深度学习—CNN
CNN简介
卷积神经网络 – CNN 最擅长的就是图片的处理。它受到人类视觉神经系统的启发。
CNN 有2大特点:
- 能够有效的将大数据量的图片降维成小数据量
- 能够有效的保留图片特征,符合图片处理的原则
目前 CNN 已经得到了广泛的应用,比如:人脸识别、自动驾驶、美图秀秀、安防等很多领域。
在 CNN 出现之前,图像对于人工智能来说是一个难题,有2个原因:
- 图像需要处理的数据量太大,导致成本很高,效率很低
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
需要处理的数据量太大
图像是由像素构成的,每个像素又是由颜色构成的。
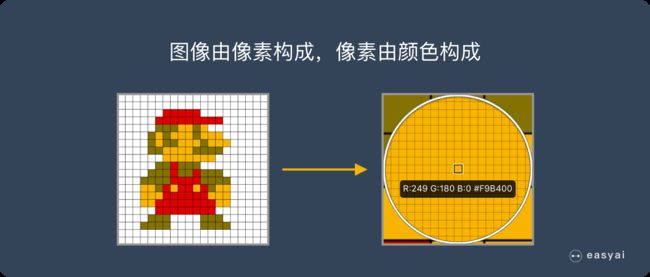
现在随随便便一张图片都是 1000×1000 像素以上的, 每个像素都有RGB 3个参数来表示颜色信息。
假如我们处理一张 1000×1000 像素的图片,我们就需要处理3百万个参数!
这么大量的数据处理起来是非常消耗资源的,而且这只是一张不算太大的图片!
卷积神经网络 – CNN 解决的第一个问题就是“将复杂问题简化”,把大量参数降维成少量参数,再做处理。
更重要的是:我们在大部分场景下,降维并不会影响结果。比如1000像素的图片缩小成200像素,并不影响肉眼认出来图片中是一只猫还是一只狗,机器也是如此。
保留图像特征
图片数字化的传统方式我们简化一下,就类似下图的过程:
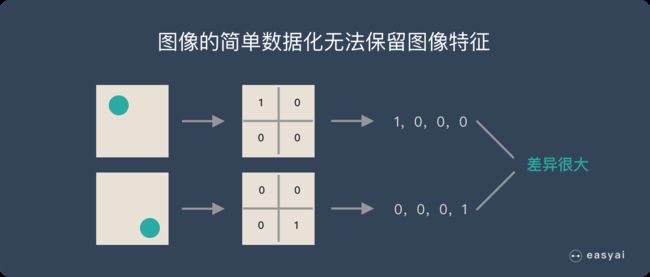
假如有圆形是1,没有圆形是0,那么圆形的位置不同就会产生完全不同的数据表达。但是从视觉的角度来看,图像的内容(本质)并没有发生变化,只是位置发生了变化。
所以当我们移动图像中的物体,用传统的方式的得出来的参数会差异很大!这是不符合图像处理的要求的。
而 CNN 解决了这个问题,他用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
CNN基本原理
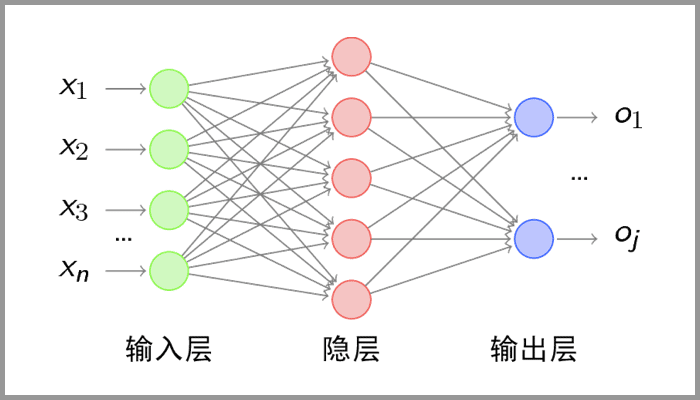
层级结构

上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车 那是什么车
