Vision Transformer 模型详解
目录
- 前言
- 模型结构
- 实验
- 总结
- Question Summary
前言
虽然说transformer已经是NLP领域的一个标准:BERT模型、GPT3或者是T5模型,但是当年
Vision transformer 提出时用transformer来做CV还是很有限的; 在视觉领域,自注意力要么是跟
卷积神经网络一起使用,要么用来把某一些卷积神经网络中的卷积替换成自注意力,但是还是保持
整体的结构不变; ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,因为其
模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域
应用的里程碑著作,也引爆了后续相关研究。
模型结构
作者将transformer结构去除掉decoder部分后经过改进将其运用到视觉领域。vision transformer模型结构主要包括三部分:
- patch embeding 部分
- transformer encoder部分
- MLP head部分。
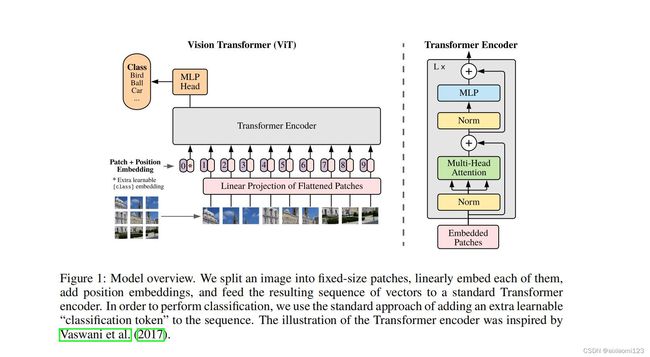
整个模型结构可以分为五个步骤进行:
1、将图片切分成多个patch。
2、将得到的patches经过一个线性映射层后得到多个token embedding。
3、将得到的多个token embedding concat一个额外的CLS token,然后和位置编码相加,构成完整的encoder模块的输入。
4、 将相加后的结果传入Transformer Encoder模块。
5、Transformer Encoder 模块的输出经过MLP Head 模块做分类输出。
Transformer Block:
- Layer Norm层:标准归一化,为了更好的收敛。
- MHA层:多头自注意力机制
- 输入和输出做残差连接
- Layer Norm
- MLP层: Linear + GRLU +Linear +Dropout
L个Transformer Block 构成一个完整的Transformer Encoder模块。经过Transformer Block 后维度不变。
实验

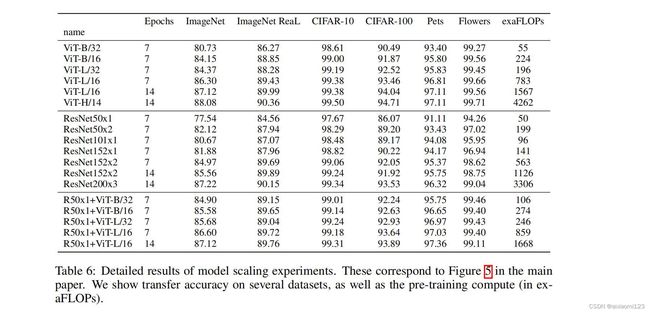
给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在Google自家的JFT数据集上进行了预训练),说明Transformer在CV领域确实是有效的。
