LSTM与CNN学习
部分来源于http://blog.csdn.net/stdcoutzyx/article/details/41596663
LSTM网络
LSTM网络和传统MLP是不同的。像MLP,网络由神经元层组成。输入数据通过网络传播以进行预测。与RNN一样,LSTM具有递归连接,使得来自先前时间步的神经元的先前激活状态被用作形成输出的上下文。
和其他的RNN不一样,LSTM具有一个独特的公式,使其避免防止出现阻止和缩放其他RNN的问题。这,以及令人影响深刻的结果是可以实现的,这也是这项技术得以普及的原因。
RNNs一直以来所面临的一个关键问题是怎么样有效地训练它们。实验表明,权重更新过程导致权重变化,权重很快变成了如此之小,小到没有效果(梯度消失)或者权重变得如此之大,导致非常大的变化或者溢出(梯度爆炸),这一问题是非常的困难的。LSTM通过设计而克服了这一困难。
LSTM网络的计算单元被称为存储单元(memory cell),存储器块(memory block)或者简称单元(cell)。当描述MLPs时,术语“神经元”作为计算单元是根深蒂固的,因此它经常被用来指LSTM存储单元。LSTM单元由权重和门组成。
具体结构如图所示:
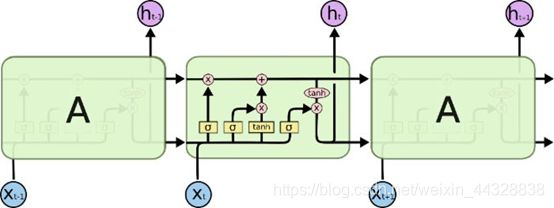
Input Gate决定当前时刻LSTM单元的Input vector对memory cell中信息的改变量,Forget Gate决定上一时刻历史信息对当前时刻memory cell中的信息的影响程度,Output Gate对memory cell中信息的输出量进行控制。

LSTM权重
一个记忆单元具有输入、输出的权重参数,以及通过暴露于输入时间步长而建立的内部状态。
- 输入权重。用于对当前时间步长的输入进行加权。
- 输出权重。用于对上次步骤的输出进行加权。
- 内部状态。在这个时间步长的输出计算中使用内部状态。
LSTM门
记忆单元的关键是门。这些也是加权函数,它们进一步控制单元中的信息。有三个门:
- 遗忘门。决定什么样的信息需要从单元中丢弃。
- 输入门。决定输入中哪些值来更新记忆状态。
- 输出门。根据输入和单元的内存决定输出什么。
在内部状态的更新中使用了遗忘门和输入门。输入门是单元实际输出什么的最后限制。正是这些门和一致的数据流被称为CEC(constant error carrousel),它保持每个单元稳定(既不爆炸或者消失)。
不像传统的MLP神经元,很难画出一个干净的LSTM存储单元。到处都有线、权重和门。我们可以将LSTM的3个关键术语归纳为:
- 克服了训练RNN的技术问题,即梯度消失和梯度爆炸问题。
- 拥有记忆来克服与输入序列相关的长期时间依赖问题。
- 一个个时间步长地处理输入序列和输出序列,允许可变长度的输入和输出。
