使用NeRF进行3D体素渲染
使用NeRF进行3D体素渲染的最小代码实现
文章目录
- 使用NeRF进行3D体素渲染的最小代码实现
- 前言
- 一、设置
- 二、下载并载入数据
- 三、数据处理流程
- 四、NeRF模型
- 五、训练
- 六、训练步骤可视化
- 七、推理
- 八、渲染3D场景
- 九、视频可视化
- 总结
- 完整的代码地址
- 前进的道路
- 参考
前言
在这个例子中,我们展示了文献NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis的最小实现。作者提出了一种巧妙的方法,通过神经网络对体积场景函数进行建模,从而合成场景的新视图。
为了帮助您直观地理解这一点,让我们从以下问题开始:是否可以将图像中像素的位置提供给神经网络,并要求网络预测该位置的颜色?
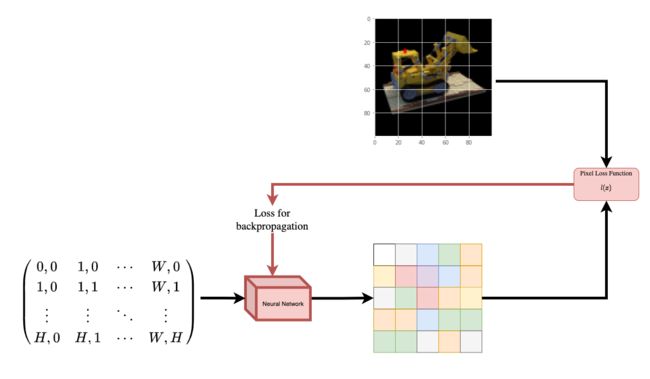
图 1:给定图像坐标作为神经网络作的输入并要求预测坐标处的颜色
神经网络会假设记忆(过拟合)图像。这意味着我们的神经网络会将整个图像编码为其权重。我们可以用每个位置查询神经网络,它最终会重建整个图像。

