基于YOLOv4配置文件和c/c++代码编写搭建所需模块
本文分享本人开发yolov4所需要相关基础知识,以及如何在yolov4的配置文件和底层代码编写,搭建所需的模块,若错漏之处,欢迎大佬批评指正。
1. 浅谈Yolov4
Yolov4是Alexey AB等人在yolov3基础上,结合当时许多优秀策略构建的一个简单且高效模型,在《YOLOv4: Optimal Speed and Accuracy of Object Detectio》一文作者是通过大量实验验证当时最新检测策略效果,可见yolov4是集大量精华于一身,因此不建议初学者上来直接啃yolov4,可以考虑从学习yolov3框架出发,掌握yolov4的骨架Darknet53,再探索yolov4框架各项改进策略。
网上有许多优秀文章介绍yolo系列,这里推荐关于 yolov3和yolov4讲解两篇博客,作者都是Bubbliiiing,分别是《睿智的目标检测26——Pytorch搭建yolo3目标检测平台》和《睿智的目标检测30——Pytorch搭建YoloV4目标检测平台》。
2. Yolov4代码框架基础理解
由于工程需要,本文基于c/c++的Yolov4进行开发,源码来自AlexeyAB开源,开源项目已经介绍如何在windows,Linux系统等下配置过程,当然刚上来同学像我可能对开源中各项命令理解不够深,相对迷茫,因此基于windows系统的环境配置可以参考b站中作者为神秘二进制的视频《史上最详细基于C++的YOLOV4搭建到开发视频》,理解相对简单些。
再回到yolov4整体结构,可以看到yolov4主要由特征提取模块Darknet53,特征融合模块PANET,回归预测模块yolo head,金字塔最大池化层SPP组成。如果想基于YOLOv4配置文件和c/c++代码编写搭建所需模块,还需要对yolo底层有一定理解,这里推荐AB DarkNet版源码解读,给出yolov3框架分析和代码部分注释,有助于理解,该文章简单介绍相关基础。
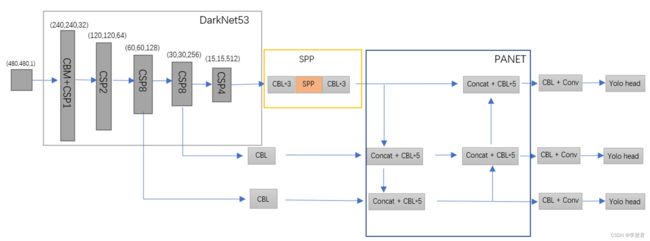 YOLOv4整体框架
YOLOv4整体框架
2.1 配置文件理解
Yolov4参数修改和网络结构搭建可以通过配置文件 .cfg 文件进行操作,配置文件中以"[ ]"分层,“#”为注释。这里以[net]层和[convolutional]层解读如何通过配置文件修改。
2.1.1 [net]层参数理解与修改
[net]
batch=64 #每次迭代训练的图片总数
subdivisions=8 #将batch个图片分成subdivision子块,由子块中所有图片完成一次前后向传播,
#所有子块完成训练,为一次迭代完成
width=608 #网络的宽,高,必须为32的倍数
height=608
channels=3 #三通图片,灰度图修改为:channels=3
momentum=0.949 #Adam(Adaptive Moment Estimation)动量法参数
decay=0.0005 #权重衰减正则系数,防止过拟合
angle=0 #旋转角度,生成更多训练样本,增强泛化能力
saturation = 1.5 #调整饱和度,channel=1,该参数不起作用
exposure = 1.5 #调整曝光度
hue=.1 #调整色调,channel=1,该参数不起作用
learning_rate=0.001 #学习率
burn_in=1000 #学习率控制的参数在迭代次数小于burn_in时,采用policy的更新方式:
#0.001 * pow(iterations/1000, 4)
max_batches = 500500 #最大迭代参数,=训练集的目标种类*2000(官方建议)
policy=steps
steps=400000,450000
scales=.1,.1 #上面的三行命令表示:采用steps策略更新学习率,在400000和450000迭代次
#数时候学习率分别乘以0.1
mosaic=1实际训练过程中,根据GPU条件可以调整batch和subdivision,训练策略不仅可以采用steps,还可以使用sgdr, steps, step, sig, exp, poly等方式,各个学习率理解文章推荐《CS231n: Convolutional Neural Networks for Visual Recognition》,修改也很简单,如需要改成采用余弦退火方式更新学习率的训练方法,制定热重启周期为10000,可以修改为:
learning_rate=0.001 #学习率
burn_in=1000 #学习率控制的参数在迭代次数小于burn_in时,采用policy的更新方式:
#0.001 * pow(iterations/1000, 4)
max_batches = 500500 #最大迭代参数,=训练集的目标种类*2000(官方建议)
policy=sgdr #采用余弦学习策略
sgdr_cycle=10000 #余弦退火学习学习率初始循环次数10000
sgdr_mult=2 #余弦退火学习率的循环次数每次翻倍
mosaic=1 余弦退火学习率参数理解
余弦退火学习率参数理解
sgdr_mult=2热重启循环次数将翻倍,在yolov4训练过程中,前10000次迭代,学习率从0.001开始,学习率按照余弦函数下降至0.00001(可以在配置文件指定learning_rate_min大小修改)。
2.1.2 [convolution]层参数理解与修改
[convolutional]
batch_normalize=1 #采用正则化
filters=32 #卷积个数或者输出通道数
size=3 #卷积大小
stride=1 #步长
pad=1 #是否进行padding操作,即补0
activation=mish #激活函数采用mishyolov4在yolov3基础上扩展很多板块,如采用分组卷积和空洞卷积减少参数量,具体参数为:
group=2 #分组卷积,三组
dilation=2 #空洞卷积,等效空洞卷积参数rate=2默认情况下group=1,dilation=1。设置group=3表示分三组分别进行卷积,可以减少卷积的次数,如下图所示
 分组卷积
分组卷积
设置空洞卷积可以修改dilation ,dilation=2示意图如下,空洞卷积主要在捕获多尺度的上下文信息同时,减少参数量。
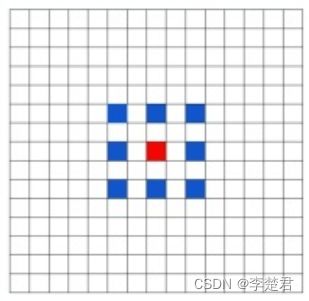 空洞卷积dilation=2
空洞卷积dilation=2
2.2 训练流程相关函数简介
目前很多板块在yolov4中已经开发通过配置文件即可修改,只需要注意参数的设置和默认情况是否满足要求,但是当我们开发的模块在源码中没有,就需要基于代码进行开发,先来理解一下yolov4训练过程中应用的主要函数
 训练流程
训练流程
2.3 CUDA编程学习模块推荐
