Numpy基础:数组的创建,数据类型,切片索引
NumPy(Numerical Python)是Python科学计算的基础包。它提供了以下功能(不限于此):
- 快速高效的多维数组对象ndarray。 用于对数组执行元素级计算以及直接对数组执行数学运算的函数。
- 用于读写硬盘上基于数组的数据集的工具。
- 线性代数运算、傅里叶变换,以及随机数生成等。
- 成熟的C API, 用于Python插件和原生C、C++、Fortran代码访问NumPy的数据结构和计算设施。
除了为Python提供快速的数组处理能力,NumPy在数据分析方面还有另外一个主要作用,即作为在算法和库之间传递数据的容器。对于数值型数据,NumPy数组在存储和处理数据时要比内置的Python数据结构高效得多。此外,NumPy可以在整个数组上执行复杂的计算,而不需要Python的for循环,基于NumPy的算法要比纯Python快10到100倍(甚至更快),并且使用的内存更少。
1 NumPy ndarray:多维数组对象
我们可以通过array函数来生成一个新的包含传递数据的Numpy 数组。
import numpy as np
array1=np.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 参数 | 描述 |
|---|---|
| object | 传入的数据,可以使列表(list)、集合(set)、元组(tuple)、字符串(str)等 |
| dtype | 数组的所需数据类型,默认为空,可选,如:dtype=np.float64等 |
| oder | C(按行)、F(按列)、A(任意,默认) |
| subok | 默认情况下,返回的数组被强制为基类数组。 如果为True,则返回子类 |
| ndimin | 指定返回数组的维数,如ndimin=2。 |
当然,数组生成函数肯定不止array函数一个,还有许许多多:
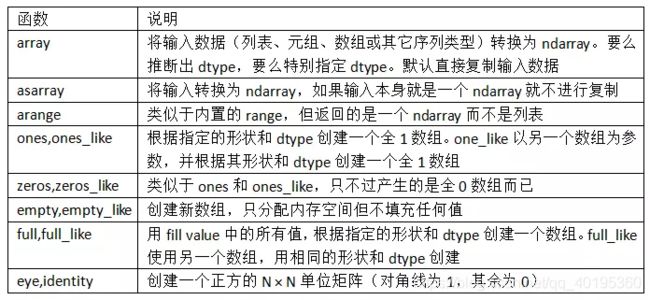
2 ndarray的数据类型(dtype)
NumPy 支持比 Python 更多种类的数值类型。dtype是NumPy灵活交互其它系统的源泉之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码(如C、Fortran)”等工作变得更加简单。数值型dtype的命名方式相同:一个类型名(如float或int),后面跟一个用于表示各元素位长的数字。标准的双精度浮点值(即Python中的float对象)需要占用8字节(即64位)。因此,该类型在NumPy中就记作float64。
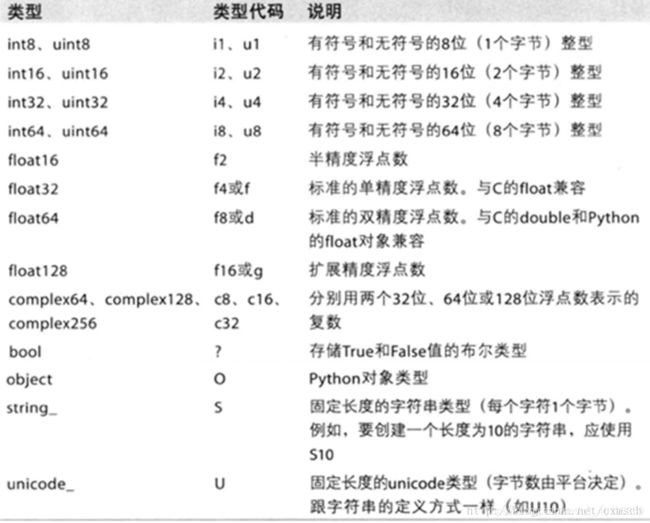
当然,你也可以通过ndarray的astype方法明确地将一个数组从一个dtype转换成另一个dtype:
array=np.array([1,2,3,4,5,6,7,8])
print(array)
print(array.dtype)
输出如下
[1 2 3 4 5 6 7 8]
int32
float_array=array.astype(np.float64)
print(float_array)
print(float_array.dtype)
输出如下
[1. 2. 3. 4. 5. 6. 7. 8.]