图 2:经过训练的神经网络从头开始重新创建图像。
现在出现了一个问题,我们如何扩展这个想法来学习 3D 体素场景?实现与上述类似的过程需要了解每个体素(体积像素)。事实证明,这是一项非常具有挑战性的任务。
该论文的作者提出了一种使用场景的一些图像来学习 3D 场景的最小而优雅的方法。他们放弃使用体素进行训练。使用网络学习对体积场景进行建模,从而生成模型在训练时未显示的 3D 场景的新视图(图像)。
为了充分理解这一过程,需要了解一些先决条件。我们以这样一种方式构建示例,以便您在开始实施之前拥有所有必需的知识。
一、设置
# Setting random seed to obtain reproducible results.
import tensorflow as tf
tf.random.set_seed(42)
import os
import glob
import imageio
import numpy as np
from tqdm import tqdm
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
# Initialize global variables.
AUTO = tf.data.AUTOTUNE
BATCH_SIZE = 5
NUM_SAMPLES = 32
POS_ENCODE_DIMS = 16
EPOCHS = 20
二、下载并载入数据
npz 数据文件包含图像、相机姿势和焦距。这些图像是从多个摄像机角度拍摄的,如图 3 所示:
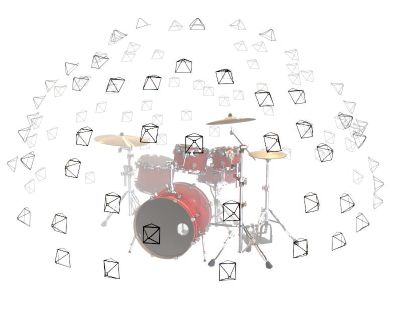
图 3:多个摄像机角度
要理解这种情况下的相机姿势,我们必须首先让自己认为相机是现实世界和二维图像之间的映射。
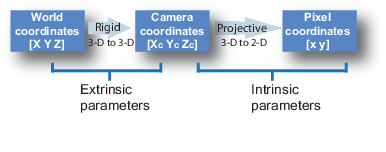
图 4:通过相机将 3-D 世界映射到 2-D 图像
考虑以下等式:
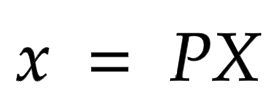
其中 x 是 2-D 图像点,X 是 3-D 世界点,P 是相机矩阵。 P 是一个 3 x 4 矩阵,在将现实世界对象映射到图像平面上起着至关重要的作用。
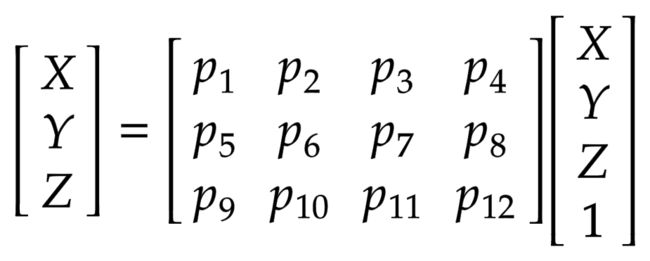
相机矩阵是一个仿射变换矩阵,它与 3 x 1 列 [图像高度、图像宽度、焦距] 连接以生成姿势矩阵。该矩阵的尺寸为 3 x 5,其中第一个 3 x 3 块位于相机的视点中。轴是 [down, right, backwards] 或 [-y, x, z],其中相机面向前方 -z。
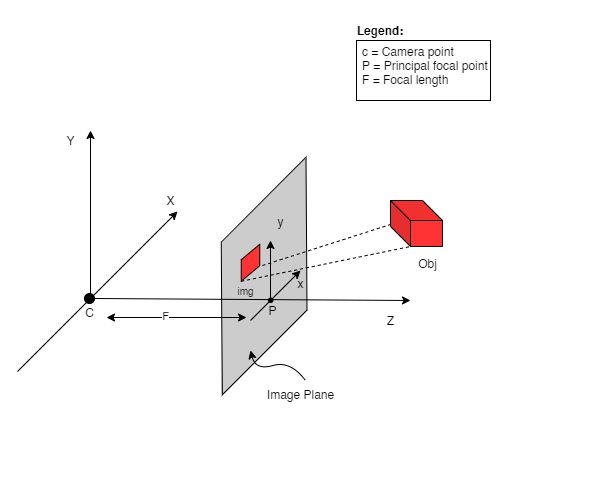
图 5:仿射变换。
COLMAP 帧是 [right, down, forwards] 或 [x, -y, -z]。在此处阅读有关 COLMAP 的更多信息。
# Download the data if it does not already exist.
file_name = "tiny_nerf_data.npz"