yolov4可以在CPU或GPU上进行训练,因此基于底层开发,还需要学习CUDA编程基础,相关文章推荐知乎上作者为科技猛兽的文章《CUDA 编程(一):CUDA C 编程及 GPU 基本知识》,该文章面向零基础同学。
3 SKNet模块搭建
这里正式进入本章重点,SKNet的全称是“Selective Kernel Network”,启发于自皮质神经元根据不同的刺激可动态调节其自身的receptive field,本文主要阐述该模块的搭建过程,讲述如何在yolov4的配置文件和底层代码中搭建自己所需要的模块。
3.1 SKNET模块简介
SKNET主要由分裂算子,融合算子和选择算子组成,如图所示。选择算子通过softmax函数和通道注意力机制思想选择不同路径的特征层。
 SKNET
SKNET
分裂算子:给定任意的特征图,采用 两类卷积核进行特征提取,由不同大小的感受野的多条路径组成,感受野比较大的路径可以通过空洞卷积轻量化网络。
融合算子:通过相加操作融合多条路径不同感受野下的信息,通过全局平均池化和全连接生成自适应权重。
 全局平均池化
全局平均池化
 全连接自适应选择权重
全连接自适应选择权重
其中,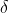 表示采用relu函数,B表示采用归一化操作。
表示采用relu函数,B表示采用归一化操作。
选择算子:通过softmax函数和通道注意力机制思想选择不同路径的特征层。
 softmax回归的权重公式
softmax回归的权重公式
通过上述关系可以看到通过两个通道通过softmax回归权重具有相互制约关系,要求对应通道的权重的之和为1。接着采用特征选择和相加的融合操作,公式如下
 特征选择与融合操作
特征选择与融合操作
事实上,SKNET模块各个部件通过yolov4源码都能进行配置,这里主要阐述需要基于代码开发的softmax函数。
3.2 SKNET模块在cfg文件中配置
先给出SKNET各个模块的基本作用和cfg文件的配置
################################################sknet begin#############
# 分裂模块,路径1 感受野大小3*3
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
# 分裂模块,路径2 感受野大小5*5 空洞卷积dilation=2
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
dilation=2
# 融合模块,采用相加操作
[shortcut]
from=-3
activation=linear
# 融合模块,全局池化
[avgpool]
# 自适应选择权重
# squeese ratio r=4(recommmended r=16) 设置比例
[convolutional]
filters=128
size=1
stride=1
activation=leaky
[convolutional]
filters=512
size=1
stride=1
activation=leaky
# softmax函数回归
[softmax]
SMFAttention=1
SMReverse=0
# 加权选择特征层
[scale_channels]
from=-8
[route]
layers =-3
[softmax]
SMFAttention=1
SMReverse=1
[scale_channels]
from=-9
# 结合,采用相加操作,linear函数等效不采用激活函数
[shortcut]
from=-4
activation=linear
###############################################sknet end################3.3 代码配置
事实上yolov4的在最后检测回归中已经采用过[softmax],但是一方面该[softmax]层并不适用SKNET中存在两通道的制约形式,另外一方面由于位置特殊,其反向传播误差采用搬运并非采用梯度下降。因此需要基于该板块进行更新,在上述配置文件中,参数SMFAttention是最新引进来的,前者是基于调用[softmax]层位置决定,放置中间则是应用于注意力模块,SMFAttention设置为1,否则采用yolov4原来[softmax]的功能。
3.3.1 softmax层前向传播公式
softmax函数公式如下,值域为[0,1],当规定SKNET中一通道函数如下时候,另外一通道可以表示为![]()
 softmax函数公式
softmax函数公式
在上述配置文件中,SMReverse是最新引进来决定特定通道采用上述一种运算的,SMReverse=0采用yi,否则采用![]() 。
。
3.3.2 反向传播的公式
由softmax函数公式可以知道前向传播每通道都互相影响的,因此反向传播每通道都包含其他通道误差,先对每通道求导 :xi表示softmax层的第i通道输入,yi表示softmax层第i通道的输出。
 softmax求导1
softmax求导1
 softmax函数求导公式2
softmax函数求导公式2
反向传播误差传递,以E表示总误差,![]() i表示第i层误差像,整体公式如下:
i表示第i层误差像,整体公式如下:
 softmax函数反向传播
softmax函数反向传播
另一通道可以参数代换求得,这里不展开推导。
3.3.3 softmax层代码
首先SMFAttention和SMFAttention参数设置,首先需要在darknet.c文件中的struct layer {};中定义。
// layer.h
struct layer {
...
LAYER_TYPE type;
ACTIVATION activation;
ACTIVATION lstm_activation;
COST_TYPE cost_type;
int train;
// 修改
int SMFAttention;
int SMReverse;
...
};接着在parser.c文件中,添加导入参数的函数:
softmax_layer parse_softmax(list *options, size_params params)
{
int groups = option_find_int_quiet(options, "groups", 1);
softmax_layerR layer = make_softmax_layerR(params.batch, params.inputs, groups);
layer.temperature = option_find_float_quiet(options, "temperature", 1);
char *tree_file = option_find_str(options, "tree", 0);
