深度学习yolo|数据集的准备
yolo2xml.py将yolo格式的txt标签转化为xml标签
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "ball1",
'1': "ball2",
'2': "0degree", # 创建字典用来对类型进行转换
'3': "6degree", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
'4': "12degree",'5': "18degree",'6': "24degree",'7': "30degree",'8': "36degree",'9': "42degree",'10': "48degree",'11': "54degree",'12': "60degree",'13': "66degree",'14': "72degree",'15': "78degree",'16': "84degree",'17': "90degree",'18': "96degree",'19': "102degree",'20': "108degree",'21': "114degree",'22': "120degree",'23': "126degree",'24': "132degree",
'25': "138degree",'26': "144degree",'27': "150degree",'28': "156degree",'29': "162degree",'30': "168degree",'31': "174degree",'32': "180degree",
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath +'\\'+ name)
txtList = txtFile.readlines()
for root,dirs,filename in os.walk(picPath):
img = cv2.imread(root+ '\\'+filename[i])
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath +'\\'+ name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = r"G:\make_1.2M_6D_VOCdevkit\VOC2007\JPEGImages" # 图片所在文件夹路径,后面的/一定要带上
txtPath = r"G:\make_1.2M_6D_VOCdevkit\VOC2007\YOLOTXT" # yolo txt所在文件夹路径,后面的/一定要带上
xmlPath = r"G:\make_1.2M_6D_VOCdevkit\VOC2007\Annotations" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
bath_txt.py批量生成txt标签。
#批量生成txt标签
#一个文件夹里有一个txt文档和608张JPG图像,复制608个txt,将txt文档里的内容分别写入608个txt,txt文档name为对应的JPG的name
import glob
import os
import shutil
Path=r"G:\1.2M_6D_data"
for root,dirs,filename in os.walk(Path):
for i in range(len(filename)):
if filename[i].endswith('.mat'):
os.remove(root+"\\"+filename[i])
with open(root+"\\"+filename[1],'r') as f:
content=f.read()
print(content)
if filename[i].endswith('jpg'):
name = filename[i].split('.')[0]
print(name)
new_txt=root+"\\"+name+'.txt' #创建txt文件
with open(new_txt,'w') as ff:
ff.write(content)
class2list.py用于将classes.txt里的类别名称打印成列表格式。
result = []
with open(r'C:\Users\YUXIAOYANG\Desktop\1.2M_6D_data\classes.txt' ,'r') as f:
for line in f:
result.append(line.strip().split(',')[0]) #a.append(b):是将b原封不动的追加到a的末尾上,会改变a的值
#strip()用于移除字符串头尾指定的字符(默认为空格或者换行符)或字符序列
print(result)
print(result[0])
———————————————————————————————————————————
数据集格式如下图所示。
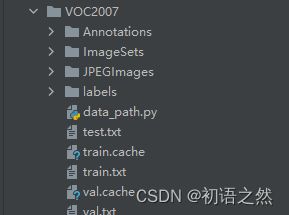
Annotations:xml标签
ImageSets:四个文本文档
JPEGImages:图片
label:yolo格式的txt标签
makeTxt.py如下。用来生成ImageSets的文本文档。
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'VOC2007/Annotations'
txtsavepath = 'VOC2007/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('VOC2007/ImageSets/trainval.txt', 'w')
ftest = open('VOC2007/ImageSets/test.txt', 'w')
ftrain = open('VOC2007/ImageSets/train.txt', 'w')
fval = open('VOC2007/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
voc_label.py如下。用来生成voc2007同级目录下的三个文本文档。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['ball1', 'ball2', '0degree', '6degree', '12degree', '18degree', '24degree', '30degree', '36degree', '42degree', '48degree', '54degree', '60degree', '66degree', '72degree', '78degree', '84degree', '90degree', '96degree', '102degree', '108degree', '114degree', '120degree', '126degree', '132degree', '138degree', '144degree', '150degree', '156degree', '162degree', '168degree', '174degree', '180degree'] #改成自己的类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOC2007/Annotations/%s.xml' % (image_id))
out_file = open('VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('VOC2007/labels/'):
os.makedirs('VOC2007/labels/')
image_ids = open('VOC2007/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('VOC2007/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()