url = "https://people.eecs.berkeley.edu/~bmild/nerf/tiny_nerf_data.npz"
if not os.path.exists(file_name):
data = keras.utils.get_file(fname=file_name, origin=url)
data = np.load(data)
images = data["images"]
im_shape = images.shape
(num_images, H, W, _) = images.shape
(poses, focal) = (data["poses"], data["focal"])
# Plot a random image from the dataset for visualization.
plt.imshow(images[np.random.randint(low=0, high=num_images)])
plt.show()
Downloading data from https://people.eecs.berkeley.edu/~bmild/nerf/tiny_nerf_data.npz
12730368/12727482 [==============================] - 0s 0us/step
三、数据处理流程
现在您已经了解了相机矩阵的概念以及从 3D 场景到 2D 图像的映射,让我们来谈谈逆映射,即从 2D 图像到 3D 场景。
我们需要讨论使用光线投射和追踪的体素渲染,这是常见的计算机图形技术。本节将帮助您快速掌握这些技术。
考虑具有 N 个像素的图像。我们通过每个像素射出一条射线,并在射线上采样一些点。射线通常由方程 r(t) = o + td 参数化,其中 t 是参数,o 是原点,d 是单位方向矢量,如图 6 所示。
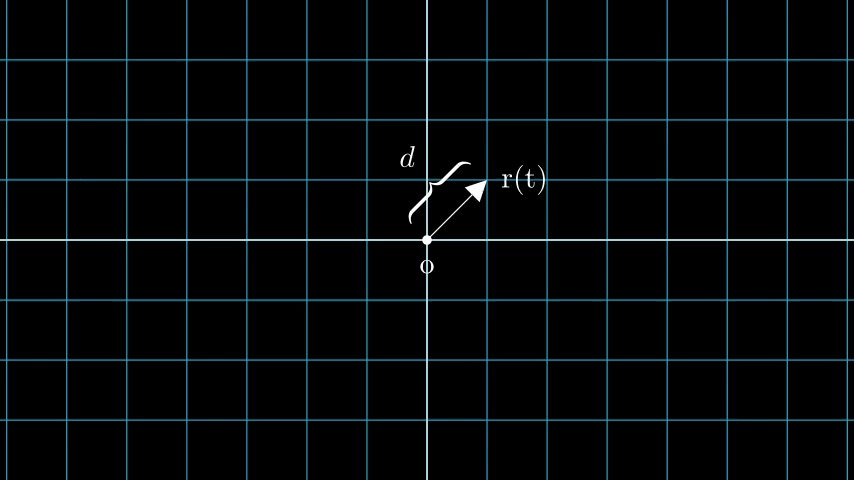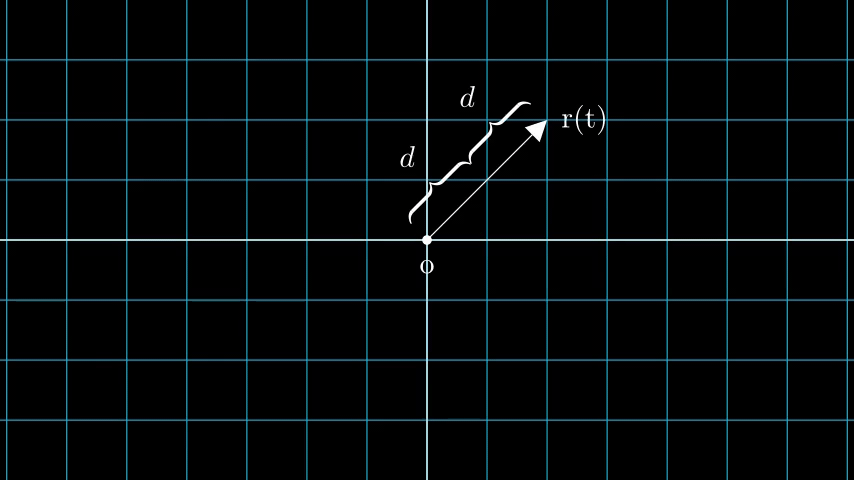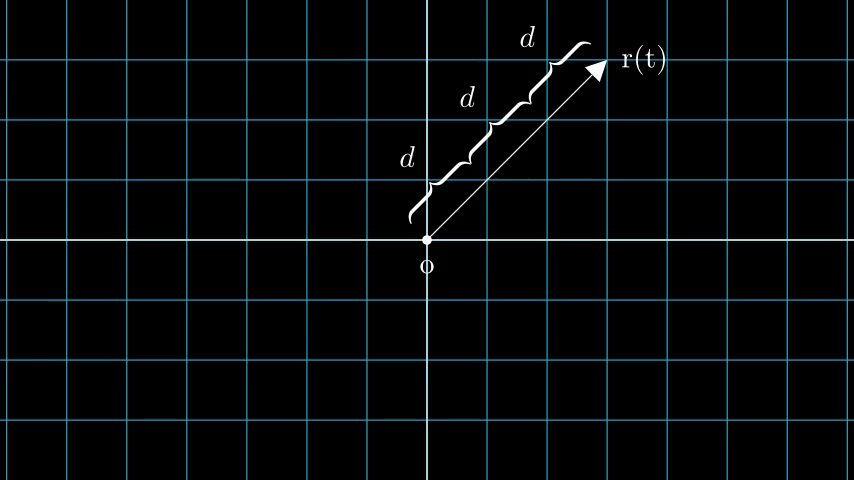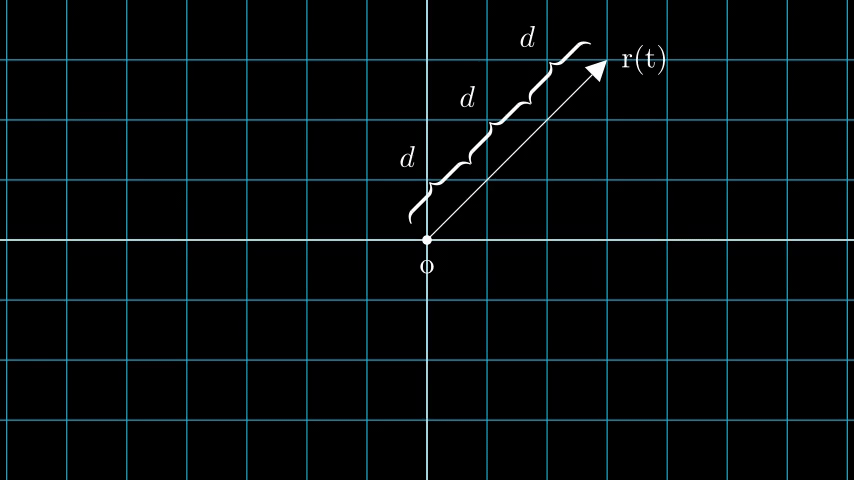
图 6:r(t) = o + td 其中 t 为 3
在图 7 中,我们考虑一条射线,并在射线上采样一些随机点。这些样本点每个都有一个唯一的位置(x、y、z),并且射线有一个视角(theta、phi),关于该视角,可以参考下面的示意图。
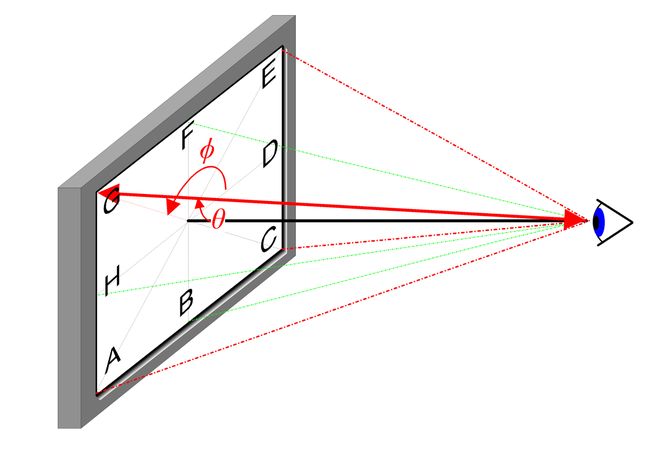
视线角度示意图
视角特别有趣,因为我们可以通过许多不同的方式通过单个像素拍摄光线,每种方式都有独特的视角。这里要注意的另一件有趣的事情是添加到采样过程中的噪声。我们为每个样本添加均匀的噪声,使样本对应于连续分布。在图 7 中,蓝点是均匀分布的样本,白点(t1、t2、t3)随机放置在样本之间。