// if (tree_file) layer.softmax_tree = read_tree(tree_file);
layer.w = params.w;
layer.h = params.h;
layer.c = params.c;
// layer.spatial = option_find_float_quiet(options, "spatial", 0);
// layer.noloss = option_find_int_quiet(options, "noloss", 0);
//修改 默认值为0
layer.SMFAttention = option_find_int_quiet(options, "SMFAttention", 0);
layer.SMReverse = option_find_int_quiet(options, "SMReverse", 0);
//
return layer;
}考虑到Yolov4在训练过程会随机调整网络的尺寸,尺寸调整幅度都是32的倍数,在softmax_layer.c文件中代码如下,还需在softmax_layer.h文件添加函数声明。
void resize_softmax_layerR(softmax_layerR *l, int w, int h)
{
l->w = w;
l->h = h;
l->inputs = h*w*l->c;
}在softmax_layer.h文件中进行相关函数声明:
#ifndef SOFTMAX_LAYER_ATTENTION_H
#define SOFTMAX_LAYER_ATTENTION_H
#include "layer.h"
#include "network.h"
typedef layer softmax_layerR;
#ifdef __cplusplus
extern "C" {
#endif
softmax_layerR make_softmax_layerR(int batch, int inputs, int groups);
void forward_softmax_layerR(const softmax_layerR l, network_state state);
void backward_softmax_layerR(const softmax_layerR l, network_state state);
void resize_softmax_layerR(softmax_layerR *l, int w, int h);
#ifdef GPU
void forward_softmax_layer_gpuR(const softmax_layerR l, network_state state);
void backward_softmax_layer_gpuR(const softmax_layerR l, network_state state);
#endif
//-----------------------
#ifdef __cplusplus
}
#endif
#endif
在softmax.c中函数定义:
#include "softmax_layer_attention.h"
#include "blas.h"
#include "dark_cuda.h"
#include "utils.h"
#include "blas.h"
#include
#include
#include
#include
#include
#define SECRET_NUM -1234
softmax_layerR make_softmax_layerR(int batch, int inputs, int groups)
{
assert(inputs%groups == 0);
fprintf(stderr, "softmax %4d\n", inputs);
softmax_layerR l = { (LAYER_TYPE)0 };
l.type = SOFTMAX;
l.batch = batch;
l.groups = groups;
l.inputs = inputs;
// l.outputs = inputs;
// 修改
l.h = 1;
l.w = 1;
l.c = inputs;
l.out_h = 1;
l.out_w = 1;
l.out_c = inputs;
l.outputs = l.out_h * l.out_w * l.out_c;
//l.loss = (float*)xcalloc(inputs * batch, sizeof(float));
l.output = (float*)xcalloc(inputs * batch, sizeof(float));
l.delta = (float*)xcalloc(inputs * batch, sizeof(float));
//l.cost = (float*)xcalloc(1, sizeof(float));
l.forward = forward_softmax_layerR;
l.backward = backward_softmax_layerR;
#ifdef GPU
l.forward_gpu = forward_softmax_layer_gpuR;
l.backward_gpu = backward_softmax_layer_gpuR;
l.output_gpu = cuda_make_array(l.output, inputs*batch);
//l.loss_gpu = cuda_make_array(l.loss, inputs*batch);
l.delta_gpu = cuda_make_array(l.delta, inputs*batch);
#endif
return l;
}
// 重新定义,随机调整网络结构
void resize_softmax_layerR(softmax_layerR *l, int w, int h)
{
l->w = w;
l->h = h;
l->inputs = h*w*l->c;
}
// 前向传播
void forward_softmax_layerR(const softmax_layerR l, network_state net)
{
if (!l.SMFAttention) {//not use for attention
softmax_cpu(net.input, l.inputs / l.groups, l.batch, l.inputs, l.groups, l.inputs / l.groups, 1, l.temperature, l.output);
}
else {
// changed in 3 m 8 d
