基于CNN的垃圾分类识别系统
昨天在整理电脑资料的时候无意间发现了前两年下载的数据集,应该是哪里举办的比赛,赛题就是垃圾分类识别相关的任务,当时其实做了一些工作,无奈后面没有继续了就搁置了,最近一年多的时间大都在做CV的项目,今天看到这个数据集,萌生了继续做的想法,于是我拿出上周用来做云状识别开发的模型,改造了一下就可以直接用到这个垃圾分类识别数据集上面了。
首先看下效果:
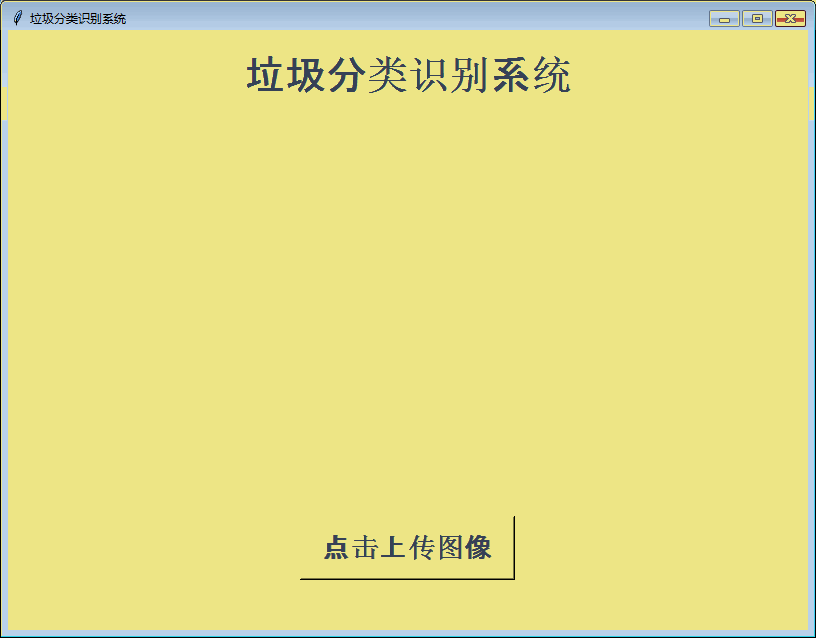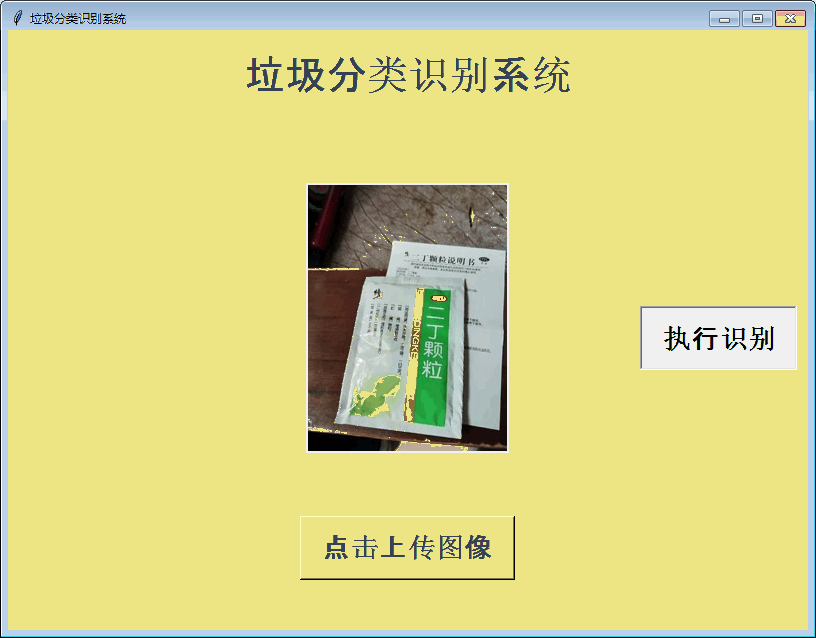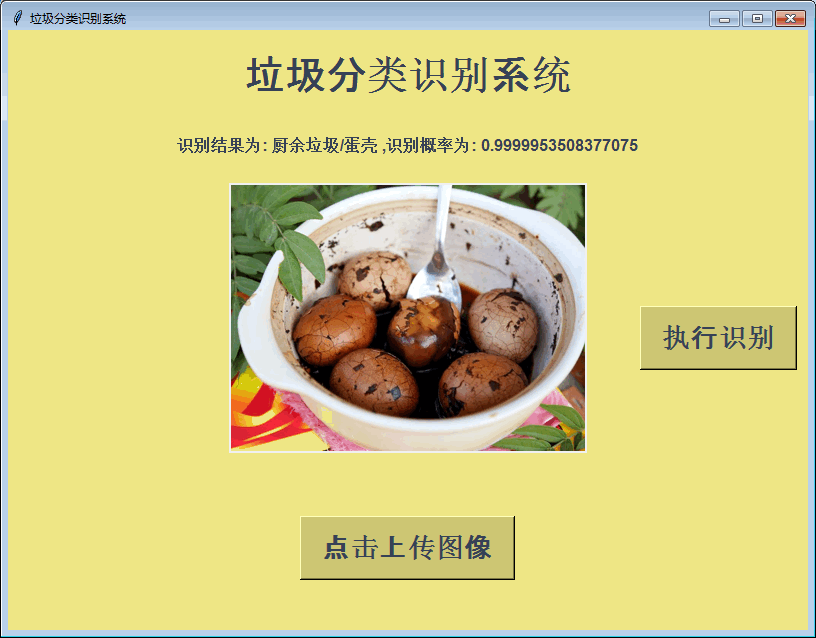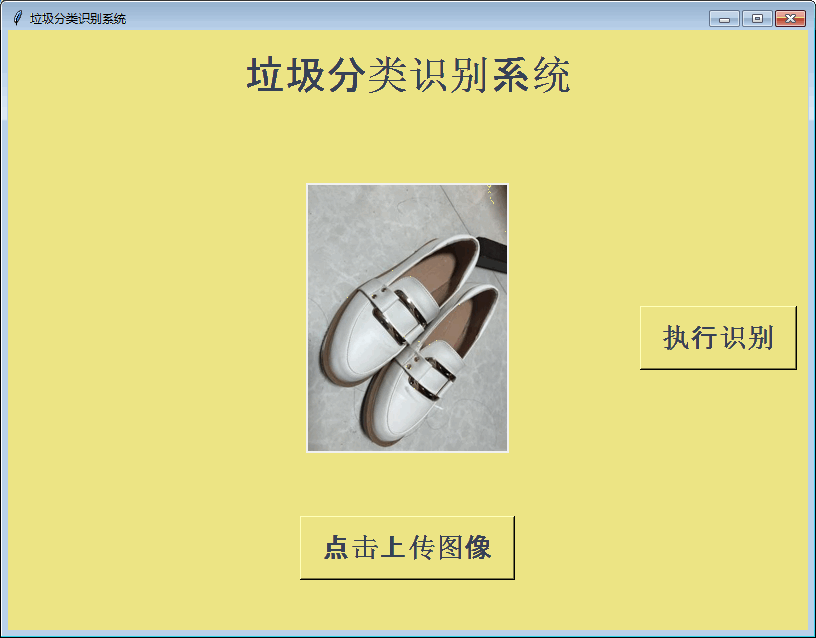
这里的垃圾总分类一共有40个类别,也就是多分类任务,各垃圾类别详情如下所示:
{
"0": "其他垃圾/一次性快餐盒",
"1": "其他垃圾/污损塑料",
"2": "其他垃圾/烟蒂",
"3": "其他垃圾/牙签",
"4": "其他垃圾/破碎花盆及碟碗",
"5": "其他垃圾/竹筷",
"6": "厨余垃圾/剩饭剩菜",
"7": "厨余垃圾/大骨头",
"8": "厨余垃圾/水果果皮",
"9": "厨余垃圾/水果果肉",