LSTM的限制
LSTM给人留下了深刻的印象。网络的设计克服了RNN的技术挑战,用神经网络实现了对序列预测的保证。LSTM的应用在一系列的复杂问题上取得了令人印象深刻的结果。但是LSTM对于所有的序列预测问题可能不是理想的。
例如,在时间序列预测中,通常用于预测信息在过去观察的一个小窗口内。通常,具有窗口或线性模型的MLP可能是一个不太复杂和更合适的模型。
LSTM的一个重要的局限是记忆。或者更准确地说,记忆是如何被滥用的。有可能迫使LSTM模型在很长的输入时间步长上记住单个观察。这是LSTM的不良使用,并且需要LSTM模型记住多个观察将失败。当将LSTM应用于时间序列预测时,可以看出,该问题表述为回归,要求删除是输入序列中的多个遥远时间步长的函数。一个LSTM可能被迫在这个问题上执行,但是通常比一个精心设计的自回归模型或重新考虑问题一般少一些。
神经网络
神经网络的每个单元如下: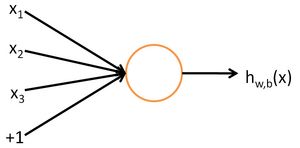
其对应的公式如下:
![]()
其中,该单元也可以被称作是Logistic回归模型。当将多个单元组合起来并具有分层结构时,就形成了神经网络模型。下图展示了一个具有一个隐含层的神经网络。
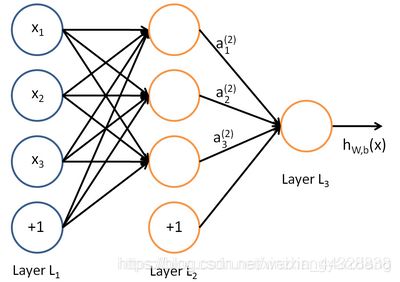
其对应的公式如下:
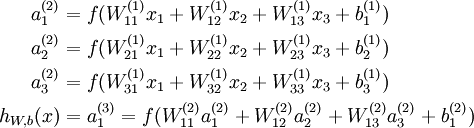
比较类似的,可以拓展到有2,3,4,5,…个隐含层。
CNN(卷积神经网络)
CNN的结构类似Yoon Kim在《Convolutional neural networks for sentence classification》中提出的结构。

其中,卷积窗口的大小设置对最终的分类结果影响较大,借鉴N-gram语言模型的思想,通过提取相邻n个词进行局部特征的提取,从而捕捉上下文搭配词语的语义信息,对整个文本的语义进行表示。根据这种思想,将卷积窗口大小设置为n*m,n为窗口内词的个数,m为词向量维度。
同时使用多个卷积核生成feature maps,再进行max pooling操作,最后使用sotfmax进行分类。
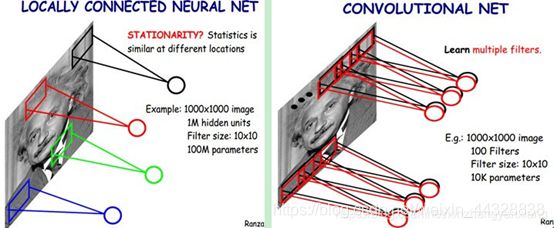
局部感知
卷积神经网络有两种神器可以降低参数数目,第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为局部连接。

在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的万分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
