对于ICA,我们报告了随机节点排序的100次运行的平均精度。所有其他基线方法的结果取自Planetoid论文(Yang等人,2016)。Planetoid*表示在论文中给出的变量中,各个数据集的最佳模型。

此外,我们报告了我们的模型在10个随机抽取的数据集分割上的性能,这些数据集分割的大小与Yang等人(2016)中的相同,用GCN(rand.splits)表示。
6.2 传播模型的选择
我们在引文网络数据集上比较了我们提出的每层传播模型的不同变体。我们遵循上一节描述的实验设置。结果汇总在表3中。原始GCN模型的传播模型用重标准化技巧(粗体)表示。在所有其他情况下,两个神经网络层的传播模型均替换为传播模型下指定的模型。报告的数字表示随机权重矩阵初始化的100次重复运行的平均分类精度。在每层有多个变量![]() 的情况下,我们对第一层的所有权重矩阵施加L2正则化。
的情况下,我们对第一层的所有权重矩阵施加L2正则化。

6.3 每次迭代训练时间
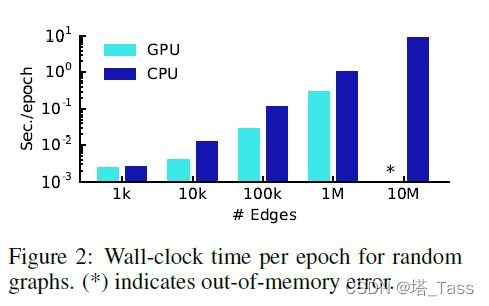
7 讨论
7.1 半监督模型
在这里演示的实验中,我们的半监督节点分类方法比最近的相关方法有很大的优势。基于图拉普拉斯正则化的方法很可能受到限制,因为它们假设边只编码节点的相似性。另一方面,基于Skip-gram的方法由于基于一个难以优化的多步骤流水线而受到限制。我们提出的模型可以克服这两个局限性,同时在效率方面仍优于相关方法。与ICA(等只聚合标签信息的方法相比,从每一层的相邻节点传播特征信息可以提高分类性能。我们进一步证明,与一阶朴素模型(等式6)或使用切比雪夫多项式的高阶图卷积模型(等式5)相比,所提出的重标准化化传播模型(等式8)在许多数据集上提供了更高的效率(更少的参数和操作,如乘法或加法)和更好的预测性能。
7.2 局限性
内存需求。在当前的全批量梯度下降设置中,内存需求随着数据集的大小线性增长。小批量随机梯度下降可以缓解这个问题。然而,生成小批量的过程应考虑GCN模型中的层数,因为对于一个精确的过程,必须将具有K层的GCN的第K阶邻域存储在内存中。对于非常大且紧密连接的图形数据集,可能需要进一步的近似。
限制性假设。通过第2节中介绍的近似,我们隐式地假设了局部性(对于具有K层的GCN,依赖于第K阶邻域)以及自连接与相邻节点的边的同等重要性。然而,对于某些数据集,在![]() 的定义中引入一个折衷参数可能是有益的:
的定义中引入一个折衷参数可能是有益的:![]()
在典型的半监督设置中,该参数现在起着与监督损失和非监督损失之间的权衡参数类似的作用(见等式1)。然而,在这里,它可以通过梯度下降来学习。