图 7:从射线中采样点。
图 8 以 3D 形式展示了整个采样过程,您可以在其中看到从白色图像发出的光线。这意味着每个像素都有其对应的光线,并且每条光线都将在不同的点进行采样。
图 8:从 3-D 图像的所有像素发射光线
这些采样点作为 NeRF 模型的输入。然后要求模型预测该点的 RGB 颜色和体积密度。

图 9:数据管道
def encode_position(x):
"""Encodes the position into its corresponding Fourier feature.
Args:
x: The input coordinate.
Returns:
Fourier features tensors of the position.
"""
positions = [x]
for i in range(POS_ENCODE_DIMS):
for fn in [tf.sin, tf.cos]:
positions.append(fn(2.0 ** i * x))
return tf.concat(positions, axis=-1)
def get_rays(height, width, focal, pose):
"""Computes origin point and direction vector of rays.
Args:
height: Height of the image.
width: Width of the image.
focal: The focal length between the images and the camera.
pose: The pose matrix of the camera.
Returns:
Tuple of origin point and direction vector for rays.
"""
# Build a meshgrid for the rays.
i, j = tf.meshgrid(
tf.range(width, dtype=tf.float32),
tf.range(height, dtype=tf.float32),
indexing="xy",
)
# Normalize the x axis coordinates.
transformed_i = (i - width * 0.5) / focal
# Normalize the y axis coordinates.
transformed_j = (j - height * 0.5) / focal
# Create the direction unit vectors.
directions = tf.stack([transformed_i, -transformed_j, -tf.ones_like(i)], axis=-1)
# Get the camera matrix.
camera_matrix = pose[:3, :3]
height_width_focal = pose[:3, -1]
# Get origins and directions for the rays.
transformed_dirs = directions[..., None, :]
camera_dirs = transformed_dirs * camera_matrix
ray_directions = tf.reduce_sum(camera_dirs, axis=-1)
ray_origins = tf.broadcast_to(height_width_focal, tf.shape(ray_directions))
# Return the origins and directions.
return (ray_origins, ray_directions)
def render_flat_rays(ray_origins, ray_directions, near, far, num_samples, rand=False):
"""Renders the rays and flattens it.
Args:
ray_origins: The origin points for rays.
ray_directions: The direction unit vectors for the rays.
near: The near bound of the volumetric scene.
far: The far bound of the volumetric scene.
num_samples: Number of sample points in a ray.
rand: Choice for randomising the sampling strategy.
Returns:
Tuple of flattened rays and sample points on each rays.
"""
# Compute 3D query points.
# Equation: r(t) = o+td -> Building the "t" here.
t_vals = tf.linspace(near, far, num_samples)
if rand:
# Inject uniform noise into sample space to make the sampling
# continuous.
shape = list(ray_origins.shape[:-1]) + [num_samples]
noise = tf.random.uniform(shape=shape) * (far - near) / num_samples
t_vals = t_vals + noise
# Equation: r(t) = o + td -> Building the "r" here.
rays = ray_origins[..., None, :] + (
ray_directions[..., None, :] * t_vals[..., None]
)
rays_flat = tf.reshape(rays, [-1, 3])
rays_flat = encode_position(rays_flat)
return (rays_flat, t_vals)
def map_fn(pose):
"""Maps individual pose to flattened rays and sample points.
Args:
pose: The pose matrix of the camera.
Returns:
Tuple of flattened rays and sample points corresponding to the
camera pose.
"""
(ray_origins, ray_directions) = get_rays(height=H, width=W, focal=focal, pose=pose)
(rays_flat, t_vals) = render_flat_rays(
ray_origins=ray_origins,
ray_directions=ray_directions,
near=2.0,
far=6.0,
num_samples=NUM_SAMPLES,
rand=True,
)
return (rays_flat, t_vals)
# Create the training split.
split_index = int(num_images * 0.8)
# Split the images into training and validation.
train_images = images[:split_index]
val_images = images[split_index:]
# Split the poses into training and validation.
train_poses = poses[:split_index]
val_poses = poses[split_index:]
# Make the training pipeline.
train_img_ds = tf.data.Dataset.from_tensor_slices(train_images)
train_pose_ds = tf.data.Dataset.from_tensor_slices(train_poses)
train_ray_ds = train_pose_ds.map(map_fn, num_parallel_calls=AUTO)
training_ds = tf.data.Dataset.zip((train_img_ds, train_ray_ds))
train_ds = (
training_ds.shuffle(BATCH_SIZE)
.batch(BATCH_SIZE, drop_remainder=True, num_parallel_calls=AUTO)
.prefetch(AUTO)
)
# Make the validation pipeline.
val_img_ds = tf.data.Dataset.from_tensor_slices(val_images)
val_pose_ds = tf.data.Dataset.from_tensor_slices(val_poses)
val_ray_ds = val_pose_ds.map(map_fn, num_parallel_calls=AUTO)
validation_ds = tf.data.Dataset.zip((val_img_ds, val_ray_ds))
val_ds = (
validation_ds.shuffle(BATCH_SIZE)
.batch(BATCH_SIZE, drop_remainder=True, num_parallel_calls=AUTO)
.prefetch(AUTO)
)
四、NeRF模型
该模型是一个多层感知器 (MLP),以 ReLU 作为其非线性激活函数。
论文摘录:
“我们通过限制网络将体积密度 sigma 预测为仅位置 x 的函数,来使得这个表征是多视图一致的,同时允许将 RGB 颜色 c 预测为位置和视角的函数。为了实现这些功能,MLP 首先使用 8 个全连接层(使用 ReLU 激活和每层 256 个通道)处理输入 3D 坐标 x,并输出 sigma 和 256 维特征向量。然后将该特征向量与相机光线视线连接,并输入到一个额外的全连接层(使用 ReLU 激活和 128 个通道),输出与视图相关(view-dependent)的 RGB 颜色。”
在这里,我们进行了最小化实现,并使用了 64 个 Dense 单元,而不是本文中提到的 256 个。
def get_nerf_model(num_layers, num_pos):
"""Generates the NeRF neural network.
Args:
num_layers: The number of MLP layers.
num_pos: The number of dimensions of positional encoding.
Returns:
The [`tf.keras`](https://www.tensorflow.org/api_docs/python/tf/keras) model.
"""
inputs = keras.Input(shape=(num_pos, 2 * 3 * POS_ENCODE_DIMS + 3))
x = inputs
for i in range(num_layers):
x = layers.Dense(units=64, activation="relu")(x)
if i % 4 == 0 and i > 0:
# Inject residual connection.
x = layers.concatenate([x, inputs], axis=-1)
outputs = layers.Dense(units=4)(x)
return keras.Model(inputs=inputs, outputs=outputs)
def render_rgb_depth(model, rays_flat, t_vals, rand=True, train=True):
