BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert历史意义:
1、获取了left-to-right和right-to-left的上下文信息
2、nlp领域正式开始pretraining+finetuning的模型训练方式
nlp领域(各个下游任务都有自身的模型) -------2018(Bert) --------nlp领域(各个下游任务统一使用Bert模型)
Bert衍生模型
| 衍生模型 | 模型特点 |
| RoBERTa | 模型更大,参数量更多静态mask变成动态mask |
| ALBERT | 参数量减少,跨层的参数共享 |
| BERT-WWM | 全词mask,中文 |
| ERINE | mask实体,中文 |
| SpanBERT | 随机选取span进行mask |
| TinyBERT | 对transformer结构进行蒸馏 |
| Sentence-BERT | 孪生网络 |
| K-BERT | 知识图谱 |
ELmo、GPT、Bert比较
| 模型 | 模型采用结构 | 预训练形式 | 优点 | 缺点 | 在GLue上表现 |
| BERT | Transformer Encoder部分(无sequence mask) | fine-tuning | 在各项下游任务中表现最好采用mlm的实现形式完成真正意义上的双向增加了句子级别预测的任务 | 在文本生成任务上表现不好 | 最好 |
| ELMO | Bilstm + LM | feature-based | 动态的词向量表征 | 双向只是单纯的concat两个lstm,并没有真正的双向 | 最差 |
| GPT | Transformer Decoder部分(含有sequence mask,去掉中间的encoder-decoder的attention) | fine-tuning | 在文本生成任务上表现出色,同时采用辅助目标函数和lm | 单向的transformer结构,无法利用全局上下文信息 | 较差 |
论文主要结构:
一、Abstract
介绍背景及提出bert模型,在多个数据集上的效果都表现优异
1、提出一种新的语言表征模型bert,不同于其它的语言表征模型,bert可以同时学习到向左和向右的上下文信息
2、预训练好的bert可以直接fine-tuning,只需加相应的输出层,无需太多模型结构的改动
3、bert模型在各项nlp下游任务中都表现的良好
二、Introduction
介绍之前的预训练模型存在单向的问题,因此提出了Bert
三、Related Work
介绍无监督的feature-based和fine-tuning
四、Architecture
Bert网络结构及其内部细节: pre-training和fine-tuning
模型结构:


输入:
1、在第一个句子的开头入【CLS】标价,在末尾加入【SEP】标记
2、将表示句子A或B的embedding添加到每个token上
3、给每个token准备对应的embedding和position embedding
4、句子和句子之间用【SEP】隔开
Bert、GPT、Elmo比较图
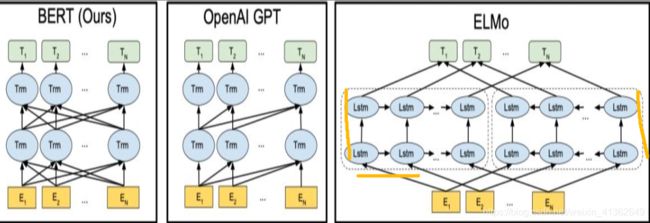
Pre-training fine-tuning


为了使模型学习到句子left-to-right 和right-to-left的全局的信息,采取两种策略:
策略1: Masked LM, 随机的mask一个句子中15%的词,用其上下文做预测 my dog is hairy --> my dog is [mask]
为了保证预训练和微调时的一致性,采取以下措施:
1、80%的机会是采用mask,my dog is hairy ---> my dog is [mask]
2、10% 的机会是随机一个词替代mask my dog is hairy --> my dog is apple
3、10%的机会是保持不变的 my dog is hairy --> my dog is hairy
策略2: Next Sentence Prediction
选择一些句子对A和B,其中50%的数据B是A的下一条句子,50%的数据是从语料库中选取的,这样做是针对句子间的任务,例如SNLI
Fine-tuning BERT

在句子分类任务中,就是在【CLS】对应的token处接相应的线性层,BERT结构的参数是fine-tunied,但是线性层的参数是从头到尾训练的,ner任务中每个token后面都会有对应的输出
模型蒸馏:
1、首先需要训练一个大的模型,这个大模型也称为teacher模型
2、利用teacher模型输出的概率分布训练小模型,小模型称为student模型
3、训练student模型时,包含两种label,soft label对应了teacher模型输出的概率分布,而hard label是原来的one-hot label
4、模型蒸馏训练的小模型会学习到大模型的表现以及泛化能力
KL(p||q) = Ep(log(p/q)) = sumipi(logpi) - sumipilog(qi)
i 代表当前的token,p代表teacher模型的分布,q代表student模型的分布,采用KL散度作为损失函数
五、Experiments
Bert在各个nlp下游任务中的结果对比

Bert在下游任务中的表现完全远超之前的模型
六、Analysis
通过消融分析来验证Bert的pre-training 和model size的有效性
七、Conclusions
论文验证了bert模型确实能在下游任务中良好的效果
主要思想-MLM、NSP、fine-tuning Bert思想
八、代码实现
预训练模型地址: https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz
公开数据集下载地址: http://thuctc.thunlp.org/
一、fine-tuning代码
""" fine-tuning 代码"""
from importlib import import_module
import time
import torch
import numpy as np
import torch.nn as nn
from pytorch_pretrained import BertModel, BertTokenizer
dataset = '.' # 数据集
class Config(object):
""" 配置参数 """
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt'
self.dev_path = dataset + '/data/dev.txt'
self.test_path = dataset + '/data/test.txt'
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.require_imporovement = 1000
self.num_classes = len(self.class_list)
self.num_epochs = 3
self.batch_size = 128
self.pad_size = 32
self.learning_rate = 5e-5
self.bert_path = "/Users/apple/work/matrial/bert/Bert-Chinese-Text-Classification-Pytorch/bert_pretrain/"
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path + 'vocab.txt')
self.hidden_size = 768
class Model(nn.Module):
def __init__(self,config):
super(Model,self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0]
mask = x[2]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
config = Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True
start_time = time.time()
print("Loading data .... ")
from tqdm import tqdm
import time
from datetime import timedelta
PAD,CLS = '[PAD]','[CLS]'