"10": "厨余垃圾/茶叶渣",
"11": "厨余垃圾/菜叶菜根",
"12": "厨余垃圾/蛋壳",
"13": "厨余垃圾/鱼骨",
"14": "可回收物/充电宝",
"15": "可回收物/包",
"16": "可回收物/化妆品瓶",
"17": "可回收物/塑料玩具",
"18": "可回收物/塑料碗盆",
"19": "可回收物/塑料衣架",
"20": "可回收物/快递纸袋",
"21": "可回收物/插头电线",
"22": "可回收物/旧衣服",
"23": "可回收物/易拉罐",
"24": "可回收物/枕头",
"25": "可回收物/毛绒玩具",
"26": "可回收物/洗发水瓶",
"27": "可回收物/玻璃杯",
"28": "可回收物/皮鞋",
"29": "可回收物/砧板",
"30": "可回收物/纸板箱",
"31": "可回收物/调料瓶",
"32": "可回收物/酒瓶",
"33": "可回收物/金属食品罐",
"34": "可回收物/锅",
"35": "可回收物/食用油桶",
"36": "可回收物/饮料瓶",
"37": "有害垃圾/干电池",
"38": "有害垃圾/软膏",
"39": "有害垃圾/过期药物"
}将其对应划归到不同索引目录中,如下所示:
随便抽样几个类别的数据集,如下所示:
【0】