参数共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
如下图所示,展示了一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
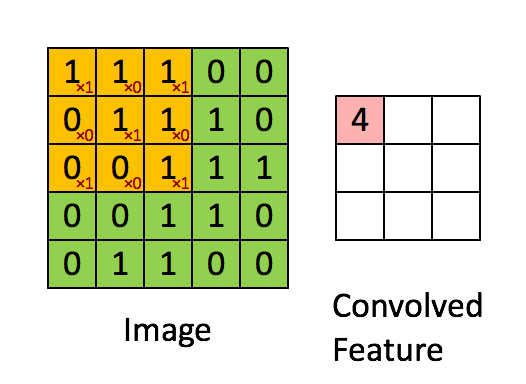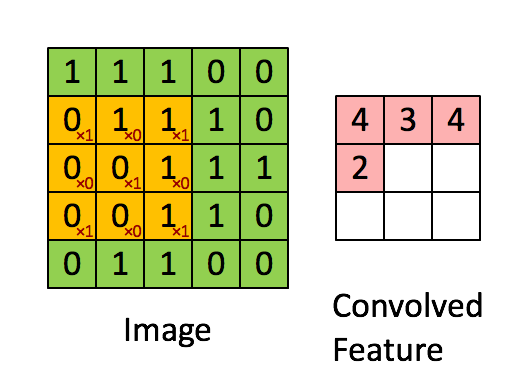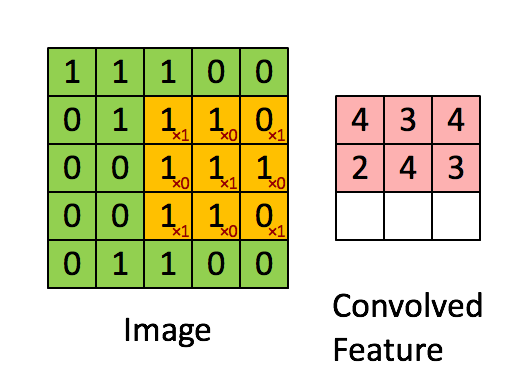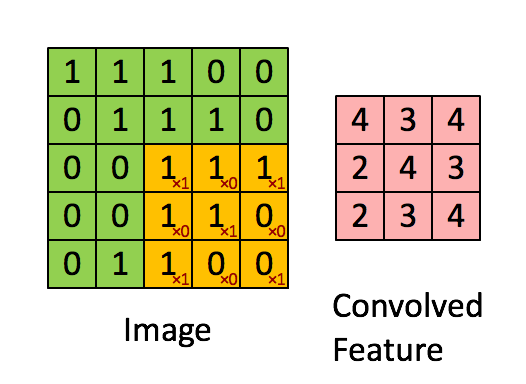
多卷积核
上面所述只有100个参数时,表明只有1个10*10的卷积核,显然,特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示:
上图右,不同颜色表明不同的卷积核。每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。如下图所示,下图有个小错误,即将w1改为w0,w2改为w1即可。下文中仍以w1和w2称呼它们。
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道。其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。
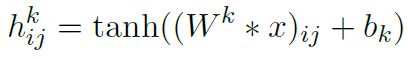
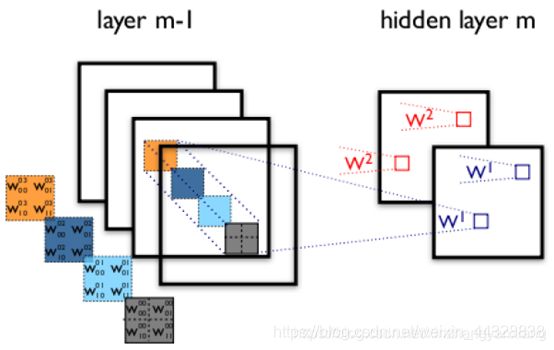
所以,在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。
Down-pooling
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。
例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
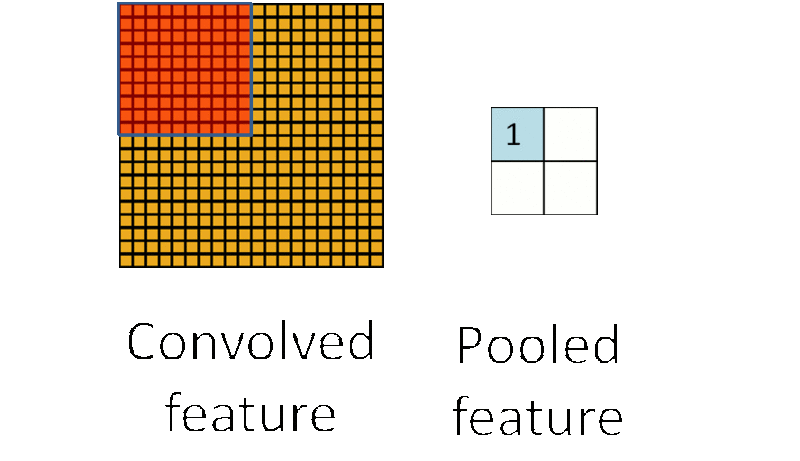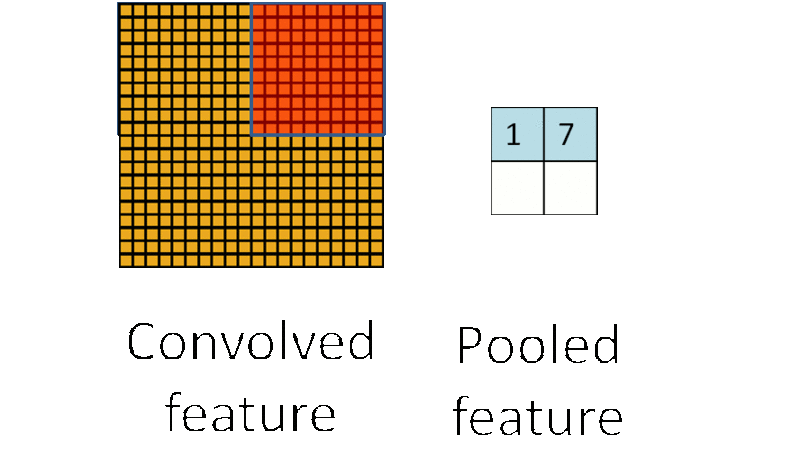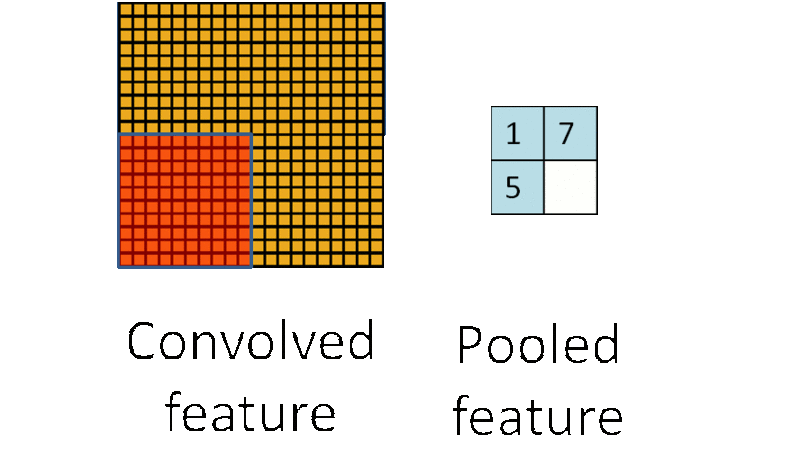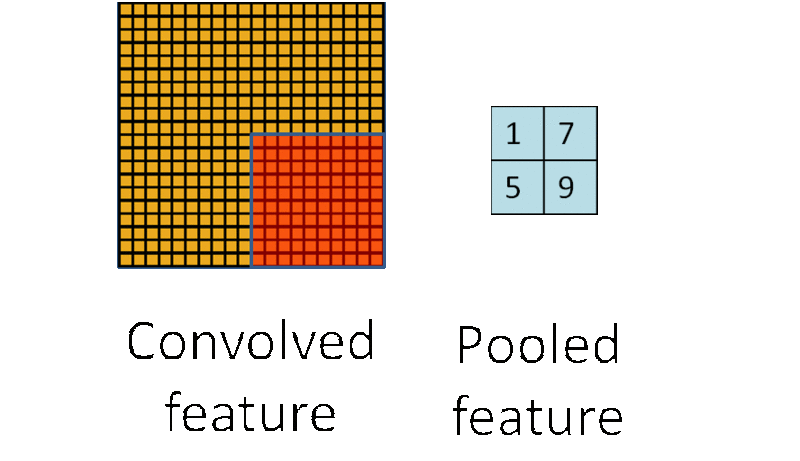
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,
例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
多层卷积
在实际应用中,往往使用多层卷积,然后再使用全连接层进行训练,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。
