基于python使用TPE搜索算法调整机器学习超参数
在日常机器学习调参过程中,我们常常使用网格搜索、随机搜索和基于GP的SMBO(Sequential Model-Based Optimization)搜索。然而还有一些其他方法也很好用,比如笔者今天所介绍的基于TPE的SMBO(Sequential Model-Based Optimization)搜索。
TPE搜索简要介绍:
TPE(Tree-structured Parzen Estimators)搜索最核心的思想: 根据贝叶斯公式:P(Y|X) =[ P(X|Y) X P(Y) ] / P(X),基于GP的SMBO的思想是估计P(Y|X), 而基于TPE的SMBO的思想是估计P(X|Y)。
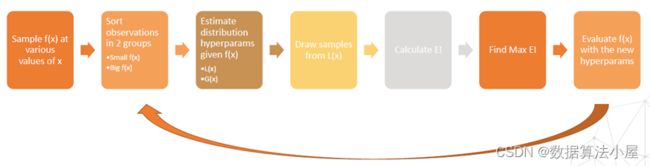
TPE搜索的流程如下,如下图所示:
- 对f(x)抽样
- 分成small f(x) 和 big f(x)
- 估计 small f(x) 的分布 L(x),估计 big f(x)的分布 G(x)
- 对L(x) 进行抽样
- 计算EI,找到最大的EI
- 根据EI更新f(x)
- 重复 2 ~ 7
TPE搜索调参实例:
下面介绍如何使用python基于TPE搜索对sklearn 中的神经网络模型进行调参的实例
- pip install hyperopt
- 导入相关模块
import numpy as np import pandas as pd from sklearn.datasets import load_breast_cancer from sklearn.metrics import accuracy_score, roc_auc_score from sklearn.model_selection import cross_val_score, train_test_split from sklearn.neural_network import MLPClassifier # hp: define the hyperparameter space # fmin: optimization function from hyperopt import hp, fmin # the search algorithms from hyperopt import tpe - 划分数据集
breast_cancer_X, breast_cancer_y = load_breast_cancer(return_X_y=True)
X = pd.DataFrame(breast_cancer_X)
y = pd.Series(breast_cancer_y).map({0:1, 1:0})
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
4. 定义搜索空间、目标函数(注意由于fmin是最小化,所以我们优化的目标值score取负值。)
# determine the hyperparameter space
param_grid = {
'hidden_layer_sizes': hp.choice('hidden_layer_sizes', [(10), (10, 20), (10, 20, 30)]),
'activation': hp.choice('activation', ["tanh", "relu"]),
'solver': hp.choice('solver', ["adam", "sgd"]),
'learning_rate_init': hp.loguniform('learning_rate_init', np.log(0.001), np.log(1)),
}
# the objective function takes the hyperparameter space as input
def objective(params):
params_dict = {
'hidden_layer_sizes': params['hidden_layer_sizes'],
'activation': params['activation'],
'solver': params['solver'],
'learning_rate_init': params['learning_rate_init'],
'random_state': 1000,
'max_iter': 100,
}
mlp = MLPClassifier(**params_dict)
score = cross_val_score(mlp, X_train, y_train, scoring='accuracy', cv=3, n_jobs=4).mean()
# to minimize, we negate the score
return -score
5. 运行并展示结果
# fmin performs the minimization
search = fmin(
fn=objective,
space=param_grid,
max_evals=50,
rstate=np.random.RandomState(42),
algo=tpe.suggest, # tpe search
)
print(search)
结果:
100%|███████████████████| 50/50 [00:31<00:00, 1.57trial/s, best loss: -0.9220779220779222]
{'activation': 1,
'hidden_layer_sizes': 1,
'learning_rate_init': 0.00818802957397879,
'solver': 0}
好了,本次的分享就到先到这。关注我,带你走进数据算法的世界。
-
微信公众号 数据算法小屋
-
CSDN https://blog.csdn.net/TommyLi_YanLi
-
知乎 https://www.zhihu.com/people/74-25-40-76-26
-
作者邮箱:[email protected]