GroupViT
文章目录
- GroupViT: Semantic Segmentation Emerges from Text Supervision
- 一、Multi-stage Grouping
-
- 1.代码
- 2.实验
- 二、Grouping Block
-
- 1.代码
- 2.实验
GroupViT: Semantic Segmentation Emerges from Text Supervision

一、Multi-stage Grouping

1.代码
GroupViT:
def forward_features(self, x, *, return_attn=False):
B = x.shape[0]
x, hw_shape = self.patch_embed(x) # Conv2d LayerNorm
x = x + self.get_pos_embed(B, *hw_shape) # Parameter trunc_normal_ 采样
x = self.pos_drop(x) # Dropout
group_token = None
attn_dict_list = []
# =====================================
for layer in self.layers: # GroupingLayer
x, group_token, attn_dict = layer(x, group_token, return_attn=return_attn) # GroupingLayer
attn_dict_list.append(attn_dict)
# =====================================
x = self.norm(x) # LayerNorm
return x, group_token, attn_dict_list
GroupingLayer:
def forward(self, x, prev_group_token=None, return_attn=False):
"""
Args:
x (torch.Tensor): image tokens, [B, L, C]
prev_group_token (torch.Tensor): group tokens, [B, S_1, C]
return_attn (bool): whether to return attention maps
"""
if self.with_group_token:
group_token = self.group_token.expand(x.size(0), -1, -1)
if self.group_projector is not None:
group_token = group_token + self.group_projector(prev_group_token)
else:
group_token = None
B, L, C = x.shape
cat_x = self.concat_x(x, group_token)
# =====================================
# Transformer Layers
# =====================================
for blk_idx, blk in enumerate(self.blocks):
if self.use_checkpoint:
cat_x = checkpoint.checkpoint(blk, cat_x)
else:
cat_x = blk(cat_x)
# =====================================
# Transformer Layers
# =====================================
x, group_token = self.split_x(cat_x)
attn_dict = None
# =====================================
# Grouping Block
# =====================================
if self.downsample is not None:
x, attn_dict = self.downsample(x, group_token, return_attn=return_attn)
# =====================================
# Grouping Block
# =====================================
return x, group_token, attn_dict
Transformer Layer:
def forward(self, x, mask=None):
x = x + self.drop_path(self.attn(self.norm1(x), mask=mask))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
Attention:
def forward(self, query, key=None, *, value=None, mask=None):
if self.qkv_fuse:
assert key is None
assert value is None
x = query
B, N, C = x.shape
S = N
# [3, B, nh, N, C//nh]
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [B, nh, N, C//nh]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
else:
B, N, C = query.shape
if key is None:
key = query
if value is None:
value = key
S = key.size(1)
# [B, nh, N, C//nh]
q = rearrange(self.q_proj(query), 'b n (h c)-> b h n c', h=self.num_heads, b=B, n=N, c=C // self.num_heads) # Linear rearrange
# [B, nh, S, C//nh]
k = rearrange(self.k_proj(key), 'b n (h c)-> b h n c', h=self.num_heads, b=B, c=C // self.num_heads) # Linear rearrange
# [B, nh, S, C//nh]
v = rearrange(self.v_proj(value), 'b n (h c)-> b h n c', h=self.num_heads, b=B, c=C // self.num_heads) # Linear rearrange
# [B, nh, N, S]
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
attn = attn + mask.unsqueeze(dim=1)
attn = attn.softmax(dim=-1)
else:
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn) # Dropout
assert attn.shape == (B, self.num_heads, N, S)
# [B, nh, N, C//nh] -> [B, N, C]
# out = (attn @ v).transpose(1, 2).reshape(B, N, C)
out = rearrange(attn @ v, 'b h n c -> b n (h c)', h=self.num_heads, b=B, n=N, c=C // self.num_heads) # rearrange
out = self.proj(out) # Linear
out = self.proj_drop(out) # Dropout
return out
2.实验
Multi Stage Grouping