CNN LSTM
结构
CNN LSTM结构涉及在输入数据中使用卷积神经网络(CNN)层做特征提取并结合LSTM来支持序列预测。CNN LSTM开发用来可视化序列预测问题和从图像序列生成文本描述的应用(例如:视频)。特别地,问题包括:
• 活动识别。对一个序列的图片所显示的活动生成一个文本的描述。
• 图像描述。对单个图片生成一个文本的描述。
• 视频描述。对一个序列的图片生成一个文本的描述。
CNN LSTMs是这样一类模型,它在空间和时间上都很深,并具有适用于各种输入任务和输出的视觉任务的灵活性。
这种架构最初被称为长期卷积神经网络(Long-term Recurrent Convolutional Network)或者LRCN模型。尽管我们将使用更通用的名为CNNLSTM来指代本课中使用的CNN作为前段的LSTM模型。该体系结构用于生成图像的文本描述的任务。关键是使用CNN,它在具有挑战性的图像分类问题上被预训练,该任务被重新用作字幕生成问题的特征提取器。
使用CNN作为图像的编码器是很自然的,通过对图像分类任何进行预训练,并将最后隐藏层作为输入生成RNN解码器。
这种体系结构也被用于语音识别和自然语言处理问题,其中CNN被用作语音和文本输入数据上的LSTM的特征提取器。该体系结构合适于以下的问题:
• 它们的输入中具有空间结构,例如如下中的2D结构或像素或句子、段落或者文档中的一维结构;
• 在其输入中具有时间结构,或者视频中的图像顺序或者文本中的单词或者需要生产具有时间结构的输出,例如文本描述中的单词。
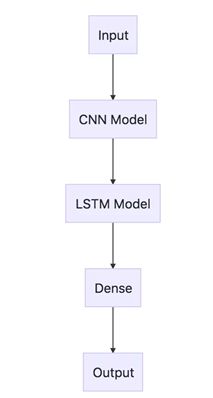
实现
CNN LSTM可以通过在前端添加CNN层然后紧接着LSTM作为全连接层输出来被定义。
这种体系结构可以被看做是两个子模型:CNN模型做特征提取,LSTM模型帮助教师跨时间步长的特征。在假设输入是图像的一系列的2D输入情况下,这两个子模型的背景:
①CNN模型
作为刷新,我们可定义一个2D卷积网络,包括Conv2D和MaxPooling2D层,它们有序的排列在所需深度的堆栈中。Conv2D将解释图像的快照(例如:小方块),池化层将巩固或抽象解释。
例如,下面的片段期望以1个通道(例如:黑和白)读取10X10像素图像。Conv2D将读取2X2快照中的图像并输出一个新的10X10的图像解释。MaxPooling2D将池化解释为2X2的块,将输出减少到5X5合并。Flatten层将采用单个5X5映射,并将其转换成25个元素的矢量,以准备用于其他层处理,例如用于预测输出的Dense。
cnn = Sequential()
cnn.add(Conv2D(1, (2,2), activation= 'relu' , padding= 'same' , input_shape=(10,10,1)))