最左边是
数据输入层:对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
中间
CONV:卷积计算层,线性乘积 求和。负责提取图像中的局部特征;
RELU:激励层,ReLU是激活函数的一种。
POOL:池化层,简言之,即取区域平均或最大。用来大幅降低参数量级(降维);
最右边是
FC:全连接层类似传统神经网络的部分,用来输出想要的结果。
卷积层
卷积核(Kernel)
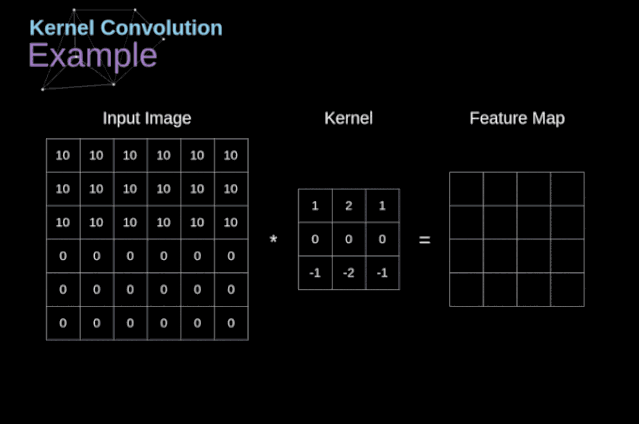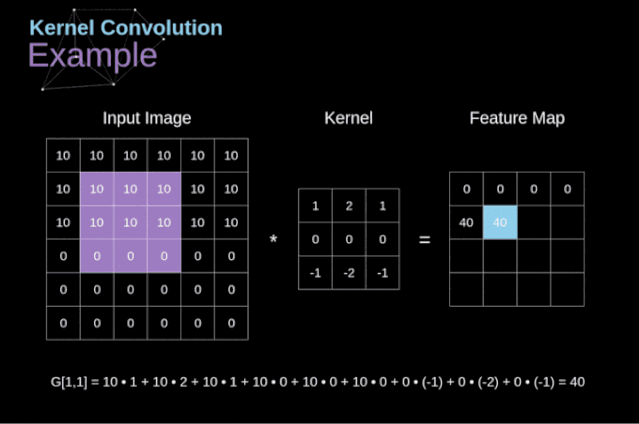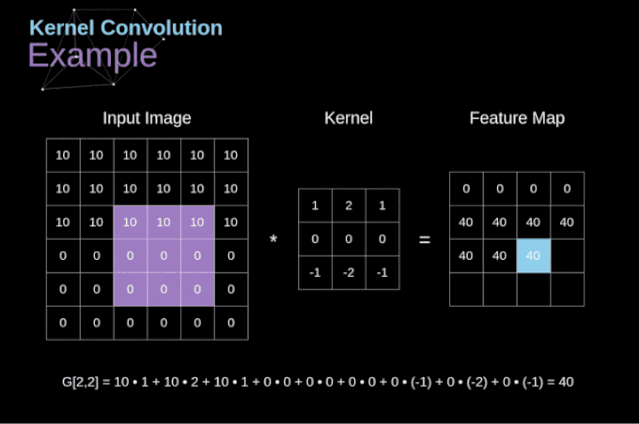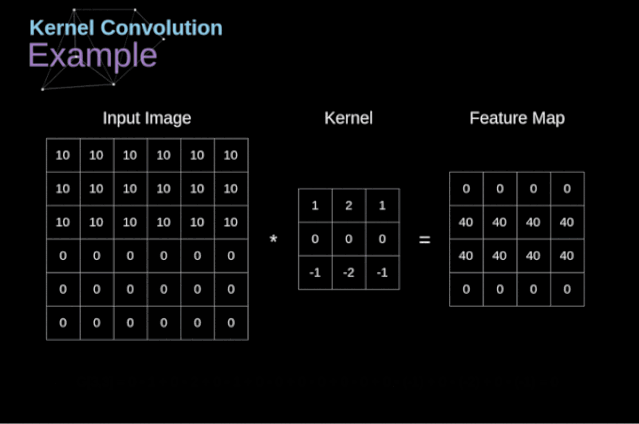
- 卷积运算是指以一定间隔滑动卷积核的窗口,将各个位置上卷积核的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算),将这个结果保存到输出的对应位置。卷积运算如下所示:
对于一张图像,卷积核从图像最始端,从左往右、从上往下,以一个像素或指定个像素的间距依次滑过图像的每一个区域。
填充/填白(Padding)
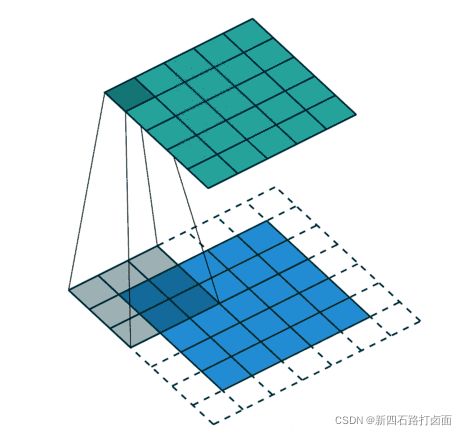
- 在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),使用填充的目的是调整输出的尺寸,使输出维度和输入维度一致;
如果不调整尺寸,经过很多层卷积之后,输出尺寸会变的很小。所以,为了减少卷积操作导致的,边缘信息丢失,我们就需要进行填充(Padding)。
步幅/步长(Stride)
- 即卷积核每次滑动几个像素。前面我们默认卷积核每次滑动一个像素,其实也可以每次滑动2个像素。其中,每次滑动的像素数称为“步长”,步长为2的卷积核计算过程如下;
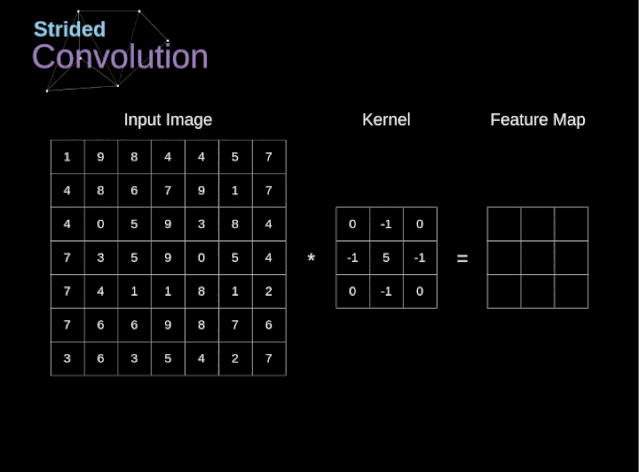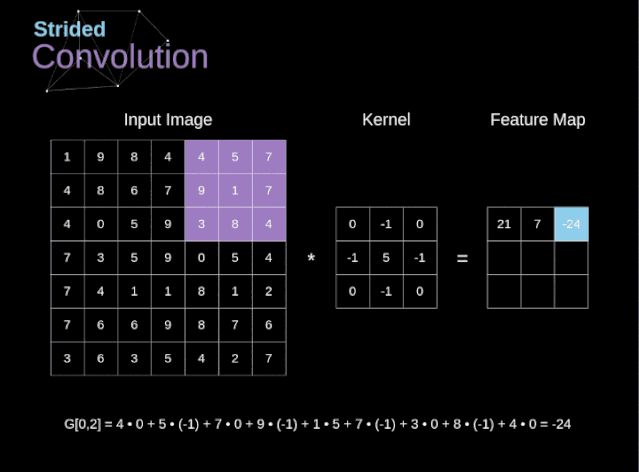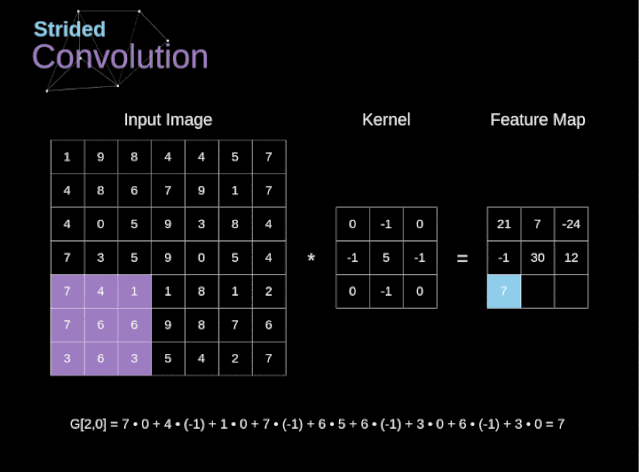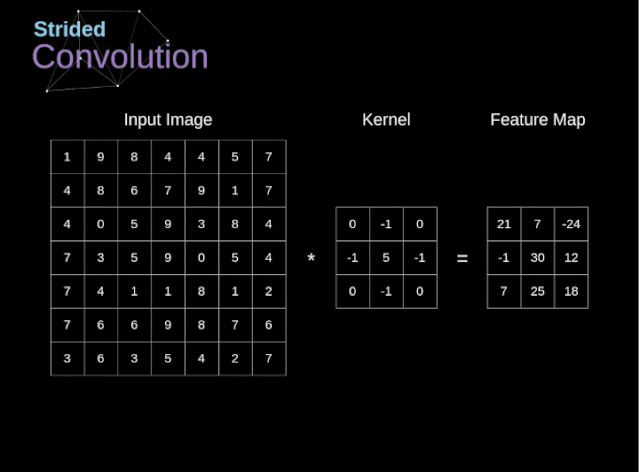