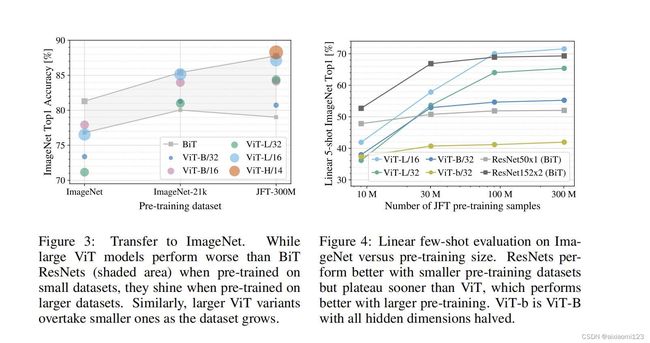
用vision transformer 模型和卷积神经网络(resnet)做了对比,实验发现在中小数据集上,
卷积神经网络的效果比vit模型的效果要好(原因在Question Summary)。随着数据及规模的增大,
ViT模型的效果要逐渐优于卷积神经网络的效果。
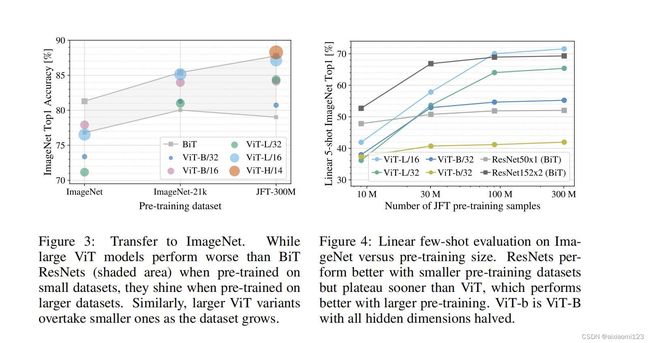
用vision transformer 模型和卷积神经网络(resnet)以及Hybrid结构(混合结构)做了对比,
结果相同,同时Hybrid结构在中小型数据集上也能够达到能好的性能(毕竟结合了卷积神经网络和
Transformer的优点),但随着数据集的增大,发现Transform的结构要比Hybrid结构性能优秀。
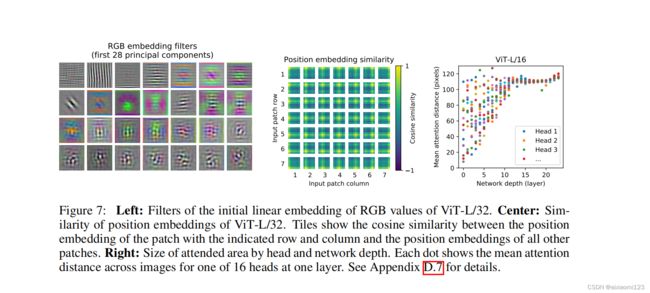


作者还做了关于自注意力机制的实验,从实验结果我们可以看出,模型可以很好的利用自注意力机制学习到图片的特征。
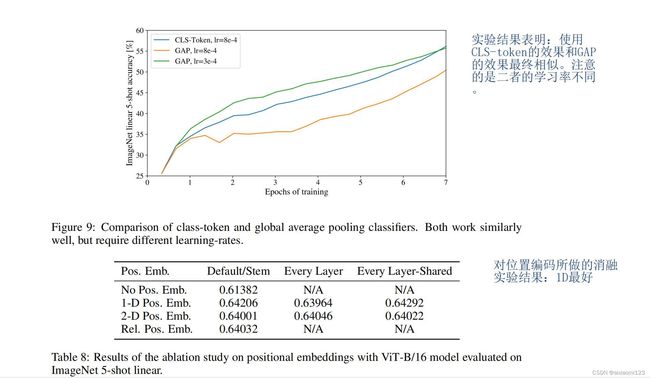
做了关于CLS Token和GAP以及关于不同维度的消融实验。ViT模型最后利用CLS Token做分类预
测,而卷积神经网络则是利用GAP(全局平均池化),从实验结果可以看出,CLS Token 可以和
GAP 达到同样的效果,但是要求不同的学习率。
总结
如果在足够多的数据上做预训练,也可以不需要卷积神经网路,直接使用标准的Transformer也能够
把视觉问题解决的很好;尤其是当在大规模的数据上面做预训练然后迁移到中小型数据集上面使用的
时候,Vision Transformer能够获得跟最好的卷积神经网络相媲美的结果。
Question Summary
在中小型数据集上,ViT模型不如卷积神经网络的原因:
卷积神经网络存在归纳偏置:locality 和translation equivariance。有了归纳偏置后,就有了先验知识,可以利用较少的数据去学习一个比较好的模型,而transformer没有先验知识,所以需要数据自己学习,所以在大数据集上的性能比中小数据集上。
位置编码:
如果不标注位置,在Transform看来图片就是一样的,所以需要加上位置编码。
CLS Token:
在NLP的分类任务中,被看作一个全局的对句子的理解,在这里可以看作一个图像的整体特征。
MLP Head:
一个通用的分类头,最后用交叉熵函数进行模型的训练。
论文:原论文链接
代码:pytorch代码