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path,'r',encoding='utf-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content,label = lin.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0]*(pad_size - len(token_ids))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train,dev,test
def build_iterator(dataset, config):
iter_ = DatasetIterater(dataset, config.batch_size, config.device)
return iter_
def get_time_dif(start_time):
end_time = time.time()
time_diff = end_time - start_time
return timedelta(seconds=int(round(time_diff)))
class DatasetIterater(object):
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data,config)
test_iter = build_iterator(test_data,config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from pytorch_pretrained.optimization import BertAdam
# 权重初始化,默认xavier
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if len(w.size()) < 2:
continue
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
else:
pass
def train(config, model, train_iter, dev_iter, test_iter):
start_time = time.time()
model.train()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]
# optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
optimizer = BertAdam(optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)
model = Model(config).to(config.device)
train(config, model, train_iter, dev_iter, test_iter)
二、Pre-training代码
""" Pre-training代码 """
from torch.utils.data import DataLoader
import torch.nn as nn
import pickle
import tqdm
from collections import Counter
class Args(object):
def __init__(self):
self.train_dataset='data/corpus.small'
self.test_dataset='data/corpus.small'
self.vocab_path='data/corpus.small.vocab'
self.output_path='data/corpus.small.vocab'
self.hidden=256
self.layers=8
self.attn_heads=8
self.seq_len=20
self.batch_size=64
self.epochs=10
self.num_workers=5
self.with_cuda=True
self.log_freq=10
self.corpus_lines=""
self.lr=1e-3
self.adam_weight_decay=0.01
self.adam_beta1=0.9
self.adam_beta2=0.999
args=Args()
class TorchVocab(object):
def __init__(self, counter, max_size=None, min_freq=1, specials=['', ''],
vectors=None, unk_init=None, vectors_cache=None):
self.freqs = counter
counter = counter.copy()
min_freq = max(min_freq, 1)
self.itos = list(specials)
# frequencies of special tokens are not counted when building vocabulary
# in frequency order
for tok in specials:
del counter[tok]
max_size = None if max_size is None else max_size + len(self.itos)
# sort by frequency, then alphabetically
words_and_frequencies = sorted(counter.items(), key=lambda tup: tup[0])
words_and_frequencies.sort(key=lambda tup: tup[1], reverse=True)
for word, freq in words_and_frequencies:
if freq < min_freq or len(self.itos) == max_size:
break
self.itos.append(word)
# stoi is simply a reverse dict for itos
self.stoi = {tok: i for i, tok in enumerate(self.itos)}
self.vectors = None
if vectors is not None:
self.load_vectors(vectors, unk_init=unk_init, cache=vectors_cache)
else:
assert unk_init is None and vectors_cache is None
def __eq__(self, other):
if self.freqs != other.freqs:
return False
if self.stoi != other.stoi:
return False
if self.itos != other.itos:
return False
if self.vectors != other.vectors:
return False
return True
def __len__(self):
return len(self.itos)
def vocab_rerank(self):
self.stoi = {word: i for i, word in enumerate(self.itos)}
def extend(self, v, sort=False):
words = sorted(v.itos) if sort else v.itos
for w in words:
if w not in self.stoi:
self.itos.append(w)
self.stoi[w] = len(self.itos) - 1
class Vocab(TorchVocab):
def __init__(self, counter, max_size=None, min_freq=1):
self.pad_index = 0
self.unk_index = 1
self.eos_index = 2
self.sos_index = 3
self.mask_index = 4
super().__init__(counter, specials=["", "", "", "", ""],
max_size=max_size, min_freq=min_freq)
def to_seq(self, sentece, seq_len, with_eos=False, with_sos=False) -> list:
pass
def from_seq(self, seq, join=False, with_pad=False):
