深度半监督学习笔记(三):一致性正则化
前几天更新了一致性正则化的前五种方法,我们可以看到整个模型也在不断的进步,从单纯的对噪声进行学习以增强网络的鲁棒性到应用对抗学习的一些知识。现在我们对之前的知识做简要的总结:
- Ladder Networks:简单的加入了编码-解码层,通过加入噪声来预测未加噪声层的输出来增强网络的鲁棒性。
- Pi-model:通过dropout作为噪声源,利用了网络的dropout随机性使得网路更加强壮。
- Temporal Ensembling:加入了指数平均法,使得网络能对之前训练的输出有所响应,减小了不稳定性。
- Mean-teacher:每一次训练中,对网路的参数使用指数平均法,可以更好的学习新信息并减小不稳定性。
- Dual-Students:一次来两个网络作为学生,卷来卷去,相互学习,有遗传算法的样子。
接下来再介绍五种一致性正则化的方法:
后几种方法都采用了集成模型的思想,所谓“三个臭皮匠,顶个诸葛亮”,在实际的应用中,集成学习的应用的确可以采取很好的效果。
2.6 Fast-SWA
前面的几种方法,其实都是在网络的权重空间上做文章,最后尝试走到一个最好的地方。但是各种方法通过梯度下降到最后,参数的改变往往都会非常小,也就是走到了一个所谓的“平坦”的区域。那我们能不能这么想:任何一种训练方法其实都是在不断的逼近局部最优点,由于之前一致性正则化的要求,就算有很多个网络共同参与训练,那么他们最后也会收敛至一个局部最优。
重点来了,虽然每一个函数都没有到达局部最优,但是他们的参数都是一个局部最优的估计量。根据大数定律,假设网络的个数足够多,并且都已经在之前的一致性正则化算法比较趋近于最优点,那么他们参数的平均值就是最优点的无偏估计量,这就是Stochastic Weight Averaging的算法。
训练到达一定次数后,学习率变为循环学习率,并且训练重复几个周期。每个周期结束后对应于学习率最小值到权重被保存,然后将所有的权重平均,就得到了![]() ,最后将
,最后将![]() 用作预测。
用作预测。
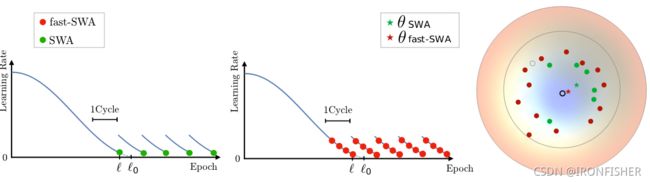
我们先关注SWA算法,绿点是SWA算法,每次都收敛到了一个离最小值点比较远的点,然后求一个平均,诶嘿,就比较接近了!
可能大家还不是特别理解,因为梯度下降算法,不就是沿着一条梯度最小路走的吗?那为什么还会生成那么多个点呢?这里我们就要理解一个概念:余弦退火算法。
退火算法大家应该都知道,在这里我们是怎么实现退火算法的呢?我们可以这样定义:学习率在网络开始训练的时候学习率一般比较大,收敛的比较快。到网络训练的后期,学习率应该逐渐减小,不然就会产生振荡的过程。而在第一次训练逐渐收敛到一个值的时候,原本学习率也很小了,训练接近结束。但是我们可以忽然把学习率设为一个比较高的值(就实现了退火)。这时候再进行训练,网络的损失函数要是处于一个比较sharp的区域,会有很大的可能就跳出了这个局部最小,转而去寻找其他的局部最小,这样就实现了退火功能。
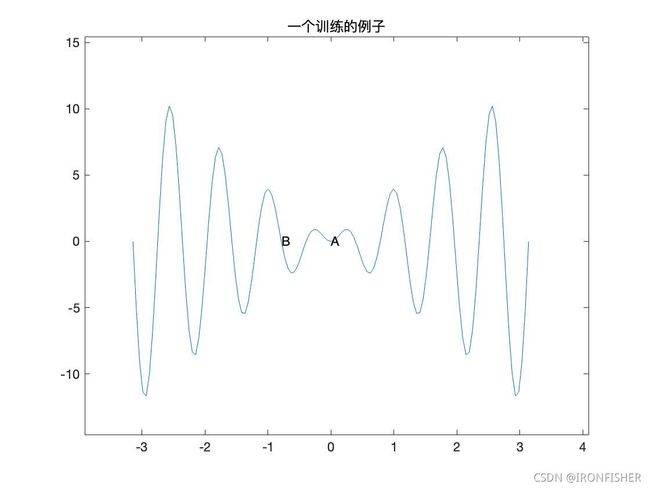
作者一下也没有想到很多典型的函数,所以又找了一个不是很恰当的例子,在画图方面还是希望有大神来指导一下。