"""Generates the RGB image and depth map from model prediction.
Args:
model: The MLP model that is trained to predict the rgb and
volume density of the volumetric scene.
rays_flat: The flattened rays that serve as the input to
the NeRF model.
t_vals: The sample points for the rays.
rand: Choice to randomise the sampling strategy.
train: Whether the model is in the training or testing phase.
Returns:
Tuple of rgb image and depth map.
"""
# Get the predictions from the nerf model and reshape it.
if train:
predictions = model(rays_flat)
else:
predictions = model.predict(rays_flat)
predictions = tf.reshape(predictions, shape=(BATCH_SIZE, H, W, NUM_SAMPLES, 4))
# Slice the predictions into rgb and sigma.
rgb = tf.sigmoid(predictions[..., :-1])
sigma_a = tf.nn.relu(predictions[..., -1])
# Get the distance of adjacent intervals.
delta = t_vals[..., 1:] - t_vals[..., :-1]
# delta shape = (num_samples)
if rand:
delta = tf.concat(
[delta, tf.broadcast_to([1e10], shape=(BATCH_SIZE, H, W, 1))], axis=-1
)
alpha = 1.0 - tf.exp(-sigma_a * delta)
else:
delta = tf.concat(
[delta, tf.broadcast_to([1e10], shape=(BATCH_SIZE, 1))], axis=-1
)
alpha = 1.0 - tf.exp(-sigma_a * delta[:, None, None, :])
# Get transmittance.
exp_term = 1.0 - alpha
epsilon = 1e-10
transmittance = tf.math.cumprod(exp_term + epsilon, axis=-1, exclusive=True)
weights = alpha * transmittance
rgb = tf.reduce_sum(weights[..., None] * rgb, axis=-2)
if rand:
depth_map = tf.reduce_sum(weights * t_vals, axis=-1)
else:
depth_map = tf.reduce_sum(weights * t_vals[:, None, None], axis=-1)
return (rgb, depth_map)
五、训练
训练步骤作为自定义 keras.Model 子类的一部分实现,以便我们可以使用 model.fit 功能。
class NeRF(keras.Model):
def __init__(self, nerf_model):
super().__init__()
self.nerf_model = nerf_model
def compile(self, optimizer, loss_fn):
super().compile()
self.optimizer = optimizer
self.loss_fn = loss_fn
self.loss_tracker = keras.metrics.Mean(name="loss")
self.psnr_metric = keras.metrics.Mean(name="psnr")
def train_step(self, inputs):
# Get the images and the rays.
(images, rays) = inputs
(rays_flat, t_vals) = rays
with tf.GradientTape() as tape:
# Get the predictions from the model.
rgb, _ = render_rgb_depth(
model=self.nerf_model, rays_flat=rays_flat, t_vals=t_vals, rand=True
)
loss = self.loss_fn(images, rgb)
# Get the trainable variables.
trainable_variables = self.nerf_model.trainable_variables
# Get the gradeints of the trainiable variables with respect to the loss.
gradients = tape.gradient(loss, trainable_variables)
# Apply the grads and optimize the model.
self.optimizer.apply_gradients(zip(gradients, trainable_variables))
# Get the PSNR of the reconstructed images and the source images.
psnr = tf.image.psnr(images, rgb, max_val=1.0)
# Compute our own metrics
self.loss_tracker.update_state(loss)
self.psnr_metric.update_state(psnr)
return {"loss": self.loss_tracker.result(), "psnr": self.psnr_metric.result()}
def test_step(self, inputs):
# Get the images and the rays.
(images, rays) = inputs
(rays_flat, t_vals) = rays
# Get the predictions from the model.
rgb, _ = render_rgb_depth(
model=self.nerf_model, rays_flat=rays_flat, t_vals=t_vals, rand=True
)
loss = self.loss_fn(images, rgb)
# Get the PSNR of the reconstructed images and the source images.
psnr = tf.image.psnr(images, rgb, max_val=1.0)
# Compute our own metrics
self.loss_tracker.update_state(loss)
self.psnr_metric.update_state(psnr)
return {"loss": self.loss_tracker.result(), "psnr": self.psnr_metric.result()}
@property
def metrics(self):
return [self.loss_tracker, self.psnr_metric]
test_imgs, test_rays = next(iter(train_ds))
test_rays_flat, test_t_vals = test_rays
loss_list = []
class TrainMonitor(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
loss = logs["loss"]
loss_list.append(loss)
test_recons_images, depth_maps = render_rgb_depth(
model=self.model.nerf_model,
rays_flat=test_rays_flat,
t_vals=test_t_vals,
rand=True,
train=False,
)
# Plot the rgb, depth and the loss plot.
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(20, 5))
ax[0].imshow(keras.preprocessing.image.array_to_img(test_recons_images[0]))
ax[0].set_title(f"Predicted Image: {epoch:03d}")
ax[1].imshow(keras.preprocessing.image.array_to_img(depth_maps[0, ..., None]))
ax[1].set_title(f"Depth Map: {epoch:03d}")
ax[2].plot(loss_list)
ax[2].set_xticks(np.arange(0, EPOCHS + 1, 5.0))
ax[2].set_title(f"Loss Plot: {epoch:03d}")
fig.savefig(f"images/{epoch:03d}.png")
plt.show()
plt.close()
num_pos = H * W * NUM_SAMPLES
nerf_model = get_nerf_model(num_layers=8, num_pos=num_pos)
model = NeRF(nerf_model)
model.compile(
optimizer=keras.optimizers.Adam(), loss_fn=keras.losses.MeanSquaredError()
)
# Create a directory to save the images during training.
if not os.path.exists("images"):
os.makedirs("images")
model.fit(
train_ds,
validation_data=val_ds,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
callbacks=[TrainMonitor()],
steps_per_epoch=split_index // BATCH_SIZE,
)
def create_gif(path_to_images, name_gif):
filenames = glob.glob(path_to_images)
filenames = sorted(filenames)
images = []
for filename in tqdm(filenames):
images.append(imageio.imread(filename))
kargs = {"duration": 0.25}
imageio.mimsave(name_gif, images, "GIF", **kargs)
create_gif("images/*.png", "training.gif")
Epoch 1/20
16/16 [==============================] - 15s 753ms/step - loss: 0.1134 - psnr: 9.7278 - val_loss: 0.0683 - val_psnr: 12.0722

