论文阅读(3):Image-Based 3D Object Reconstruction:State-of-the-Art and Trends in the Deep Learning Era
论文标题:Image-Based 3D Object Reconstruction:State-of-the-Art and Trends in the Deep Learning Era
论文类型:综述
作者:Xian-Feng Han , Hamid Laga , and Mohammed Bennamoun , Senior Member, IEEE
发表期刊: IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
发表时间:2021
阅读日期:2022.3.24
一、目录
1 Introduction
2 Problem Statement and Taxonomy(问题陈述和分类)
3 The Encoding Stage(编码阶段)
3.1 Discrete Latent Spaces(离散的潜在空间)
3.2 Continuous Latent Spaces(连续的潜在空间)
3.3 Hierarchical Latent Spaces(层次结构的潜在空间)
3.4 Disentangled Representation(解纠缠表示)
4 Volumetric Decoding(体积解码)
4.1 Volumetric Representations of 3D Shapes(三维形状的体积表示)
4.2 Low Resolution 3D Volume Reconstruction(低分辨率的三维体素重建)
4.3 High Resolution 3D Volume Reconstruction(高分辨率的三维体素重建)
4.3.1 Space Partitioning(空间分区)
4.3.1.1 Using pre-defined octree structure(用预定义的八叉树结构)
4.3.1.2 Learning the octree structure(学习八叉树结构)
4.3.2 Occupancy NetWorks(占用网络)
4.3.3 Shape Partitioning(形状分区)
4.3.4 Subspace Parameterization(子空间参数化)
4.3.5 Coarese-to-Fine Refinement(由粗到细的细化)
4.4 Deep Marching Cubes(深度行进立方体)
5 3D Surface Decoding(三维表面解码)
5.1 Parameterization-Based 3D Reconsturction(基于参数化的三维重建)
5.2 Deformation-Based 3D Reconstruction(基于变形的三维重建)
5.2.1 Deformation Models(变形模型)
5.2.2 Defining the Template(定义模板)
5.2.3 Network Architectures(网络架构)
5.3 Point-Based Techniques(基于点的技术)
5.3.1 Representations((点云的)表示方式)
5.3.2 Network Architectures(网络架构)
6 Leveraging other cues(利用其他条件)
6.1 Intermediating(中介的)
6.2 Exploiting Spatio-Temporal Correlations(利用时空相关性)
7 Training
7.1 Degree of Supervision
7.1.1 Training with 3D Supervision
7.1.2 Training with 2D Supervision
7.1.2.1 Projection operators(投影运算符)
7.1.2.2 Re-projection loss function(重投影损失函数)
7.1.2.3 Camera parameters and viewpoint estimation(摄像机参数和视点估计)
7.2 Training With Video Supervision(视频监督训练)
7.3 Training Procedure(训练流程)
7.3.1 Joint 2D-3D Embedding (节点2D-3D嵌入 7.3.2 Adversarial Training (对抗训练)
7.3.3 Joint Training With Other Tasks(与其他任务进行联合训练)
8 Applications And Special Cases(应用和特殊案例)
8.1 3D Human Body Reconstruction
8.1.1 Parametric Methods(参数化方法)
8.1.2 Volumetric Methods(体素法)
8.2 3D Face Reconstruction(3D人脸重建)