pass
@staticmethod
def load_vocab(vocab_path: str) -> 'Vocab':
with open(vocab_path, "rb") as f:
return pickle.load(f)
def save_vocab(self, vocab_path):
with open(vocab_path, "wb") as f:
pickle.dump(self, f)
class WordVocab(Vocab):
def __init__(self, texts, max_size=None, min_freq=1):
print("Building Vocab")
counter = Counter()
for line in tqdm.tqdm(texts):
if isinstance(line, list):
words = line
else:
words = line.replace("\n", "").replace("\t", "").split()
for word in words:
counter[word] += 1
super().__init__(counter, max_size=max_size, min_freq=min_freq)
def to_seq(self, sentence, seq_len=None, with_eos=False, with_sos=False, with_len=False):
if isinstance(sentence, str):
sentence = sentence.split()
seq = [self.stoi.get(word, self.unk_index) for word in sentence]
if with_eos:
seq += [self.eos_index] # this would be index 1
if with_sos:
seq = [self.sos_index] + seq
origin_seq_len = len(seq)
if seq_len is None:
pass
elif len(seq) <= seq_len:
seq += [self.pad_index for _ in range(seq_len - len(seq))]
else:
seq = seq[:seq_len]
return (seq, origin_seq_len) if with_len else seq
def from_seq(self, seq, join=False, with_pad=False):
words = [self.itos[idx]
if idx < len(self.itos)
else "<%d>" % idx
for idx in seq
if not with_pad or idx != self.pad_index]
return " ".join(words) if join else words
@staticmethod
def load_vocab(vocab_path: str) -> 'WordVocab':
with open(vocab_path, "rb") as f:
return pickle.load(f)
"""构建词典 """
corpus_path=args.train_dataset
with open(corpus_path, "r") as f:
vocab = WordVocab(f, max_size=None, min_freq=1)
print("VOCAB SIZE:", len(vocab))
vocab.save_vocab(args.output_path)
""" 加载词典 """
vocab=WordVocab.load_vocab(args.vocab_path)
from torch.utils.data import Dataset
import tqdm
import torch
import random
class BERTDataset(Dataset):
def __init__(self, corpus_path, vocab, seq_len, encoding="utf-8", corpus_lines=None):
self.vocab = vocab
self.seq_len = seq_len
with open(corpus_path, "r", encoding=encoding) as f:
self.datas = [line[:-1].split("\t")
for line in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines)]
def __len__(self):
return len(self.datas)
def __getitem__(self, item):
t1, (t2, is_next_label) = self.datas[item][0], self.random_sent(item)
t1_random, t1_label = self.random_word(t1)
t2_random, t2_label = self.random_word(t2)
# [CLS] tag = SOS tag, [SEP] tag = EOS tag
t1 = [self.vocab.sos_index] + t1_random + [self.vocab.eos_index]
t2 = t2_random + [self.vocab.eos_index]
t1_label = [self.vocab.pad_index] + t1_label + [self.vocab.pad_index]
t2_label = t2_label + [self.vocab.pad_index]
segment_label = ([1 for _ in range(len(t1))] + [2 for _ in range(len(t2))])[:self.seq_len]
bert_input = (t1 + t2)[:self.seq_len]
bert_label = (t1_label + t2_label)[:self.seq_len]
padding = [self.vocab.pad_index for _ in range(self.seq_len - len(bert_input))]
bert_input.extend(padding), bert_label.extend(padding), segment_label.extend(padding)
output = {"bert_input": bert_input,
"bert_label": bert_label,
"segment_label": segment_label,
"is_next": is_next_label}
return {key: torch.tensor(value) for key, value in output.items()}
def random_word(self, sentence):
tokens = sentence.split()
output_label = []
for i, token in enumerate(tokens):
prob = random.random()
if prob < 0.15:
# prob/=0.15
# 80% randomly change token to make token
if prob < 0.8:
tokens[i] = self.vocab.mask_index
# 10% randomly change token to random token
elif prob < 0.9:
tokens[i] = random.randrange(len(self.vocab))
# 10% randomly change token to current token
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(self.vocab.stoi.get(token, self.vocab.unk_index))
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(0)
return tokens, output_label
def random_sent(self, index):
# output_text, label(isNotNext:0, isNext:1)
if random.random() > 0.5:
return self.datas[index][1], 1