Epoch 2/20
16/16 [==============================] - 13s 752ms/step - loss: 0.0648 - psnr: 12.4200 - val_loss: 0.0664 - val_psnr: 12.1765

Epoch 3/20
16/16 [==============================] - 13s 746ms/step - loss: 0.0607 - psnr: 12.5281 - val_loss: 0.0673 - val_psnr: 12.0121

Epoch 4/20
16/16 [] - 13s 758ms/step - loss: 0.0595 - psnr: 12.7050 - val_loss: 0.0646 - val_psnr: 12.2768
Epoch 5/20
16/16 [] - 13s 755ms/step - loss: 0.0583 - psnr: 12.7522 - val_loss: 0.0613 - val_psnr: 12.5351
Epoch 6/20
16/16 [==============================] - 13s 749ms/step - loss: 0.0545 - psnr: 13.0654 - val_loss: 0.0553 - val_psnr: 12.9512



Epoch 7/20
16/16 [==============================] - 13s 744ms/step - loss: 0.0480 - psnr: 13.6313 - val_loss: 0.0444 - val_psnr: 13.7838
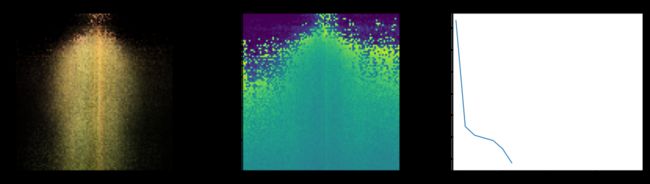
Epoch 8/20
16/16 [==============================] - 13s 763ms/step - loss: 0.0359 - psnr: 14.8570 - val_loss: 0.0342 - val_psnr: 14.8823

