卷积神经网络(LeNet)的代码实现及模型预测
LeNet的简要介绍
卷积神经网络(LeNet)是1998年提出的,其实质是含有卷积层的一种网络模型。
该网络的构成:该网络主要分为卷积层块和全连接层块两个部分。
卷积层块的基本单位是“卷积层+最大池化层”,其中卷积层主要用来识别图像的空间模式,后接的最大池化层主要用于降低卷积层对于位置的敏感性。全连接层用于完成最后的分类。
本文以教材中最常见的LeNet-5为例进行代码实现及模型预测,该网络模型图如下图所示。
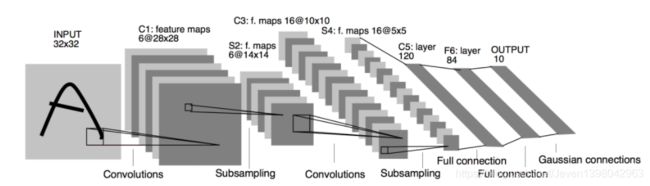
LeNet-5网络结构
LeNet的代码实现及模型预测
模型组成:本文构建的LeNet网络主要包括输入层、两个卷积层、两个池化层和三个全连接层。在卷积层中,每个卷积层都使用5*5的卷积核,并在其输出上使用Sigmoid激活函数。第一个卷积层输出通道为6,后接窗口形状为2*2,步幅为2的最大池化层(不改变输入和输出通道),第二个卷积层输出通道为16,后接与第一层后接的上述池化层一样的池化层。全连接层有3个,其输出个数分别是120,84,10。
该模型的实现代码如下:
导入模块:
import torch
import time
from torch import nn, optim
import sys
import d2lzh_pytorch as d2l
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"构建LeNet网络:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #启用GPU
#构建LeNet网络
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img): #定义前项传播
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
#查看每个层的形状
net = LeNet()
print(net)查看每个层的详细结果如下:
LeNet(
(conv): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=256, out_features=120, bias=True)
(1): Sigmoid()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): Sigmoid()
(4): Linear(in_features=84, out_features=10, bias=True)
)
获取数据和训练类型,同时定义acc求解的函数
#获取数据和训练模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else: # 自定义的模型, 3.13节之后不会用到, 不考虑GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n定义作图函数,便于查看和比对训练结果:
#作图函数
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
d2l.set_figsize(figsize)
d2l.plt.xlabel(x_label)
d2l.plt.ylabel(y_label)
d2l.plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
d2l.plt.semilogy(x2_vals, y2_vals, linestyle=':')
d2l.plt.legend(legend)定义网络模型:
train_acc1 = []
test_acc1 = []
loss_sum = []
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
train_acc1.append((train_acc_sum / n)*100)
test_acc1.append(test_acc*100)
loss_sum.append(train_l_sum / batch_count)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))训练模型,并定义学习率等必要超参数:
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
semilogy(range(1, num_epochs + 1), train_acc1, 'epochs', 'acc/%',range(1, num_epochs + 1), test_acc1, ['train', 'test'])进行5轮训练的训练结果如下:
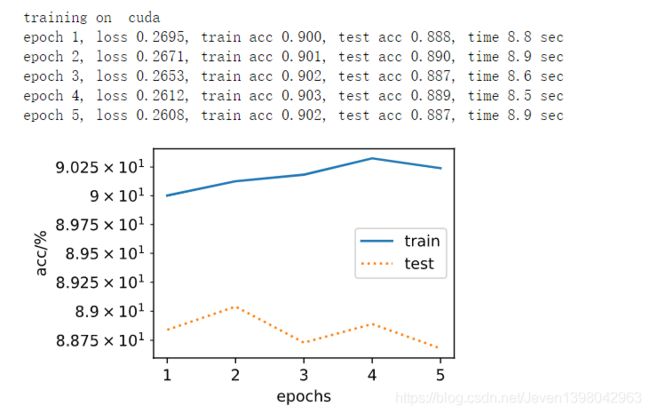
进行预测并将结果展示:
#预测
X, y = iter(test_iter).next()
true_labels = d2l.get_fashion_mnist_labels(y.numpy())
pred_labels = d2l.get_fashion_mnist_labels(net(X.to(device)).argmax(dim=1))
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
d2l.show_fashion_mnist(X[0:9], titles[0:9])运行结果如下(第一行为真实标签、第二行为模型预测结果、第三行为图像输出):

总结及反思
以上就是LeNet-5网络的实现,通过增加训练轮数或许可能会得到更好的准确率,但从网络的组成来看,我们可以发现其许多弊端,如全连接层有3个,容易出现过拟合的问题,同时卷积网络的深度和宽度不够,这样的缺陷也促使人们去发现更好的模型。