李宏毅机器学习笔记——Anomaly Detection(异常侦测)
目录
异常检测概述
Anomaly Detection分类
异常侦测不是一个单纯的二元分类问题
两种类别
数据存在标签
训练
验证集和评估分类model
Possible Issues
Without label(无标签的数据)
问题定义
具体做法
Auto-encoder做异常检测
总结
异常检测概述
对于异常检测任务来说,我们希望能够通过现有的样本来训练一个函数,它能够从数据中学习到某些正常的特征,根据输入与现有样本之间是否足够相似,诊断出非正常的数据。

数据的正常和异常,取决于训练资料是什么,并没有特定谁是异常的,不是说异常就一定是不好的东西

通常来说,Anoamly Detector在不同的领域里面有不同名字,也被叫做Novelty Detection,Outlier Detection,Forgery Detection,Out-of-distribution Detection。
应用
异常检测应用广泛,实际应用场景有:诈骗侦测、网络入侵检测、癌细胞检测。
- 诈欺侦测(Fraud Detection)。训练数据是正常的刷卡行为,收集很多的交易记录,这些交易记录视为正常的交易行为,若今天有一笔新的交易记录,就可以用异常检测的技术来侦测这笔交易记录是否有盗刷的行为。(正常的交易金额比较小,频率比较低,若短时间内有非常多的高额消费,这可能是异常行为)
- 网络系统的入侵侦测,训练数据是正常连线。若有一个新的连线,你希望用Anoramly Detection让机器自动决定这个新的连线是否为攻击行为
- 医疗(癌细胞的侦测),训练数据是正常细胞。若给一个新的细胞,让机器自动决定这个细胞是否为癌细胞。

异常侦测不是一个单纯的二元分类问题
最简单的想法就是Binary Classification,它是收集一组正常的数据和一组异常的数据,将正常的资料标记为class 1,异常资料作为class 2,然后让机器一起训练一个二分类的分类器。
但实际上是很难按照这样的做法来实现的:
- 只要是非正常的都是异常,变化太大,没有办法将异常数据全部收集齐全,没有办法知道整个异常的数据(Class2)是咋样的,所以不应该将异常的数据视为一个类别。
- 对于正常的数据收集是比较简单的,但对于异常数据的收集通常是较难的
Anomaly Detection两种类别
第一类:给定一组训练数据,并且带有某种类型的label,使用这些数据先训练一个classifier。数据和label中并没有unknown,但是期望classifier有能力知道新给定的训练数据不在原本的训练数据中,会给新的训练数据贴上“unknown”的标签。也被称为Open-set Recognition。
第二类:所有的训练数据都是没有标签的,通过相似度来判断异常数据。这里面又分两种情况:
- clean: 所有数据都是正常数据
- polluted: 训练资料已经被混杂了一些异常的资料
数据存在标签
训练
给定一组Simpsons家族人物的数据,并且这些数据都是有label的,训练一个Simpsons的家族分类器,输入人物图片,输出名字。可以使用这个Classifier来做异常侦测,输入一个人物,判断其是否属于Simpsons家庭。