Epoch 9/20
16/16 [==============================] - 13s 758ms/step - loss: 0.0299 - psnr: 15.5374 - val_loss: 0.0287 - val_psnr: 15.6171

Epoch 10/20
16/16 [==============================] - 13s 779ms/step - loss: 0.0273 - psnr: 15.9051 - val_loss: 0.0266 - val_psnr: 15.9319

Epoch 11/20
16/16 [==============================] - 13s 736ms/step - loss: 0.0255 - psnr: 16.1422 - val_loss: 0.0250 - val_psnr: 16.1568
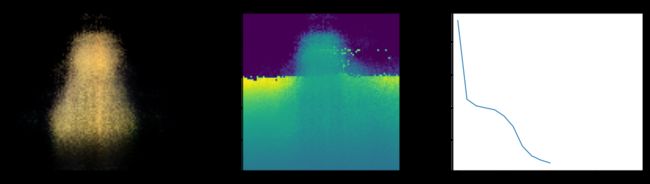
Epoch 12/20
16/16 [==============================] - 13s 746ms/step - loss: 0.0236 - psnr: 16.5074 - val_loss: 0.0233 - val_psnr: 16.4793

Epoch 13/20
16/16 [==============================] - 13s 755ms/step - loss: 0.0217 - psnr: 16.8391 - val_loss: 0.0210 - val_psnr: 16.8950

Epoch 14/20
16/16 [==============================] - 13s 741ms/step - loss: 0.0197 - psnr: 17.2245 - val_loss: 0.0187 - val_psnr: 17.3766

Epoch 15/20
16/16 [==============================] - 13s 739ms/step - loss: 0.0179 - psnr: 17.6246 - val_loss: 0.0179 - val_psnr: 17.5445

Epoch 16/20
16/16 [==============================] - 13s 735ms/step - loss: 0.0175 - psnr: 17.6998 - val_loss: 0.0180 - val_psnr: 17.5154
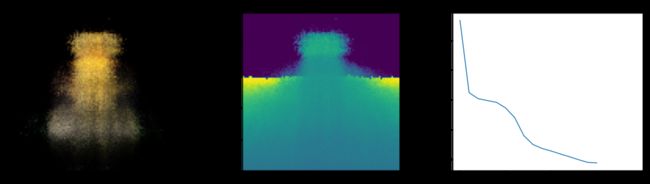
Epoch 17/20
16/16 [==============================] - 13s 741ms/step - loss: 0.0167 - psnr: 17.9393 - val_loss: 0.0156 - val_psnr: 18.1784
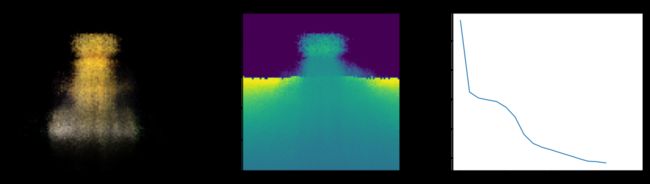
Epoch 18/20
16/16 [==============================] - 13s 750ms/step - loss: 0.0150 - psnr: 18.3875 - val_loss: 0.0151 - val_psnr: 18.2811

Epoch 19/20
16/16 [==============================] - 13s 755ms/step - loss: 0.0141 - psnr: 18.6476 - val_loss: 0.0139 - val_psnr: 18.6216
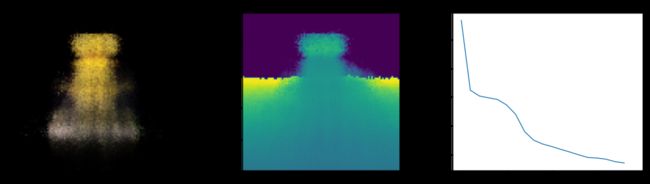
Epoch 20/20
16/16 [==============================] - 14s 777ms/step - loss: 0.0139 - psnr: 18.7131 - val_loss: 0.0137 - val_psnr: 18.7259