float64
在本例中,整数被转换成了浮点数。如果将浮点数转换成整数,则小数部分将会被截取删除。
3 NumPy 数组的运算
NumPy 数组的运算它可以使你在不用编写循环就可以对数据执行批量运算。大小相等的数组之间的任何算术运算(加减乘数)都会将运算应用到元素级:
array1=np.array([[1,2,3],[4,5,6]])
array2=np.array([[7,8,9],[4,5,6]])
示例1:
array1+array2
输出:
array([[ 8, 10, 12],
[ 8, 10, 12]])
示例2:
array1*array2
输出:
array([[ 7, 16, 27],
[16, 25, 36]])
大小相同的数组之间的比较会生成布尔值数组:
array1输出:
array([[ True, True, True],
[False, False, False]])
当然,不同大小的数组之间也是可以进行计算的,这种计算叫做广播(这种以后在做介绍)。
4 NumPy 基础的索引和切片
ndarray对象的内容可以通过索引或切片来访问和修改,就像 Python 的内置容器对象一样。如前所述,ndarray对象中的元素遵循基于零的索引。 有三种可用的索引方法类型: 字段访问,基本切片和高级索引。
示例1:
array3=np.arange(10)
s=slice(2,7,2)
array[s]
输出
array([2, 4, 6])
在上面的例子中,ndarray对象由arange()函数创建。 然后,通过将start,stop和step参数提供给内置的slice函数来构造一个 Python slice对象,分别用起始,终止和步长值2,7和2定义切片对象。 当这个切片对象传递给ndarray时,会对它的一部分进行切片,从索引2到7,步长为2。
通过将由冒号分隔的切片参数(start:stop:step)直接提供给ndarray对象,也可以获得相同的结果。
示例2:
array3=np.arange(10)
array4=array3[2:7:2]
array4
输出:
array([2, 4, 6])
NumPy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。一维数组很简单。从表面上看,它们跟Python列表的功能差不多。
但是,对于高维度数组,能做的事情更多。在一个二维数组中,各索引位置上的元素不再是标量而是一维数组。
示例1:
array5=np.array([[1,2,3],[4,5,6],[7,8,9]])
array5[2]
输出:
array([7, 8, 9])
你也可以对各个元素进行递归访问,但这样需要做的事情有点多。你可以传入一个以逗号隔开的索引列表来选取单个元素。也就是说,下面两种方式是等价的:
示例2:
array5[0][2]
输出:
3
输入:
array5[0,2]
输出:
3
关于二维数组的取值方式,可看下图,轴0作为行,轴1作为列。
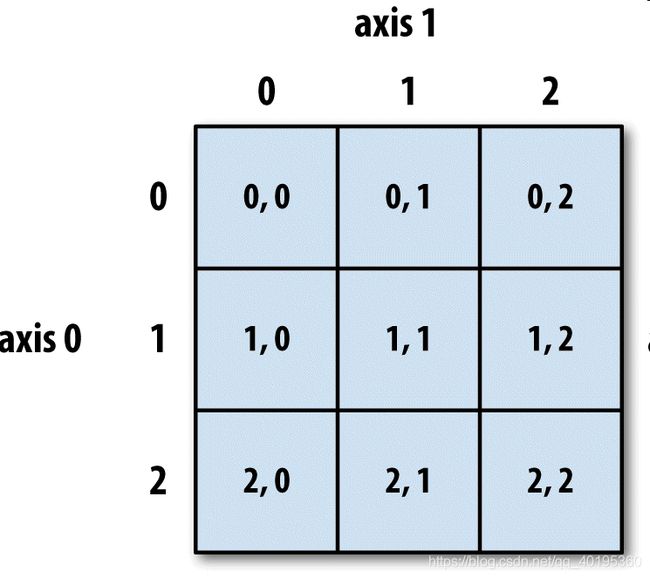
切片索引
adarray 的一维切片前面已经介绍,这里将介绍二维甚至更高维的切片方式。
示例1:
array5[:2]
输出:
array([[1, 2, 3],
[4, 5, 6]])
切片是沿着一个轴向选取元素的。表达式array5[:2]可以被认为是“选取array5的前两行”。
你可以一次传入多个切片,就像传入多个索引那样:
示例2:
array5[:2,:2]
输出:
array([[1, 2],
[4, 5]])
像这样进行切片时,只能得到相同维数的数组视图。通过将整数索引和切片混合,可以得到低维度的切片。如下图所示:
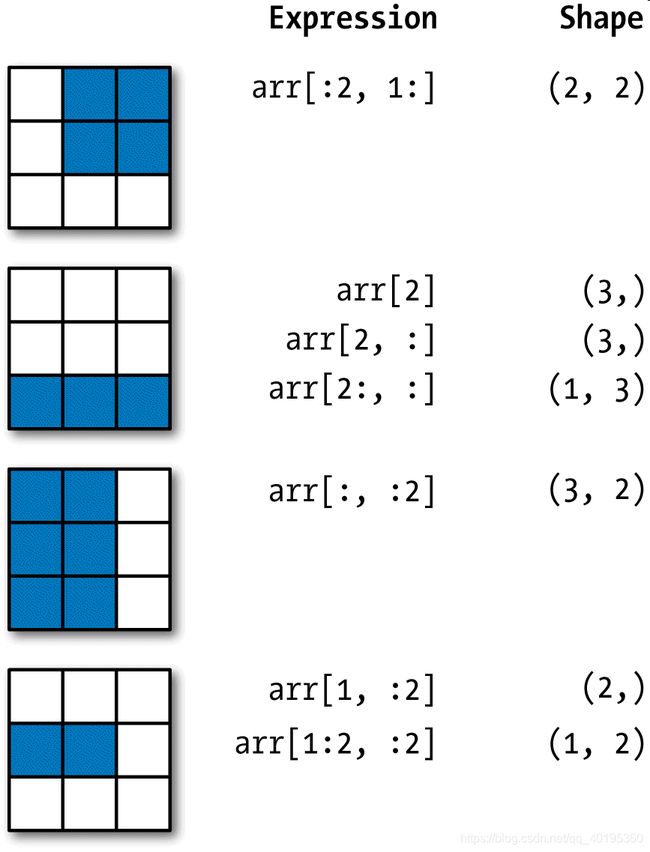
布尔索引
当结果对象是布尔运算(例如比较运算符)的结果时,将使用此类型的高级索引。
示例1:
array5 > 2
输出:
array([[False, False, True],
[ True, True, True],
[ True, True, True]])
输入:
array5[array5>2]
输出:
array([3, 4, 5, 6, 7, 8, 9])
通过布尔型数组设置值是一种经常用到的手段。以下示例使用了~(取补运算符)来过滤NaN。
a = np.array([np.nan, 1,2,np.nan,3,4,5])
a[~np.isnan(a)]
输出:
array([1., 2., 3., 4., 5.])
注意:Python关键字and和or在布尔型数组中无效。要使用&与|。