【6】

【13】
【24】

【37】

原始数据集处理代码如下:
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能: 数据归类处理
'''
import os
import random
import shutil
saveDir='data/'
file_list=os.listdir('train_data_v2/')
name_list=list(set([one.strip().split('.')[0].strip() for one in file_list]))
for one_name in name_list:
one_png='train_data_v2/'+one_name+'.jpg'
one_txt='train_data_v2/'+one_name+'.txt'
with open(one_txt) as f:
one_label=f.read().strip().split(',')[-1].strip()
oneDir=saveDir+one_label+'/'
if not os.path.exists(oneDir):
os.makedirs(oneDir)
new_path=oneDir+str(len(os.listdir(oneDir))+1)+'.png'
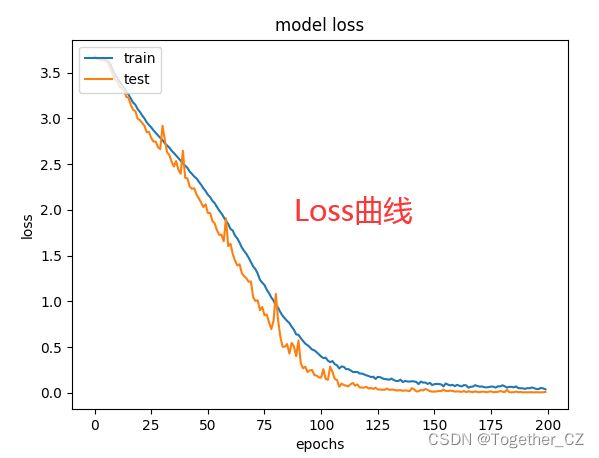
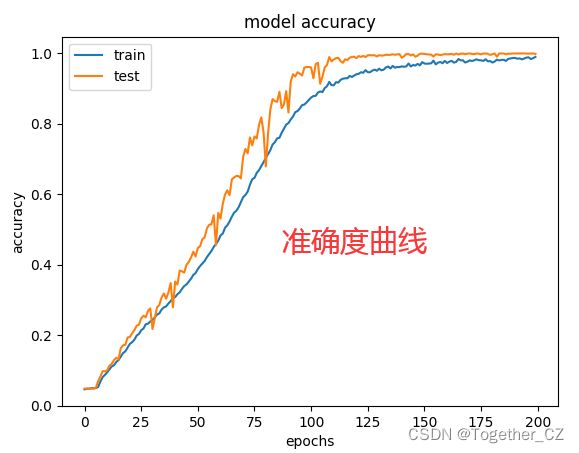
shutil.move(one_png,new_path)这里使用的是与前面博文云状识别同样的模型,只不过改成了多分类模型,这里就不再多介绍了,感兴趣的话可以直接去看前面的博文,这里我默认执行了200次的迭代计算,过程可视化如下所示:

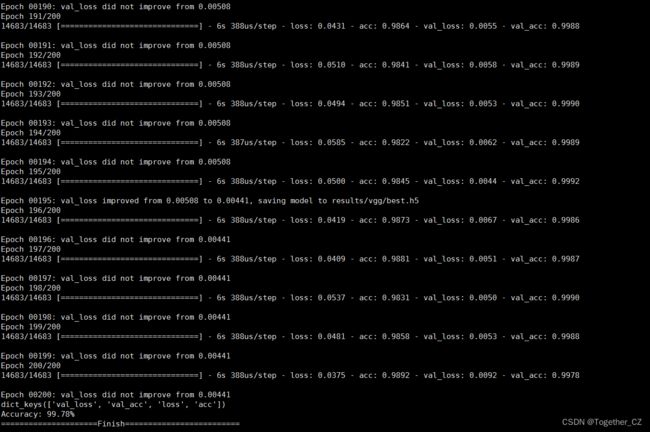
准确度曲线:
Loss曲线