- 若希望输出尺寸比输入尺寸小很多,可以采取增大步幅的措施。但是不能频繁使用步长为2,因为如果输出尺寸变得过小的话,即使卷积核参数优化的再好,也会必可避免地丢失大量信息;

滤波器(Filter)
- 卷积核(算子)是二维的权重矩阵;而滤波器(Filter)是多个卷积核堆叠而成的三维矩阵。
在只有一个通道(二维)的情况下,“卷积核”就相当于“filter”,这两个概念是可以互换的
- 上面的卷积过程,没有考虑彩色图片有RGB三维通道(Channel),如果考虑RGB通道,那么每个通道都需要一个卷积核,只不过计算的时候,卷积核的每个通道在对应通道滑动,三个通道的计算结果相加得到输出。即:每个滤波器有且只有一个输出通道。
当滤波器中的各个卷积核在输入数据上滑动时,它们会输出不同的处理结果,其中一些卷积核的权重可能更高,而它相应通道的数据也会被更加重视,滤波器会更关注这个通道的特征差异。
偏置
最后,偏置项和滤波器一起作用产生最终的输出通道。
多个filter也是一样的工作原理:如果存在多个filter,这时我们可以把这些最终的单通道输出组合成一个总输出,它的通道数就等于filter数。这个总输出经过非线性处理后,继续被作为输入馈送进下一个卷积层,然后重复上述过程。
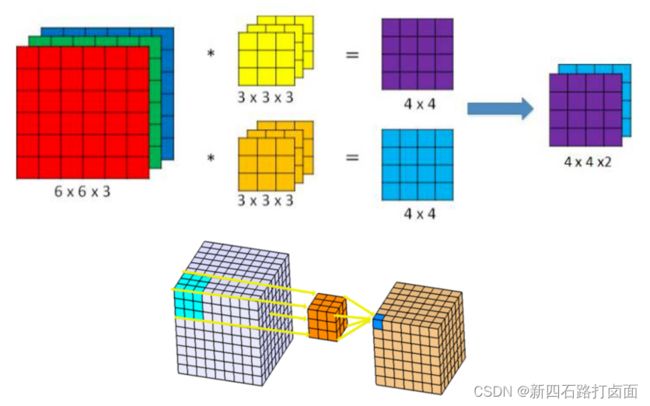
因此,这部分一共4个超参数:滤波器数量K,滤波器大小F,步长S,零填充大小P。
激励层
激励层主要对卷积层的输出进行一个非线性映射,因为卷积层的计算还是一种线性计算。使用的激励函数一般为ReLu函数:
卷积层和激励层通常合并在一起称为“卷积层”。
池化层(Pooling layer)
池化(Pooling),有的地方也称汇聚,实际是一个下采样(Down-sample)过程,用来缩小高、长方向的尺寸,减小模型规模,提高运算速度,同时提高所提取特征的鲁棒性。简单来说,就是为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。
池化层通常出现在卷积层之后,二者相互交替出现,并且每个卷积层都与一个池化层一一对应。