softmax_cpuR(net.input, l.inputs / l.groups, l.batch, l.inputs, l.groups, l.inputs / l.groups, 1, l.temperature, l.output, l.SMReverse);
}
}
// 反向传播
void backward_softmax_layerR(const softmax_layerR l, network_state net)
{
if (!l.SMFAttention) {
axpy_cpu(l.inputs*l.batch, 1, l.delta, 1, net.delta, 1);
}
else {
backward_softmax_cpuR(l.output,l.delta,l.inputs/l.groups,l.batch,l.inputs,l.groups,l.inputs/l.groups,1,l.temperature,net.delta,l.SMReverse);
}
}
#ifdef GPU
// GPU中前线传播
void forward_softmax_layer_gpuR(const softmax_layerR l, network_state net)
{
if (!l.SMFAttention) {
softmax_gpu_new_api(net.input, l.inputs / l.groups, l.batch, l.inputs, l.groups, l.inputs / l.groups, 1, l.temperature, l.output_gpu);
}
else {
softmax_gpu_new_apiR(net.input, l.inputs / l.groups, l.batch, l.inputs, l.groups, l.inputs / l.groups, 1, l.temperature, l.output_gpu, l.SMReverse);
}
}
// GPU反向传播
void backward_softmax_layer_gpuR(const softmax_layerR l, network_state state)
{
if (!l.SMFAttention) {
axpy_ongpu(l.batch*l.inputs, state.net.loss_scale, l.delta_gpu, 1, state.delta, 1);
}
else {
backward_softmax_gpuR(l.output_gpu, l.delta_gpu, l.inputs / l.groups, l.batch, l.inputs, l.groups, l.inputs / l.groups, 1, l.temperature, state.delta, l.SMReverse);
}
}
#endif
CPU,GPU的编程主要实现首先在blas.h文件中声明相关函数:
void softmaxR(float *input, int n, float temp, float *output, int stride, int smreverse);
void softmax_cpuR(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output,int smreverse);
void backward_softmaxR(float*output, float *delta_output, int n, float temp, int stride, float *delta_input, int smreverse);
void backward_softmax_cpuR(float*output, float*delta_output, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float*delta_input,int smreverse);
void softmax_gpu_new_apiR(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output,int smreverse);
void backward_softmax_gpuR(float*output, float*delta_output, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float*delta_input, int smreverse);
CPU编程定义主要在blas.c中
void softmax_cpu(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output)
{
int g, b;
for(b = 0; b < batch; ++b){
for(g = 0; g < groups; ++g){
softmax(input + b*batch_offset + g*group_offset, n, temp, output + b*batch_offset + g*group_offset, stride);
}
}
}
void softmaxR(float *input, int n, float temp, float *output, int stride, int smreverse) {
if (smreverse) {
int i;
float sum = 0;
float largest = -FLT_MAX;
for (i = 0; i < n; ++i) {
if (input[i*stride] > largest) largest = input[i*stride];
}
for (i = 0; i < n; ++i) {
float e = exp(input[i*stride] / temp - largest / temp);
sum += e;
output[i*stride] = e;
}
for (i = 0; i < n; ++i) {
output[i*stride] = 1- output[i*stride]/sum;
}
}
else {
int i;
float sum = 0;
float largest = -FLT_MAX;
for (i = 0; i < n; ++i) {
if (input[i*stride] > largest) largest = input[i*stride];
}
for (i = 0; i < n; ++i) {
float e = exp(input[i*stride] / temp - largest / temp);
sum += e;
output[i*stride] = e;
}