假设训练一开始收敛到了极小值A,这时候学习率也很低了,那我们就可以通过退火的算法使学习率很大,然后就直接跳出了这快区域,转到了B这个地方,然后再跳再跳再跳……退火算法本身就是一个很好的优化算法,然后再用上集成模型,就能使得训练收敛的更快更好。
不过SWA模型的缺陷是什么呢?它要求权重之间的欧式距离必须较大,倘若所有的训练都收敛到一个相近的点,那有可能这个点就是最优点,但是有可能算法就搞错了。Fast-SWA算法很好的改进了这个问题,它在同一个周期内平均对应于多个点的网络,从而产生了更好的最终模型和更快的集成过程。(就是退火套退火啦)
不过感觉前的几种算法,都是在模型上做文章,以增强对噪声数据适应性和泛化性。这种就相当于在城堡中不断的建立城墙和打补丁,teacher-student机制也不过是从其他城堡中学习他们造墙的技术而已。接下来,我们将从数据角度对模型进行优化,做一些实战演习。
2.7 Virtual Adversarial Training(虚拟对抗训练,VAT)
显然,由对抗的方法对网络进行优化是一个好决定。我们一个在训练模型之前为每一个数据分配一个标签,这个数据在对抗方向上与其相邻的数据标签相似。具体的说,VAT就是通过在模型最不利的方向上,选择性的平滑模型。
这该怎么理解呢?因为神经网络总的来说是一个参数模型,前面无论怎么打补丁总是有弱点的(可以想像得到,现实世界只是一个三维世界,但是神经网络的维数通常很高,因此在所有维度都建立一个有效的决策边界通常比较难。对抗学习就是基于此发生的,有时在一张图上改变一个像素点,网络的预测就会发生巨大的变化。而VAT就是通过生成一些攻击样本,来找出网络的弱点。
对于每一个输入的样本x,我们想要找出它在对抗方向上的噪声输入r,来最大化的改变模型的预测。首先我们从高斯分布中采样噪声,和样本x相加得到x+r,输入模型之后得到输出![]() ,
,![]() 。求KL-divergence之后再求梯度,对抗输入就根据一个超参数ϵ
。求KL-divergence之后再求梯度,对抗输入就根据一个超参数ϵ 从梯度中进行采样,计算公式如下:
从梯度中进行采样,计算公式如下:

![]()
最后,无监督学习损失计算公式如下:
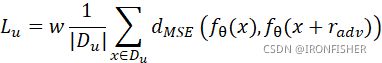
为了训练的更加稳定,这种方法可以和mean-teacher算法集成。
2.8 Adversarial Dropout(对抗性丢弃层)
基于元素的对抗性丢弃层(Element-wise Adversarial Dropout,EAdD)
2.7的方法是通过加入对抗性的噪声来改进模型,接下来的方法通过对抗性的优化改变了模型的预测。这种扰动可以建立一个神经网络的稀疏结构。这样其他形式的加性噪声就不会直接的对网络结构造成改变。
这种算法的第一步是找到一个对网络预测最可能造成改变的随机丢弃层。当然,在SSL情况下数据标签十分的少,因此只能用网络的直接输出作为output,然后据此观察这个output跟决策边界的距离来判断。
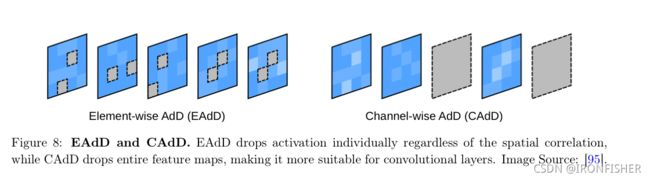
基于通道的对抗性丢弃层(Channel-wise Adversarial Dropout,CAdD)
上面的基于元素的丢弃层只被限制在全连接网络中,而下面的基于通道的丢弃层则可以使用在卷积网络中,因为对于某些卷积网络,中间的通道数过多,可能也会提取模型的重复特征,导致过拟合,以训练网络在更少的特征的情况下能比较好的识别该模型。