100%|██████████| 20/20 [00:00<00:00, 57.59it/s]
六、训练步骤可视化
在这里,我们看到了训练步骤。 随着损失的减少,渲染图像和深度图越来越好。 在您的本地系统中,您将看到生成的 training.gif 文件。
七、推理
在本节中,我们要求模型构建场景的新颖视图。 在训练步骤中,该模型获得了 106 个场景视图。 训练图像的集合不能包含场景的每个角度。 经过训练的模型可以用一组稀疏的训练图像来表示整个 3-D 场景。
在这里,我们为模型提供不同的姿势,并要求它为我们提供与该相机视图对应的二维图像。 如果我们推断所有 360 度视图的模型,它应该提供从四面八方的整个场景的概览。
# Get the trained NeRF model and infer.
nerf_model = model.nerf_model
test_recons_images, depth_maps = render_rgb_depth(
model=nerf_model,
rays_flat=test_rays_flat,
t_vals=test_t_vals,
rand=True,
train=False,
)
# Create subplots.
fig, axes = plt.subplots(nrows=5, ncols=3, figsize=(10, 20))
for ax, ori_img, recons_img, depth_map in zip(
axes, test_imgs, test_recons_images, depth_maps
):
ax[0].imshow(keras.preprocessing.image.array_to_img(ori_img))
ax[0].set_title("Original")
ax[1].imshow(keras.preprocessing.image.array_to_img(recons_img))
ax[1].set_title("Reconstructed")
ax[2].imshow(
keras.preprocessing.image.array_to_img(depth_map[..., None]), cmap="inferno"
)
ax[2].set_title("Depth Map")

八、渲染3D场景
在这里,我们将合成新颖的 3D 视图并将它们拼接在一起以渲染包含 360 度视图的视频。
def get_translation_t(t):
"""Get the translation matrix for movement in t."""
matrix = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, t],
[0, 0, 0, 1],
]
return tf.convert_to_tensor(matrix, dtype=tf.float32)
def get_rotation_phi(phi):
"""Get the rotation matrix for movement in phi."""
matrix = [
[1, 0, 0, 0],
[0, tf.cos(phi), -tf.sin(phi), 0],
[0, tf.sin(phi), tf.cos(phi), 0],
[0, 0, 0, 1],
]
return tf.convert_to_tensor(matrix, dtype=tf.float32)
def get_rotation_theta(theta):
"""Get the rotation matrix for movement in theta."""
matrix = [
[tf.cos(theta), 0, -tf.sin(theta), 0],
[0, 1, 0, 0],
[tf.sin(theta), 0, tf.cos(theta), 0],
[0, 0, 0, 1],
]
return tf.convert_to_tensor(matrix, dtype=tf.float32)
def pose_spherical(theta, phi, t):
"""
Get the camera to world matrix for the corresponding theta, phi
and t.
"""
c2w = get_translation_t(t)
c2w = get_rotation_phi(phi / 180.0 * np.pi) @ c2w
c2w = get_rotation_theta(theta / 180.0 * np.pi) @ c2w
c2w = np.array([[-1, 0, 0, 0], [0, 0, 1, 0], [0, 1, 0, 0], [0, 0, 0, 1]]) @ c2w
return c2w
rgb_frames = []
batch_flat = []
batch_t = []
# Iterate over different theta value and generate scenes.
for index, theta in tqdm(enumerate(np.linspace(0.0, 360.0, 120, endpoint=False))):
# Get the camera to world matrix.
c2w = pose_spherical(theta, -30.0, 4.0)
#
ray_oris, ray_dirs = get_rays(H, W, focal, c2w)
rays_flat, t_vals = render_flat_rays(
ray_oris, ray_dirs, near=2.0, far=6.0, num_samples=NUM_SAMPLES, rand=False
)
if index % BATCH_SIZE == 0 and index > 0:
batched_flat = tf.stack(batch_flat, axis=0)
batch_flat = [rays_flat]
batched_t = tf.stack(batch_t, axis=0)
batch_t = [t_vals]
rgb, _ = render_rgb_depth(
nerf_model, batched_flat, batched_t, rand=False, train=False
)
temp_rgb = [np.clip(255 * img, 0.0, 255.0).astype(np.uint8) for img in rgb]
rgb_frames = rgb_frames + temp_rgb
else:
batch_flat.append(rays_flat)
batch_t.append(t_vals)
rgb_video = "rgb_video.mp4"
imageio.mimwrite(rgb_video, rgb_frames, fps=30, quality=7, macro_block_size=None)
120it [00:12, 9.24it/s]
九、视频可视化
在这里,我们可以看到渲染的场景 360 度视图。 该模型仅在 20 个 epoch 内就通过稀疏图像集成功地学习了整个体积空间。 您可以查看本地保存的渲染视频,名为 rgb_video.mp4。
总结
我们制作了 NeRF 的最小实现,以直观地了解其核心思想和方法。 这种方法已被用于计算机图形空间的各种其他工作中。
| Epochs | GIF of the training step |
|---|---|
| 100 | |
| 200 | |
完整的代码地址
- Github
- Colab
前进的道路
如果有人有兴趣深入了解 NeRF,我们在 PyImageSearch 上构建了一个由 3 部分组成的博客系列。
- Prerequisites of NeRF
- Concepts of NeRF
- Implementing NeRF
参考
- NeRF repository:NeRF 的官方地址。
- NeRF paper:关于 NeRF 的论文。
- Manim Repository:我们使用 manim 来构建所有动画。
- Mathworks:相机校准文章相关。
- Mathew’s video:关于 NeRF 的精彩视频。
以上模型可以在Hugging Face Spaces中进行尝试。
最后:
以上翻译自:
https://keras.io/examples/vision/nerf/