week1(2021.9.17-2021.9.24)
Step1 安装软件 python,pycharm,Ananconda3,jupyter notebook等
这步骤非常的繁琐 其中Ananconda3,jupyter notebook我是跟着以下视频进行学习的,不具体展开讲,很麻烦PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
Step2 作为一名0基础小白,我跟着导师给的以下链接进行学习(本周看到了P16并且跳过了P17)
Pytorch 入门到精通全教程 卷积神经网络 循环神经网络_哔哩哔哩_bilibili
总结笔记(拿来老师的总结,清晰度不知道为什么):

里面的语法挺重要的,不过太多的东西也记不住,还需要后期看代码慢慢查找
Step3 练习代码(线性回归和API线性回归)
1.线性回归
import torch
import matplotlib.pyplot as plt
learning_rate = 0.01
# 1、 准备数据
# y=3x+0.8
x = torch.rand([500, 1])
y_true = x*3+0.8
# 2、 通过模型计算
w = torch.rand([1, 1], requires_grad=True)
b = torch.tensor(0, requires_grad=True, dtype=torch.float32)
# 3、 计算loss
# 4、 通过循环,反向传播,更新参数
for i in range(500):
y_predict = torch.matmul(x, w) + b
loss = (y_true - y_predict).pow(2).mean()
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
loss.backward() # 反向传播
w.data = w.data-learning_rate*w.grad
b.data = b.data-learning_rate*b.grad
print("w,b,loss", w.item(), b.item(), loss.item())
plt.figure(figsize=(20, 8))
plt.scatter(x.numpy().reshape(-1), y_true.numpy().reshape(-1))
y_predict = torch.matmul(x, w) + b
plt.plot(x.numpy().reshape(-1), y_predict.detach().numpy().reshape(-1), c="r")
plt.show()
程序没问题,但运行时遇到了以下问题(和我电脑文件重复有关)
![]()
因此我查找解决方法,发现了插入以下代码就可以(治标不治本)
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
成功地运行了
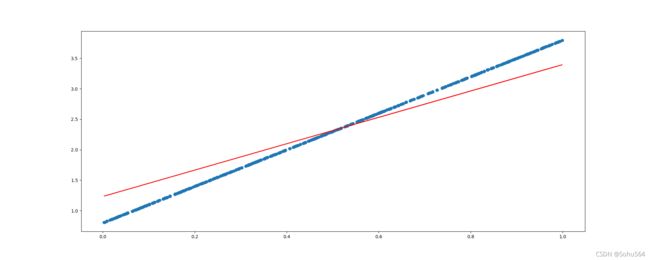
其中,蓝色的线是由500个随机数散点组成的y=3x+0.8,因此每次运行时,散点取值都不尽相同
红色的线是通过训练得到的y=3x+0.8,可以看出二者的区别很大,这是由于循环次数不够造成的
![]() w为斜率,经过500次才达到2.1597.....
w为斜率,经过500次才达到2.1597.....
b为截距,经过500次才达到1.2390.....
可以提高循环次数来解决这个问题,例如将 for i in range(500):中的500改为5000
![]()

效果不错!
2.调用API实现线性回归
因为实际过程的代码参数肯定不止上边的w,b两个,因此就需要找一种更为合适统一的方法:
给出代码:
import torch
import torch.nn as nn
from torch.optim import SGD
# 准备数据
x = torch.rand([500, 1])
y_true = 3 * x + 0.8
# 1、定义模型
class MyLinear(nn.Module):
def __init__(self):
super(MyLinear, self).__init__() # 继承父类init的参数
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
# 2、实例化模型
my_linear = MyLinear()
optimizer = SGD(my_linear.parameters(), 0.001) # 梯度下降
loss_fn = nn.MSELoss()
# 3、循环,进行梯度下降,参数的更新
for i in range(5000):
y_predict = my_linear(x)
loss = loss_fn(y_predict, y_true)
# 梯度置为零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
if i % 100 == 0:
print(loss.item(), list(my_linear.parameters())[0].item(), list(my_linear.parameters())[1].item())
很奇怪的一点,代码检查了一个下午+晚上,不知道哪里总出现问题

于是就多练习看代码的逻辑(反正代码不是错的,有参考价值)
Step4 9.24号开小组组会
一.陈述这周都做了什么:
1.安装软件(超级费劲)
2.学习pytorch知识点(后期写代码还要自己手动查意思,因为记不住)
3.两个程序(导师说是简单中的最简单的了)
二.组会收获
1.点击Code,然后点击Reformat Code 可以消除很多的warning(我写代码的时候总忘记空格等格式,总会出现warning,这个就很方便)

2.A.每周的代码储存在同一个文件夹,标号week1,week2
B.做好学习笔记和代码的每周归类(我就放在CSDN啦)
3.同一个文件夹 新建py文件,然后就可以运行当前文件夹,别再傻乎乎的覆盖了
Step5 下周安排
1.继续看开头的B站视频,如果哪里跟不上看导师给的其他参考书,重复看知识点
2.记得安装MobaXterm,以后拿学校的服务器跑代码
3.week2文件夹的代码