else:
return self.datas[random.randrange(len(self.datas))][1], 0
print("Loading Train Dataset", args.train_dataset)
train_dataset = BERTDataset(args.train_dataset, vocab, seq_len=args.seq_len, corpus_lines=args.corpus_lines)
print("Loading Test Dataset", args.test_dataset)
test_dataset = BERTDataset(args.test_dataset, vocab,
seq_len=args.seq_len) if args.test_dataset is not None else None
print("Creating Dataloader")
train_data_loader = DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.num_workers)
test_data_loader = DataLoader(test_dataset, batch_size=args.batch_size, num_workers=args.num_workers) \
if test_dataset is not None else None
""" Bert """
import torch.nn.functional as F
class BERT(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(self, vocab_size, hidden=768, n_layers=12, attn_heads=12, dropout=0.1):
"""
:param vocab_size: vocab_size of total words
:param hidden: BERT model hidden size
:param n_layers: numbers of Transformer blocks(layers)
:param attn_heads: number of attention heads
:param dropout: dropout rate
"""
super().__init__()
self.hidden = hidden
self.n_layers = n_layers
self.attn_heads = attn_heads
# paper noted they used 4*hidden_size for ff_network_hidden_size
self.feed_forward_hidden = hidden * 4
# embedding for BERT, sum of positional, segment, token embeddings
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden)
# multi-layers transformer blocks, deep network
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden, attn_heads, hidden * 4, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info):
# attention masking for padded token
# torch.ByteTensor([batch_size, 1, seq_len, seq_len)
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
# embedding the indexed sequence to sequence of vectors
x = self.embedding(x, segment_info)
# running over multiple transformer blocks
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return x
""" Bert Embedding """
class BERTEmbedding(nn.Module):
"""
BERT Embedding which is consisted with under features
1. TokenEmbedding : normal embedding matrix
2. PositionalEmbedding : adding positional information using sin, cos
2. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2)
sum of all these features are output of BERTEmbedding
"""
def __init__(self, vocab_size, embed_size, dropout=0.1):
"""
:param vocab_size: total vocab size
:param embed_size: embedding size of token embedding
:param dropout: dropout rate
"""
super().__init__()
self.token = TokenEmbedding(vocab_size=vocab_size, embed_size=embed_size)
self.position = PositionalEmbedding(d_model=self.token.embedding_dim)
self.segment = SegmentEmbedding(embed_size=self.token.embedding_dim)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
def forward(self, sequence, segment_label):
x = self.token(sequence) + self.position(sequence) + self.segment(segment_label)
return self.dropout(x)
class TokenEmbedding(nn.Embedding):
def __init__(self, vocab_size, embed_size=512):
super().__init__(vocab_size, embed_size, padding_idx=0)
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)).float().exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class SegmentEmbedding(nn.Embedding):
def __init__(self, embed_size=512):
super().__init__(3, embed_size, padding_idx=0)
"""TransformerBlock """
class TransformerBlock(nn.Module):
"""
Bidirectional Encoder = Transformer (self-attention)
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
"""
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
"""
:param hidden: hidden size of transformer
:param attn_heads: head sizes of multi-head attention
:param feed_forward_hidden: feed_forward_hidden, usually 4*hidden_size
:param dropout: dropout rate
"""
super().__init__()
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
class MultiHeadedAttention(nn.Module):
"""
Take in model size and number of heads.