- 常用的池化函数有:平均池化(Average Pooling / Mean Pooling)、最大池化(Max Pooling)、最小池化(Min Pooling)和随机池化(Stochastic Pooling)等,其中3种池化方式展示如下。
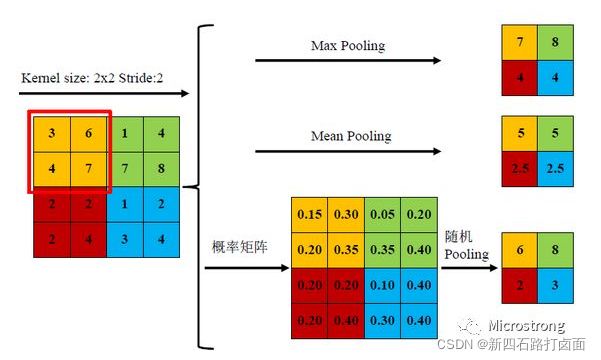
三种池化方式各有优缺点,均值池化是对所有特征点求平均值,而最大值池化是对特征点的求最大值。而随机池化则介于两者之间,通过对像素点按数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与均值采样近似,在局部意义上,则服从最大值采样的准则。
根据Boureau理论2可以得出结论,在进行特征提取的过程中,均值池化可以减少邻域大小受限造成的估计值方差,但更多保留的是图像背景信息;而最大值池化能减少卷积层参数误差造成估计均值误差的偏移,能更多的保留纹理信息。随机池化虽然可以保留均值池化的信息,但是随机概率值确是人为添加的,随机概率的设置对结果影响较大,不可估计。
池化操作也有一个类似卷积核一样东西在特征图上移动,书中叫它池化窗口,所以这个池化窗口也有大小,移动的时候有步长,池化前也有填充操作。因此,池化操作也有核大小f、步长s和填充p 参数,参数意义和卷积相同。Max池化的具体操作如下(池化窗口为2 × 2 ,无填充,步长为2):
一般来说,池化的窗口大小会和步长设定相同的值。
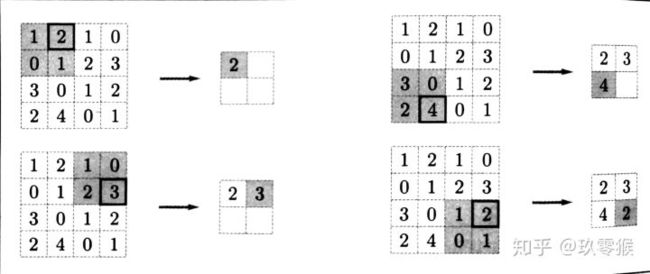
池化层有三个特征:
- 没有要学习的参数,这和池化层不同。池化只是从目标区域中取最大值或者平均值,所以没有必要有学习的参数。
- 通道数不发生改变,即不改变Feature Map的数量。
- 它是利用图像局部相关性的原理,对图像进行子抽样,这样对微小的位置变化具有鲁棒性——输入数据发生微小偏差时,池化仍会返回相同的结果。
(9条消息) resnet详解_「已注销」的博客-CSDN博客_resnet
全连接层——输出结果
这个部分就是最后一步了,经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。
经过卷积层和池化层降维过的数据,全连接层才能”跑得动”,不然数据量太大,计算成本高,效率低下。