cnn.add(MaxPooling2D(pool_size=(2, 2)))
cnn.add(Flatten())
②LSTM模型
上面的CNN网络只能处理单个图像,将其输入像素转换为内部矩阵或者矢量表示。我们需要在多个图像删重复该操作,并允许LSTM通过输入图像的内部矢量表示的序列使用BPTT来建立内部状态和更新权重。
CNN可以使用现有的预训练模型如VGG进行图像特征提取。CNN可能不被训练,我们可能希望通过LSTM的错误从多个输入图像反向传播到CNN模型来训练它。在这种情况下,概念上都有一个单一的CNN模型和一个LSTM序列,每个时间步长都有一个模型。我们希望将CNN模型应用于每个输入图像,并将每个输入图像的输出作为单个时间步长传递给LSTM。
我们可以通过将整个CNN输入模型(一层或多层)封装在一个TimeDistributed层中来实现这一点。该层实现了多次应用相同层或层的期望结果。在这种情况下,将其多次应用于多个输入时间步长,并依次向LSTM模型提供一系列图像解释或者图像特征。
model.add(TimeDistributed(...)) model.add(LSTM(...)) model.add(Dense(...))
③CNN LSTM模型
我们可以定义一个CNN LSTM模型的层,将它们包含在TimeDistributed层中,然后定义LSTM以及输出层。我们有两个方法来定义模型,这两种定义的方法是等效的,只是在品位上有点区别。你可以首先定义CNN模型,然后通过将CNN层的整个序列包括在TimeDistributed层中的方法将其添加到LSTM模型中,例如:
# define CNN model
cnn = Sequential()
cnn.add(Conv2D(...))
cnn.add(MaxPooling2D(...))
cnn.add(Flatten())
# define CNN LSTM model
model = Sequential()
model.add(TimeDistributed(cnn, ...))
model.add(LSTM(..))
model.add(Dense(...))
另一种,也许更容易阅读的方法是将CNN模型中的每一层封装在TimeDistributed中,然后将其添加到主模型中。
model = Sequential()
model.add(TimeDistributed(Conv2D(...))
model.add(TimeDistributed(MaxPooling2D(...)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(...))
model.add(Dense(...))