"""
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, attn = self.attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
class Attention(nn.Module):
"""
Compute 'Scaled Dot Product Attention
"""
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = GELU()
def forward(self, x):
return self.w_2(self.dropout(self.activation(self.w_1(x))))
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class GELU(nn.Module):
"""
Paper Section 3.4, last paragraph notice that BERT used the GELU instead of RELU
"""
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
"""Build Bert"""
import math
print("Building BERT model")
bert = BERT(len(vocab), hidden=args.hidden, n_layers=args.layers, attn_heads=args.attn_heads)
""" BertTrainer"""
from torch.optim import Adam
from torch.utils.data import DataLoader
import tqdm
class BERTTrainer:
"""
BERTTrainer make the pretrained BERT model with two LM training method.
1. Masked Language Model : 3.3.1 Task #1: Masked LM
2. Next Sentence prediction : 3.3.2 Task #2: Next Sentence Prediction
please check the details on README.md with simple example.
"""
def __init__(self, bert: BERT, vocab_size: int,
train_dataloader: DataLoader, test_dataloader: DataLoader = None,
lr: float = 1e-4, betas=(0.9, 0.999), weight_decay: float = 0.01,
with_cuda: bool = True, log_freq: int = 10):
"""
:param bert: BERT model which you want to train
:param vocab_size: total word vocab size
:param train_dataloader: train dataset data loader
:param test_dataloader: test dataset data loader [can be None]
:param lr: learning rate of optimizer
:param betas: Adam optimizer betas
:param weight_decay: Adam optimizer weight decay param
:param with_cuda: traning with cuda
:param log_freq: logging frequency of the batch iteration
"""
# Setup cuda device for BERT training, argument -c, --cuda should be true
cuda_condition = torch.cuda.is_available() and with_cuda
self.device = torch.device("cuda:0" if cuda_condition else "cpu")
# This BERT model will be saved every epoch
self.bert = bert
# Initialize the BERT Language Model, with BERT model
self.model = BERTLM(bert, vocab_size).to(self.device)
# Distributed GPU training if CUDA can detect more than 1 GPU
if torch.cuda.device_count() > 1:
print("Using %d GPUS for BERT" % torch.cuda.device_count())
self.model = nn.DataParallel(self.model)
# Setting the train and test data loader
self.train_data = train_dataloader
self.test_data = test_dataloader
# Setting the Adam optimizer with hyper-param
self.optim = Adam(self.model.parameters(), lr=lr, betas=betas, weight_decay=weight_decay)
# Using Negative Log Likelihood Loss function for predicting the masked_token
self.criterion = nn.NLLLoss(ignore_index=0)
self.log_freq = log_freq
print("Total Parameters:", sum([p.nelement() for p in self.model.parameters()]))
def train(self, epoch):
self.iteration(epoch, self.train_data)
def test(self, epoch):
self.iteration(epoch, self.test_data, train=False)
def iteration(self, epoch, data_loader, train=True):
"""
loop over the data_loader for training or testing
if on train status, backward operation is activated
and also auto save the model every peoch
:param epoch: current epoch index
:param data_loader: torch.utils.data.DataLoader for iteration
:param train: boolean value of is train or test
:return: None
"""
str_code = "train" if train else "test"
# Setting the tqdm progress bar
data_iter = tqdm.tqdm(enumerate(data_loader),
desc="EP_%s:%d" % (str_code, epoch),
total=len(data_loader),
bar_format="{l_bar}{r_bar}")
avg_loss = 0.0
total_correct = 0
total_element = 0