输入x 之后,分类model输出一个分布,将该分布的最大值作为信心分数c(x),和设置的阈值λ 进行比较,判断是否异常,小于则是异常,大于则是正常。

当输出分布比较集中,最高的分数比较高的时候就是正常;分布比较平均,最高分数比较低就是异常。

也可以将输出向量看成一个概率分布,然后计算该概率分布的交叉熵entropy, 交叉熵越大就代表输出越平均,代表机器没有办法去肯定输出的图片是哪个类别,表示输出的信心分数是比较低。上面的例子中就是第一个的信息熵很小,第二个的信息熵很大,那么我们就要设定小于阈值才是正常的,大于才是不正常的。
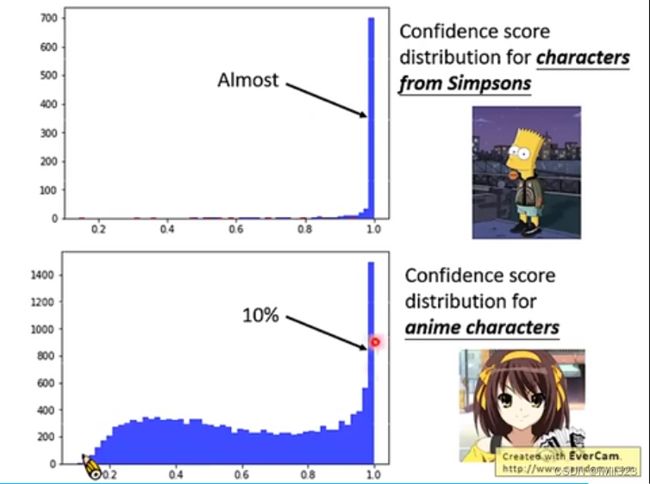
下面是该分类器的分类结果。如果输入的是辛普森家庭的人物,分类器输出比较高信心分数。如果输入不是辛普森家庭的任务,分类器输出的信心分数是比较低,只有10%的异常图片信心分数高
验证集和评估分类model
训练之后,通过Dev Set(验证集)衡量异常侦测系统的性能,调整模型的超参数——阀值(threshold),防止在测试集上过拟合。Dev Set要模仿测试数据集,即要包含正常数据,也要包含异常数据,且带有对应的标签(标签只要说明是与否就行了)。
如何计算一个异常侦测性能的好坏?
因为样本不均衡的原因,所以衡量分类器的好坏通常不用正确率这个指标。假设现有100张正常simpsons家族图片和5张其他动漫图片,得到了以下结果。蓝色表示simpsons家族的得分,红色表示其他动漫的得分。阈值λ设置在0.3时,负样本只有5个,如果计算model的正确率有0.952,正确率很高,但明显该系统并不好。

在异常侦测的问题里会有两种错误:将正常的检测为异常的和将异常的检测为正常的。
设置不同的阈值λ得到不同的分布矩阵。假设阈值λ设置在0.5:
将λ设为0.5,可以得到如下矩阵

将阀值(threshold)切在比0.8稍高的部分:

如何评价这种分类结果的好坏,主要取决于更在意missing还是更在意false alarm,哪一种更严重就设置更高的惩罚,从而评估取不同λ时系统的好坏。
Cost table A:正常的资料误判成异常扣100分(即false alarm),异常的资料没有被侦测到(即missing )扣1分
Cost table B :异常的资料没有被侦测到扣100分,正常的资料被误判成异常扣1分

即可以根据实际情况进行权重的调整。不同的任务,计算cost的方式也不一样。
ROC AUC score
还有很多衡量异常检测系统的指标,有一个常用的指标为Area under ROC curve。若使用这种衡量的方式,就不需要决定阀值(threshold),而是将测试集的结果做一个排序(高分至低分),根据这个排序来决定这个系统好还是不好。
为什么使用ROC AUC score
如果使用accuracy,就需要一个threshold来决定图像是否异常。这样就需要对一个模型尝试很多threshold,来确定一个最满意的accuracy。但是我们只想要让模型说明,一个图像有多异常,它只需要在各个threshold上取得最高的平均分数
计算方法
下图红色和绿色的线分别是异常样本和正常样本的分布。对于红色分布,threshold右侧部分所占比例是true positive rate(TPR),对于绿色分布,threshold右侧部分所占比例是false positive rate(FPR)。对于每一个threshold,都有这样一对数值,改变threshold的数值,将TPR和FPR画在二维图上就是右侧曲线

一个好的模型应该让异常样本的异常得分高,让正常样本的异常得分低,这代表正常样本分布和异常样本分布之间的间隔要大(如下图),计算ROC curve下方的距离,用来衡量模型好坏


举例
将预测结果做一个排序(高分至低分)

对于不同的threshold,分别计算true positive和false positive的数量

将true positive和false positive均一化,画出来后计算曲线下方的面积,就是ROC AUC score

Possible Issues
用分类系统来对输入做异常侦测可能会遇到问题。两种图片的“相似”与否应该看全方面的特征,但是分类系统可能只学习到正常样本的某种特别明显的标签,于是可能会把异常样本看成正常样本。比如假设有一个classifier,可以区别猫和狗。classifier对于输入比如食蚁兽和羊驼来说,机器不知道该放在哪一边,就可能放在这个boundary上,得到的信息分数就比较低,你就知道这些资料是异常的。但是对于老虎和狼,在猫和狗的特征上特别强烈,会给分类器很大的信心看到某一种类别。

比如只学习到辛普森家族的人物的脸都是黄色的,下面将异常样本涂成黄色,可以得到很高的信心分数

解决方法:
- 这个问题的根本原因可能是异常样本实在是太少了。首先让机器看到正常资料时不要只做分类这件事情,要学会一边做分类,一边看到正常的资料信心分数就高,看到异常的资料就要给出低的信心分数。
- 一般是很难收集到大量异常数据的,考虑使用生成器(如GAN)生成一些异常资料。遇到的问题是:生成的资料太像正常的资料,所以生成模型中也要加一些特别的constraint,让生成的资料有点像正常的资料,但是又跟正常的资料又没有很像。