for (i = 0; i < n; ++i) {
output[i*stride] /= sum;
}
}
}
void softmax_cpuR(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output, int smreverse) {
int g, b;
for (b = 0; b < batch; ++b) {
for (g = 0; g < groups; ++g) {
softmaxR(input + b*batch_offset + g*group_offset, n, temp, output + b*batch_offset + g*group_offset, stride,smreverse);
}
}
}
void backward_softmaxR(float*output, float *delta_output, int n, float temp, int stride, float *delta_input, int smreverse) {
// n the number
// stride = groups
int i;
if (!smreverse) {
float dot = dot_cpu(n, output, 1, delta_output, 1);
float temp_inv = 1.0 / temp;
for (i = 0; i < n; ++i) {
delta_input[i*stride] += temp_inv*output[i*stride] * (delta_output[i*stride] - dot);
}
}
else {
float dot = 0;
float sumDelta = 0;
for (i = 0; i < n; i++) {
sumDelta += delta_output[i*stride];//1 3
dot += output[i*stride] * delta_output[i*stride];//2 4
}
float temp_inv = 1.0 / temp;
//reverse
//1
for (i = 0; i < n; ++i) {
//delta_input[i*stride] += (-temp_inv*output[i*stride] * (delta_output[i*stride] + dot));
delta_input[i*stride] += temp_inv*(-output[i*stride]*sumDelta)+(output[i*stride]*dot)+(sumDelta-delta_output[i*stride])-(dot-delta_output[i*stride]*output[i*stride]);
}
}
}
void backward_softmax_cpuR(float*output, float*delta_output, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float*delta_input, int smreverse) {
int g, b;
int offset;
for (b = 0; b < batch; ++b) {
for (g = 0; g < groups; ++g) {
offset = b*batch_offset + g*group_offset;
backward_softmaxR(output + offset, delta_output + offset, n, temp, stride, delta_input + offset,smreverse);
}
}
}
GPU的编程定义主要在blas_kernels.cu中:
__device__ void softmax_device_new_api(float *input, int n, float temp, int stride, float *output)
{
int i;
float sum = 0;
float largest = -INFINITY;
for (i = 0; i < n; ++i) {
int val = input[i*stride];
largest = (val>largest) ? val : largest;
}
for (i = 0; i < n; ++i) {
float e = expf(input[i*stride] / temp - largest / temp);
sum += e;
output[i*stride] = e;
}
for (i = 0; i < n; ++i) {
output[i*stride] /= sum;
}
}
__global__ void softmax_kernel_new_api(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output)
{
int id = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if (id >= batch*groups) return;
int b = id / groups;
int g = id % groups;
softmax_device_new_api(input + b*batch_offset + g*group_offset, n, temp, stride, output + b*batch_offset + g*group_offset);
}
extern "C" void softmax_gpu_new_api(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output)
{
softmax_kernel_new_api << > >(input, n, batch, batch_offset, groups, group_offset, stride, temp, output);
CHECK_CUDA(cudaPeekAtLastError());
}
// changed in 3m 28d
__device__ void softmax_device_new_apiR(float *input, int n, float temp, int stride, float *output,int smreverse)
{
if (!smreverse) {
int i;
float sum = 0;
float largest = -INFINITY;
for (i = 0; i < n; ++i) {
int val = input[i*stride];
largest = (val>largest) ? val : largest;