for i, data in data_iter:
# 0. batch_data will be sent into the device(GPU or cpu)
data = {key: value.to(self.device) for key, value in data.items()}
# 1. forward the next_sentence_prediction and masked_lm model
next_sent_output, mask_lm_output = self.model.forward(data["bert_input"], data["segment_label"])
# 2-1. NLL(negative log likelihood) loss of is_next classification result
next_loss = self.criterion(next_sent_output, data["is_next"])
# 2-2. NLLLoss of predicting masked token word
mask_loss = self.criterion(mask_lm_output.transpose(1, 2), data["bert_label"])
# 2-3. Adding next_loss and mask_loss : 3.4 Pre-training Procedure
loss = next_loss + mask_loss
# 3. backward and optimization only in train
if train:
self.optim.zero_grad()
loss.backward()
self.optim.step()
# next sentence prediction accuracy
correct = next_sent_output.argmax(dim=-1).eq(data["is_next"]).sum().item()
avg_loss += loss.item()
total_correct += correct
total_element += data["is_next"].nelement()
post_fix = {
"epoch": epoch,
"iter": i,
"avg_loss": avg_loss / (i + 1),
"avg_acc": total_correct / total_element * 100,
"loss": loss.item()
}
if i % self.log_freq == 0:
data_iter.write(str(post_fix))
print("EP%d_%s, avg_loss=" % (epoch, str_code), avg_loss / len(data_iter), "total_acc=",
total_correct * 100.0 / total_element)
def save(self, epoch, file_path="output/bert_trained.model"):
"""
Saving the current BERT model on file_path
:param epoch: current epoch number
:param file_path: model output path which gonna be file_path+"ep%d" % epoch
:return: final_output_path
"""
output_path = file_path + ".ep%d" % epoch
torch.save(self.bert.cpu(), output_path)
self.bert.to(self.device)
print("EP:%d Model Saved on:" % epoch, output_path)
return output_path
""" BERTLM """
class BERTLM(nn.Module):
"""
BERT Language Model
Next Sentence Prediction Model + Masked Language Model
"""
def __init__(self, bert: BERT, vocab_size):
"""
:param bert: BERT model which should be trained
:param vocab_size: total vocab size for masked_lm
"""
super().__init__()
self.bert = bert
self.next_sentence = NextSentencePrediction(self.bert.hidden)
self.mask_lm = MaskedLanguageModel(self.bert.hidden, vocab_size)
def forward(self, x, segment_label):
x = self.bert(x, segment_label)
return self.next_sentence(x), self.mask_lm(x)
class NextSentencePrediction(nn.Module):
"""
2-class classification model : is_next, is_not_next
"""
def __init__(self, hidden):
"""
:param hidden: BERT model output size
"""
super().__init__()
self.linear = nn.Linear(hidden, 2)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x[:, 0]))
class MaskedLanguageModel(nn.Module):
"""
predicting origin token from masked input sequence
n-class classification problem, n-class = vocab_size
"""
def __init__(self, hidden, vocab_size):
"""
:param hidden: output size of BERT model
:param vocab_size: total vocab size
"""
super().__init__()
self.linear = nn.Linear(hidden, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x):
return self.softmax(self.linear(x))
"""Start Training """
print("Creating BERT Trainer")
trainer = BERTTrainer(bert, len(vocab), train_dataloader=train_data_loader, test_dataloader=test_data_loader,
lr=args.lr, betas=(args.adam_beta1, args.adam_beta2), weight_decay=args.adam_weight_decay,
with_cuda=args.with_cuda, log_freq=args.log_freq)
print("Training Start")
for epoch in range(args.epochs):
trainer.train(epoch)
trainer.save(epoch, args.output_path)
if test_data_loader is not None:
trainer.test(epoch)
参考代码:https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
模型结构图片:参考李宏毅视频ppt