2.9 Interpolation Consistency Training(插值一致性训练,ICT)
在之前我们已经知道了,有时候仅仅给网络加一个随机的噪声来训练也不是很有用的,由于对抗学习的兴起,一个关键的噪声干扰就可以达成四两拨千斤的效果。但是前面的VAT和AdD模型要求的计算量都十分大,于是乎又有个方法被开发出来了,该方法也是经过对决策边界的思考,假如两个点相近,那这两个点中间的任何点对应的输出也应该相似。于是利用这条插值公式Mixλa,b=λa+1-![]() ,进入teacher-model产生输出,然后开始的两个input进入student-model,用来计算他们的一致性损失。Teacher-model当然也是student-model经过EMA(指数平均)之后的模型。
,进入teacher-model产生输出,然后开始的两个input进入student-model,用来计算他们的一致性损失。Teacher-model当然也是student-model经过EMA(指数平均)之后的模型。

本质上,这样的训练是希望获得这样的目标:
![]()
这里同时包含了两个目标,一个是插值的输出相近,另一个是希望student和teacher的输出相近,然后再根据此式建立损失函数,当然也是通过这两个值的MSE,再对minibatch的所有data求平均咯。
2.10 Unsupervised Data Augmentation
无监督的数据增强,一部分是从人类的感知域中增加噪声来使得模型具有更好的一致性。方法有:AutoAugment,RandAugment,Back Translation。
这些方法有如下好处:
- 生成了真实的数据向本,可以更加安全、无后果的使得训练更好。
- 可以生成相当多与不同种类的样本,来增加采样的频率。比如对图像作仿射变换,可以生成很多种颜色的图片。
- 可以防止对于不同任务的归纳偏置(inductive biasas)。
归纳偏置是什么意思呢?这跟贝叶斯分布的“先验条件”比较相似。就是说,我们在建立模型开始训练的时候,可能就认为的给模型增加了一些先验的条件,这些条件导致模型的训练有些偏差。按照我们的理解,增加一些先验的条件,常常是好的(比如让模型学球的识别时候,让他先知道是个圆),但是有时候也会造成一些误判。
AutoAugment:创建一个数据增强策略的搜索空间,直接在感兴趣的数据集上评估特定策略的质量,这样在每一次数据增强时就可以自动选取最佳的增强策略进行训练。
RandAugment:就是简单的对图像随机使用仿射变换。
Back-translation:通常用于文本翻译任务,比如要把A先翻译成另外一个语言B,然后再让其翻译回A,来实现增强。
——————————————————————————————————
小结:今天介绍了随机平均算法,是基于退火策略的优化;还有虚拟对抗训练,里面包含了聚类的思想;对抗性丢弃层则是dropout在对抗学习的应用版;插值一致性训练则从函数插值拟合的角度很好的应用了奥卡姆剃刀原理;数据增强则是从最开始的数据增强角度进行优化。上面的几种方法其实都可以做一个整合,比如先对数据进行增强,然后在训练中用插值样本、对抗性丢弃和对抗训练,最后再用上随机平均算法,成为一个究极的集成算法模型。