第二种方法的好处是所有的层都出现在模型的摘要中,因此这个是优选的。
基于Tensorflow的LSTM-CNN文本分类模型
首先通过Embedding Layer将单词转化为词向量,再输入LSTM进行语义特征提取,由于原始语料处理时进行了padding的操作,所以在LSTM输出时乘以MASK矩阵来减小padding所带来的影响。下一步将LSTM的输出作为CNN的输入,进行进一步的特征提取。最后得到分类结果。
整个模型的结构如下:

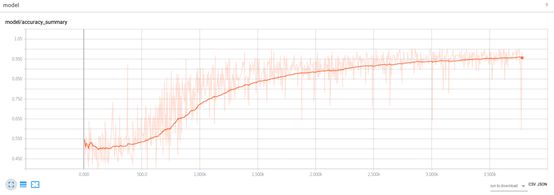
准确率:
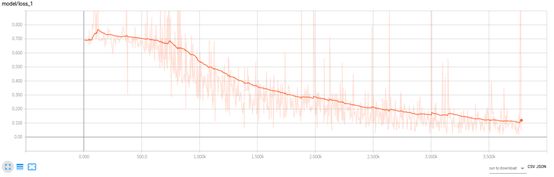
Loss Function:
基于TensorFlow使用LSTM和CNN实现时序分类任务
传统图像分类中也是采用的手动特征工程,然而随着深度学习的出现,卷积神经网络已经可以较为完美地处理计算机视觉任务。使用 CNN 处理图像不需要任何手动特征工程,网络会一层层自动从最基本的特征组合成更加高级和抽象的特征,从而完成计算机视觉任务。
卷积神经网络(CNN)
首先第一步就是将数据馈送到 Numpy 中的数组,且数组的维度为 (batch_size, seq_len, n_channels),其中 batch_size 为模型在执行 SGD 时每一次迭代需要的数据量,seq_len 为时序序列的长度(本文中为 128),n_channels 为执行检测(measurement)的通道数。
本案例中通道数为 9,即 3 个坐标轴每一个有 3 个不同的加速检测(acceleration measurement)。我们有六个活动标签,即每一个样本属于 LAYING、STANDING、SITTING、WALKING_DOWNSTAIRS、WALKING_UPSTAIRS 或 WALKING。
下面,我们首先构建计算图,其中我们使用占位符为输入数据做准备:
graph = tf.Graph()
with graph.as_default():
inputs_ = tf.placeholder(tf.float32, [None, seq_len, n_channels],
name = 'inputs')
labels_ = tf.placeholder(tf.float32, [None, n_classes], name = 'labels')
keep_prob_ = tf.placeholder(tf.float32, name = 'keep')
learning_rate_ = tf.placeholder(tf.float32, name = 'learning_rate')
其中 inputs_是馈送到计算图中的输入张量,第一个参数设置为「None」可以确保占位符第一个维度可以根据不同的批量大小而适当调整。labels_是需要预测的 one-hot 编码标签,keep_prob_为用于 dropout 正则化的保持概率,learning_rate_ 为用于 Adam 优化器的学习率。
我们使用在序列上移动的 1 维卷积核构建卷积层,图像一般使用的是 2 维卷积核。序列任务中的卷积核可以充当为训练中的滤波器。在许多 CNN 架构中,层级的深度越大,滤波器的数量就越多。每一个卷积操作后面都跟随着池化层以减少序列的长度。下面是我们可以使用的简单 CNN 架构。

上图描述的卷积层可用以下代码实现:
with graph.as_default():
# (batch, 128, 9) -> (batch, 32, 18)
conv1 = tf.layers.conv1d(inputs=inputs_, filters=18, kernel_size=2, strides=1,
padding='same', activation = tf.nn.relu)
max_pool_1 = tf.layers.max_pooling1d(inputs=conv1, pool_size=4, strides=4, padding='same')
# (batch, 32, 18) -> (batch, 8, 36)
conv2 = tf.layers.conv1d(inputs=max_pool_1, filters=36, kernel_size=2, strides=1,
padding='same', activation = tf.nn.relu)
max_pool_2 = tf.layers.max_pooling1d(inputs=conv2, pool_size=4, strides=4, padding='same')
# (batch, 8, 36) -> (batch, 2, 72)
conv3 = tf.layers.conv1d(inputs=max_pool_2, filters=72, kernel_size=2, strides=1,
padding='same', activation = tf.nn.relu)
max_pool_3 = tf.layers.max_pooling1d(inputs=conv3, pool_size=4, strides=4, padding='same')
一旦到达了最后一层,我们需要 flatten 张量并投入到有适当神经元数的分类器中,在上图中为 144 个神经元。随后分类器输出 logits,并用于以下两种案例:
• 计算 softmax 交叉熵函数,该损失函数在多类别问题中是标准的损失度量。
• 在最大化概率和准确度的情况下预测类别标签。
下面是上述过程的实现:
with graph.as_default():
# Flatten and add dropout
flat = tf.reshape(max_pool_3, (-1, 2*72))