2层stages比1层stage精度要高
二、Grouping Block
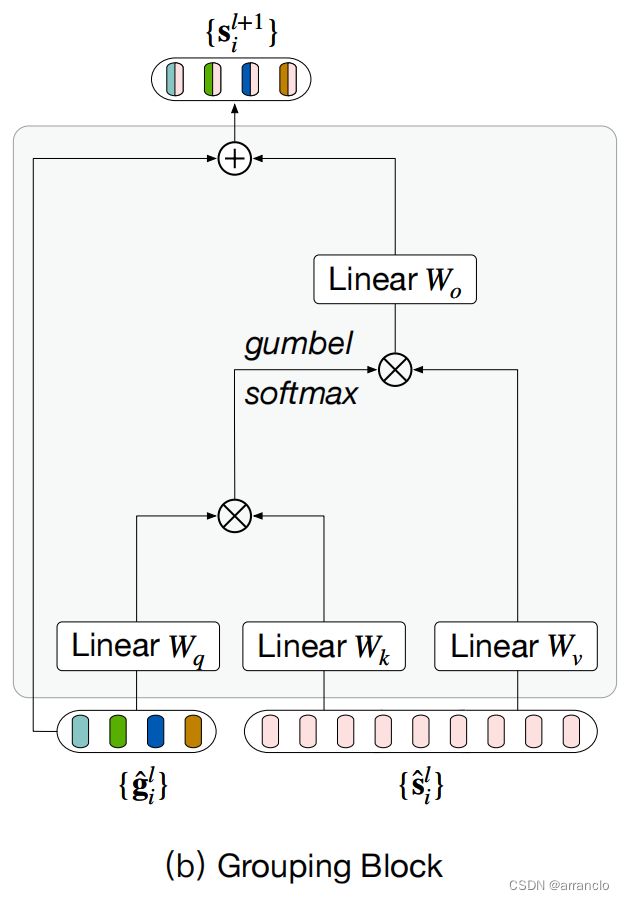
1.代码
GroupingLayer:
def forward(self, x, prev_group_token=None, return_attn=False):
"""
Args:
x (torch.Tensor): image tokens, [B, L, C]
prev_group_token (torch.Tensor): group tokens, [B, S_1, C]
return_attn (bool): whether to return attention maps
"""
# =====================================
# Group Token
# =====================================
if self.with_group_token:
group_token = self.group_token.expand(x.size(0), -1, -1) # torch.zeros
if self.group_projector is not None:
group_token = group_token + self.group_projector(prev_group_token) # nn.Linear(prev_dim, dim, bias=False)
else:
group_token = None
# =====================================
# Group Token
# =====================================
B, L, C = x.shape
cat_x = self.concat_x(x, group_token)
# =====================================
# Transformer Layers
# =====================================
for blk_idx, blk in enumerate(self.blocks):
if self.use_checkpoint:
cat_x = checkpoint.checkpoint(blk, cat_x)
else:
cat_x = blk(cat_x)
# =====================================
# Transformer Layers
# =====================================
x, group_token = self.split_x(cat_x)
attn_dict = None
# =====================================
# Grouping Block
# =====================================
if self.downsample is not None:
x, attn_dict = self.downsample(x, group_token, return_attn=return_attn)
# =====================================
# Grouping Block
# =====================================
return x, group_token, attn_dict
Grouping Block:
def forward(self, x, group_tokens, return_attn=False):
"""
Args:
x (torch.Tensor): image tokens, [B, L, C]
group_tokens (torch.Tensor): group tokens, [B, S_1, C]
return_attn (bool): whether to return attention map
Returns:
new_x (torch.Tensor): [B, S_2, C], S_2 is the new number of
group tokens
"""
group_tokens = self.norm_tokens(group_tokens) # layernorm
x = self.norm_x(x) # layernorm
# [B, S_2, C]
projected_group_tokens = self.project_group_token(group_tokens) # mlp layernorm
projected_group_tokens = self.pre_assign_attn(projected_group_tokens, x) # CrossAttnBlock projected_group_tokens做q x做k、v
new_x, attn_dict = self.assign(projected_group_tokens, x, return_attn=return_attn) # AssignAttention projected_group_tokens做q x做k、v
new_x += projected_group_tokens
new_x = self.reduction(new_x) + self.mlp_channels(self.norm_new_x(new_x)) # layernorm Linear # Mlp
return new_x, attn_dict
MLP:
def forward(self, x):
x = self.fc1(x) # Linear
x = self.act(x) # GELU
x = self.drop(x) # Dropout
x = self.fc2(x) # Linear
x = self.drop(x) # Dropout
return x
CrossAttnBlock:
def forward(self, query, key, *, mask=None):
x = query
x = x + self.drop_path(self.attn(self.norm_q(query), self.norm_k(key), mask=mask)) # DropPath Attention LayerNorm
x = x + self.drop_path(self.mlp(self.norm2(x))) # DropPath mlp LayerNorm
x = self.norm_post(x) # LayerNorm
return x
AssignAttention:
def forward(self, query, key=None, *, value=None, return_attn=False):
B, N, C = query.shape
if key is None:
key = query
if value is None:
value = key
S = key.size(1)
# [B, nh, N, C//nh]
q = rearrange(self.q_proj(query), 'b n (h c)-> b h n c', h=self.num_heads, b=B, n=N, c=C // self.num_heads) # Linear rearrange
# [B, nh, S, C//nh]
k = rearrange(self.k_proj(key), 'b n (h c)-> b h n c', h=self.num_heads, b=B, c=C // self.num_heads) # Linear rearrange
# [B, nh, S, C//nh]
v = rearrange(self.v_proj(value), 'b n (h c)-> b h n c', h=self.num_heads, b=B, c=C // self.num_heads) # Linear rearrange
# [B, nh, N, S]
raw_attn = (q @ k.transpose(-2, -1)) * self.scale
# Assign=====================================
attn = self.get_attn(raw_attn) # softmax
if return_attn:
hard_attn = attn.clone()
soft_attn = self.get_attn(raw_attn, gumbel=False, hard=False)
attn_dict = {'hard': hard_attn, 'soft': soft_attn}
else:
attn_dict = None
if not self.sum_assign:
attn = attn / (attn.sum(dim=-1, keepdim=True) + self.assign_eps)
# Assign=====================================
attn = self.attn_drop(attn) # Dropout
assert attn.shape == (B, self.num_heads, N, S)
# [B, nh, N, C//nh] <- [B, nh, N, S] @ [B, nh, S, C//nh]
out = rearrange(attn @ v, 'b h n c -> b n (h c)', h=self.num_heads, b=B, n=N, c=C // self.num_heads) # rearrange
out = self.proj(out) # Linear
out = self.proj_drop(out) # Linear
return out, attn_dict
2.实验
Multi Stage Grouping