8.2.1 Network Architectures(网络架构)
8.2.2 Training and Supervision(训练和监督)
8.2.3 Model-Free Approaches(无模型方法)
8.3 3D Scene Parsing(3D场景解析)
9 Datasets(数据集)
10 Performance Comparison(性能比较)
10.1 accuracy Metrics and Performance Criteria(准确性指标和性能指标)
10.1.1 Accuracy Metrics、
10.1.2 Performa Criteria
10.2 Comparison and Discussion
11 Future Reserch Directions
12 Summary and Concluding Remarks
1.INCLUTION
列出了文章的主要贡献
1)这是第一篇有关深度学习三维重建的综述
2)总结了149篇2015年以后的文章
3)对深度学习的三维重建进行了全面的回顾分析,包括训练数据、网络架构的选择及其对三维重建结果的影响、训练策略和应用场景。
4)涵盖88种通用的三维物体重建的方法,11种与三维人脸重建相关的方法,以及6种三维人体形状重建方法
5)以表格的形式对这些方法进行比较和总结
2.PROBLEM STATEMENT AND TAXONOMY

以输出、输入等参数为标准,对网络进行了分类:
Output:分为Volumetric、surface-based和Intermediation,即体素、表面和中介。其中Intermediation是把问题分解为顺序步骤,每一步预测一个中间表示。
本文将从Datasets、Loss functions和Training procedures and degree of supervise来分析这些神经网络的性能。
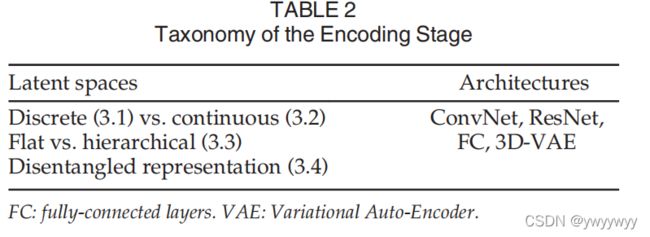
3 The Encoding Stage
基于深度学习的三维重建算法将把输入I编码为一个特征向量x=h(I)∈X,其中X为潜在空间(latent space)。一个好的映射函数h应该具备一下条件:
1)两个输入如果都是近似表达一个三维物体,他们在潜在空间中的映射 x 1 x_1 x1和 x 2 x_2 x2应当比较接近。
2)x的小扰动应当对应于输入的形状的一个小扰动
3)由h引起的潜在表征应当是不变的外部因素,比如相机的姿态
4)一个三维模型及其对应的二维图像应当被映射到空间上的同一点。
前两个条件已经通过使用将输入映射到离散(3.1节)或连续(3.2节潜在空间)的编码器来解决。这些可以是平面的,也可以是分层的(第3.3节)。第三个问题已经通过使用解纠缠表示来解决(第3.4节)。后者已经通过在训练阶段使用tl-体系结构来解决。
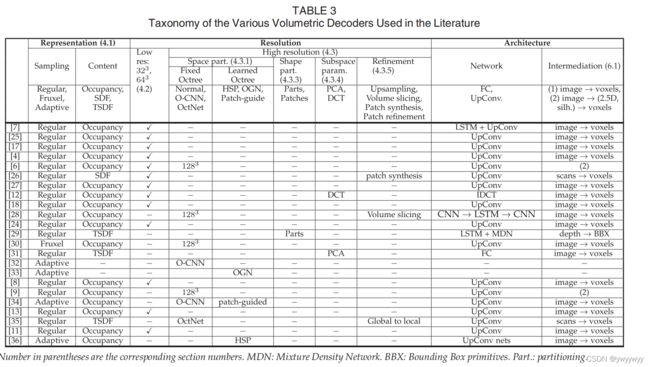
4 VOLUMETRIC DECODING
体素表示法,是把三维模型降采样,用一个个立方体表示三维模型。
本节首先介绍了四种主要的体素表示方式。
1)二进制占用网格
2)概率占用网格
3)有符号距离编码(SDF)
4)已截断的有符号距离函数(TSDF)
随后又把体素重建分为了低分辨率重建和高分辨率重建。
高分辨率重建带来的问题有两个:
1)计算问题,高分辨率的八叉树带来了极大的计算量。
2)个是八叉树依赖于对象,神经网络需要学习如何推断八叉树的结构和内容
为了解决以上问题,演化出了多种方法,高分辨率重建又分为
1)空间分割法
2)占用网格法
3)形状分割法
4)子空间参数法
5)粗-精细化法
为了适应端到端网络,还发明了一种deep marching cubes结构。
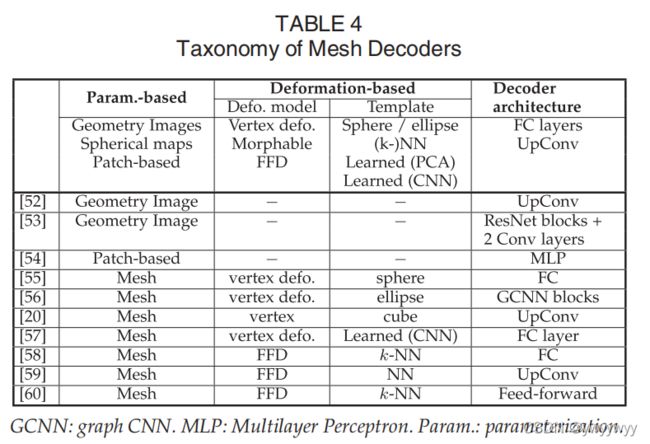
5 三维表面解码
基于体素的表示会耗费大量的计算资源,而且丰富的信息往往存在于三维物体的表面,而基于体素的方法耗费大量资源在内部体素的生成。同时,生成了体素之后的三维模型表面又是无规则的,提高了处理表面的难度。因此,它不容易适应深度学习。
为了解决这个问题产生了许多技术,本文将其分为三大类,如下表
1)基于参数化的
2)基于模板变形的
3)基于点的方法
6 利用其他线索提高三维重建效率的方法
1)中介法
并非直接提取三维形状,而是将问题分解为连续的步骤,估计2.5D信息,如深度图、法线映射和分割掩码。
2)利用时空相关性
一般是基于单幅图像重建时,记忆前面输入的图像,进行3D模型的修正。
7 Training
本节讨论了文献中的各种监督模式和训练流程
早起的方法都依赖于三维监督,但是无论是手工还是传统的三维重建技术都费时费力,因此最新的技术都是利用其他监督信号,如视图一致性来减少资源消耗。
本文首先从监督的程度不同来分类
1)用三维模型来训练
2)用二维图来训练
3)用视频来训练
其次以训练流程来分类
1)Joint 2D-3D Embedding
2) 对抗性训练
3)与其他任务联合训练,提高训练成果的复用性
8 常见应用物体的分类
1)三维人体重建
2)三维人脸重建
3)三维场景解析