}
for (i = 0; i < n; ++i) {
float e = expf(input[i*stride] / temp - largest / temp);
sum += e;
output[i*stride] = e;
}
for (i = 0; i < n; ++i) {
output[i*stride] /= sum;
}
}
else {
int i;
float sum = 0;
float largest = -INFINITY;
for (i = 0; i < n; ++i) {
int val = input[i*stride];
largest = (val>largest) ? val : largest;
}
for (i = 0; i < n; ++i) {
float e = expf(input[i*stride] / temp - largest / temp);
sum += e;
output[i*stride] = e;
}
for (i = 0; i < n; ++i) {
output[i*stride] = 1- output[i*stride]/sum;
}
}
}
__global__ void softmax_kernel_new_apiR(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output, int smreverse)
{
int id = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if (id >= batch*groups) return;
int b = id / groups;
int g = id % groups;
softmax_device_new_apiR(input + b*batch_offset + g*group_offset, n, temp, stride, output + b*batch_offset + g*group_offset,smreverse);
}
extern "C" void softmax_gpu_new_apiR(float *input, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float *output,int smreverse)
{
softmax_kernel_new_apiR << > >(input, n, batch, batch_offset, groups, group_offset, stride, temp, output, smreverse);
CHECK_CUDA(cudaPeekAtLastError());
}
__device__ void backward_softmax_deviceR(float*output, float *delta_output, int n, float temp, int stride, float *delta_input, int smreverse) {
if (!smreverse) {
int i;
float dot = 0;
for (i = 0; i < n; i++) {
dot += output[i*stride] * delta_output[i*stride];
}
float temp_inv = 1.0 / temp;
for (i = 0; i < n; ++i) {
delta_input[i*stride] += temp_inv*output[i*stride] * (delta_output[i*stride] - dot);
}
}
else {
int i;
float dot = 0;
float sumDelta = 0;
for (i = 0; i < n; i++) {
sumDelta += delta_output[i*stride];//1 3
dot += output[i*stride] * delta_output[i*stride];//2 4
}
float temp_inv = 1.0 / temp;
//reverse
//1
for (i = 0; i < n; ++i) {
//delta_input[i*stride] += (-temp_inv*output[i*stride] * (delta_output[i*stride] + dot));
delta_input[i*stride] += temp_inv*(-output[i*stride]*sumDelta)+(output[i*stride]*dot)+(sumDelta-delta_output[i*stride])-(dot-delta_output[i*stride]*output[i*stride]);
}
}
}
__global__ void backward_softmax_kernelR(float*output, float*delta_output, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float*delta_input, int smreverse) {
int id = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if (id >= batch*groups) return;
int b = id / groups;
int g = id % groups;
int offset = b*batch_offset + g*group_offset;
backward_softmax_deviceR(output + offset, delta_output + offset, n, temp, stride, delta_input + offset, smreverse);
}
extern "C" void backward_softmax_gpuR(float*output, float*delta_output, int n, int batch, int batch_offset, int groups, int group_offset, int stride, float temp, float*delta_input, int smreverse) {
backward_softmax_kernelR << > >(output, delta_output, n, batch, batch_offset, groups, group_offset, stride, temp, delta_input,smreverse);
CHECK_CUDA(cudaPeekAtLastError());
}
如果错漏之处,欢迎批评指正!