flat = tf.nn.dropout(flat, keep_prob=keep_prob_)
# Predictions
logits = tf.layers.dense(flat, n_classes)
# Cost function and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,
labels=labels_)) optimizer = tf.train.AdamOptimizer(learning_rate_).minimize(cost)
# Accuracy
correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(labels_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32), name='accuracy')

长短期记忆网络(LSTM)
LSTM 在处理文本数据上十分流行,它在情感分析、机器翻译、和文本生成等方面取得了十分显著的成果。因为本问题涉及相似分类的序列,所以 LSTM 是比较优秀的方法。
下面是能用于该问题的神经网络架构:

为了将数据馈送到网络中,我们需要将数组分割为 128 块(序列中的每一块都会进入一个 LSTM 单元),每一块的维度为(batch_size, n_channels)。随后单层神经元将转换这些输入并馈送到 LSTM 单元中,每一个 LSTM 单元的维度为 lstm_size,一般该参数需要选定为大于通道数量。这种方式很像文本应用中的嵌入层,其中词汇从给定的词汇表中嵌入为一个向量。后面我们需要选择 LSTM 层的数量(lstm_layers),我们可以设定为 2。
对于这一个实现,占位符的设定可以和上面一样。下面的代码段实现了 LSTM 层级:
with graph.as_default():
# Construct the LSTM inputs and LSTM cells
lstm_in = tf.transpose(inputs_, [1,0,2]) # reshape into (seq_len, N, channels)
lstm_in = tf.reshape(lstm_in, [-1, n_channels]) # Now (seq_len*N, n_channels)
# To cells
lstm_in = tf.layers.dense(lstm_in, lstm_size, activation=None)
# Open up the tensor into a list of seq_len pieces
lstm_in = tf.split(lstm_in, seq_len, 0)
# Add LSTM layers
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
drop = tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob_)
cell = tf.contrib.rnn.MultiRNNCell([drop] * lstm_layers)
initial_state = cell.zero_state(batch_size, tf.float32)
上面的代码段是十分重要的技术细节。我们首先需要将数组从 (batch_size, seq_len, n_channels) 重建维度为 (seq_len, batch_size, n_channels),因此 tf.split 将在每一步适当地分割数据(根据第 0 个索引)为一系列 (batch_size, lstm_size) 数组。剩下的部分就是标准的 LSTM 实现了,包括构建层级和初始状态。
下一步就是实现网络的前向传播和成本函数。比较重要的技术点是引入了梯度截断,因为梯度截断可以在反向传播中防止梯度爆炸而提升训练效果。
下面是定义前向传播和成本函数的代码:
with graph.as_default():
outputs, final_state = tf.contrib.rnn.static_rnn(cell, lstm_in, dtype=tf.float32,
initial_state = initial_state)
# We only need the last output tensor to pass into a classifier
logits = tf.layers.dense(outputs[-1], n_classes, name='logits')
# Cost function and optimizer
cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels_))
# Grad clipping
train_op = tf.train.AdamOptimizer(learning_rate_)
gradients = train_op.compute_gradients(cost) capped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients] optimizer = train_op.apply_gradients(capped_gradients)
# Accuracy
correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(labels_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32), name='accuracy')