Without label(无标签的数据)
问题定义
只能够收集到一些资料,但没有这些资料的label。根据样本数据,应用极大似然估计的方法,求出样本的概率密度函数,正常的样本在该分布中得到的概率就高,异常的样本概率就低,设置一个阈值将正常和异常的样本区分开。
举例一个游戏,假设大部分玩家都希望完成这个游戏(也就是说大部分都是正常数据),而这部分数据我们会用来训练。然后我们使用异常检测,找出其中的“恶意玩家”(即异常数据)。
具体做法
把用户表示成一个向量,向量中的每一项可以表示这个用户的一种行为。使用一个几率函数P来判断是否异常样本
由于玩家的行为是可以统计的,假设有两个维度,可以获得不同玩家行为的概率分布。

假设给定一种概率密度函数fθ(x)可以描述数据的分布,其参数θ(指代所有的参数)是未知的,那么可以通过极大似然估计来获取参数的值。选择不同的 θ 值可以算出不同的似然值,而我们需要一组θ 使得似然最大。(若严格说的话,fθ(x)并不是几率,它的output是probability density;输出的范围也并不是(0,1),有可能大于1)

上面是只是一个抽象的说法。假设概率密度函数 fθ(x)为常用的高斯分布,参数是均值和协方差矩阵,也就是我们关注的θ参数。计算极大似然值,得到最佳的均值和方差:


现在有了计算好的概率密度函数可以使用概率值来计算了,若落在颜色深的红色区域,就说明算出来的数值越大,越是一般的玩家,颜色浅的蓝色区域,就说明这个玩家的行为越异常,λ在图上就是一条等高线。

以上的例子只是使用了两个特征,也就是输入向量x只是二维;machine learning最厉害的就是让machine做,所以你要选择多少feature都可以,把能想到觉得跟判断玩家是正常的还是异常的feature加进去

当然这里有一个非常强的假设,即数据分布满足高斯分布。实际上一般也不见得满足,但是高斯分布用的十分广泛,有人说人的很多行为都是满足高斯的,即使不是,也很类似,所以基本上用高斯的效果都还不错。如果fθ(x)是一个非常复杂的function(network),而操控这个network的参数有非常大量,那么就不会有那么强的假设了,就会有多的自由去选择function来产生资料。这样就不会限制在看起来就不像Gaussian产生的资料却硬要说是Gaussian产生的资料。
极大似然估计部分可以参考:李宏毅机器学习笔记-生成模型和逻辑回归_iwill323的博客-CSDN博客
Auto-encoder做异常检测
用训练数据去训练一个auto-encoder来做异常检测,可以根据对图片的还原度来判断是否为异常数据。
如果这张图片是一个正常的照片,很容易被还原为正常的图片。

但是若你输入异常的图片,通过Encoder变为code,再通过Decoder将coede解回原来的图片时,你会发现无法解回原来的图片。解回来的图片跟输入的图片差很多时,这时你就可以认为这是一张异常的图片。

Auto-encoder参考: 李宏毅机器学习--self-supervised:BERT、GPT、Auto-encoder_iwill323的博客-CSDN博客
machine learning中也有其它做异常侦测的方法,比如SVM的One-class SVM,只需要正常的资料就可以训练SVM,然后就可以区分正常的还是异常的资料。在Random Forset的Isolated Forest,它所做的事情跟One-class SVM所做的事情很像(给出正常的训练进行训练,模型会告诉你异常的资料是什么模样)。

总结
本章是在介绍Anomaly Detection(异常侦测)的问题定义与分类,以及不同的类应用不同方法去做Anomaly Detection。先考虑用二元分类器去做Anomaly Detection(异常侦测),但是由于异常数据并不都是一种类型,并且对于收集大量异常数据是较难的,所以这个方法是不行的。其次对于有标签的训练数据,应用的分类器模型是输出标签y同时输出一个信心分数。然后对于无标签的训练数据,假设数据分布满足Gaussian Distribution,即可方便的计算出其概率密度函数,做异常侦测便可较为直观。
参考:LeeML-Notes
2020李宏毅机器学习笔记——24. Anomaly Detection(异常侦测)_HSR CatcousCherishes的博客-CSDN博客