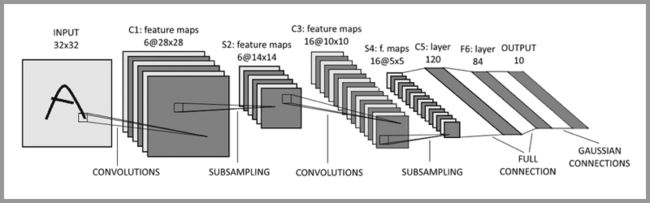
典型的 CNN 并非只是上面提到的3层结构,而是多层结构
例如 LeNet-5 的结构就如下图所示:
卷积层 – 池化层- 卷积层 – 池化层 – 卷积层 – 全连接层
ResNet残差神经网络
11-残差网络Resnet_哔哩哔哩_bilibili
(9条消息) resnet详解_「已注销」的博客-CSDN博客_resnet
AI Studio使用CNN实现猫狗分类
CNN实现猫狗分类 - 飞桨AI Studio (baidu.com)
CNN网络
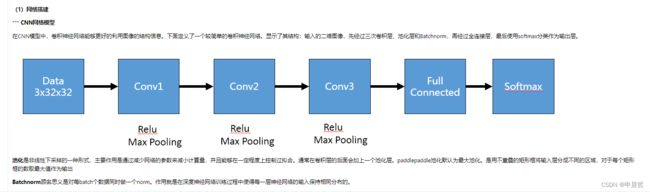 代码
代码
def convolutional_neural_network(img):
# 第一个卷积-池化层
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img, # 输入图像
filter_size=5, # 滤波器的大小
num_filters=20, # filter 的数量。它与输出的通道相同
pool_size=2, # 池化核大小2*2
pool_stride=2, # 池化步长
act="relu") # 激活类型
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
# 第二个卷积-池化层
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
conv_pool_2 = fluid.layers.batch_norm(conv_pool_2)
# 第三个卷积-池化层
conv_pool_3 = fluid.nets.simple_img_conv_pool(
input=conv_pool_2,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
# 以softmax为激活函数的全连接输出层,10类数据输出10个数字
prediction = fluid.layers.fc(input=conv_pool_3, size=10, act='softmax')
return prediction