推荐系统与深度学习(十七)——DIN模型原理

公众号后台回复“图书“,了解更多号主新书内容
作者:livan
来源:数据python与算法
模型简介
![]()
![]()
随着推荐算法逐渐的发展,大佬们的研究方向主要切分成了两部分:一个是对特征的调整,大家想尽办法挖掘特征中的隐含信息,寻找新的特征而且不断进行组合交叉,例如:FM、FFM系列的模型;另一个是对模型的结构调整,另一群人又想尽办法的寻找用户交易行为的特性,添加或优化各种模型结构,以便快速发现数据信息,例如:AFM、NFM以及我们今天要了解的DIN模型。
通过对用户行为数据的探索,我们发现用户的需求存在两个特性:
Diversity:用户在浏览电商网站的过程中显示出的兴趣是十分多样性的。
Local activation: 由于用户兴趣的多样性,只有部分历史数据会影响到当次推荐的物品是否被点击,而不是所有的历史记录。
这两种特性是密不可分的。
从数据角度分析,我们可以明确,用户的访问序列中,各个行为点的权重不一致,这一特性刚好符合我们前期讲到的Attention机制,因此,阿里的大神基于此创造出了深度兴趣网络DIN。
DIN模型
![]()
![]()
本文我们假设DIN涉及的特征包括:用户特征、用户行为特征、广告特征、上下文特征。
在介绍DIN之前我们先来了解一下DIN的基准模型,即base model,如下图:
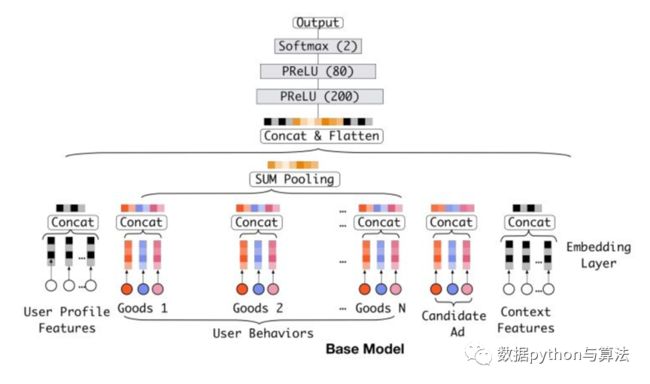
数据流为:
1)这一模型会收集各个特征,通过Embedding过程,将各个特征降维到固定的维度,同时concat成为一个完整的向量。
2)用户行为类的数据会经过sum pooling池化,形成一个融合之后的向量,然后将四部分的特征连接(concat)起来,形成完整的数据向量,喂入到DNN模型中。
其对应的损失函数为:
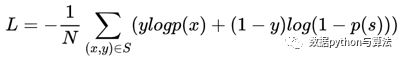
S是训练集数量,x是网络输入,y是标签。
这一模型存在一个问题,即我们上面提到过的两个问题,User Behaviors部分的行为权重未必一致,因此出现了基于Attention的模型结构DIN:
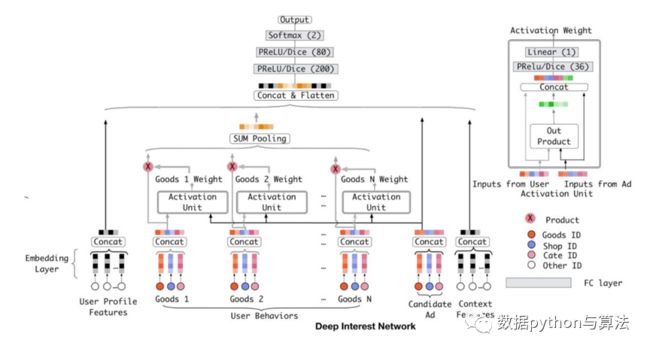
这一模型的核心思路为:对于每一个用户,针对不同的广告有不同的向量表示。
比较上面两个图可以发现,User Behaviors部分的计算添加了Activation Unit部分,我们仔细分析这一部分可以看到:
1)Activation Unit部分融合了用户行为向量Good和广告特性向量Condidate ad,经过一个复杂的网络计算出各个行为点的权重向量Good i Weight。
Good i Weight的计算过程如下图:
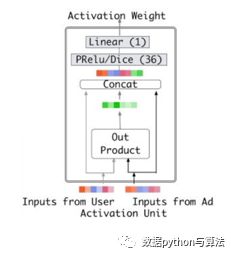
User特征向量与Ad特征向量输入到网络中,经过Out Product形成交互向量,并结合User特征向量与Ad特征向量,concat成一个完整的向量,最终经过DNN部分,输出Weight值。
对应的函数表达为:
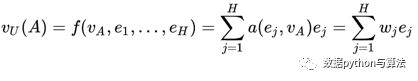
2)Activation Unit部分输出的Weight值与原始的Good向量进行点乘操作,融合成一个带权重的行为向量,经过Sum pooling计算形成统一的行为向量。
3)接下来将四种特征的向量concat成一个长向量,输入到DNN部分,最终计算出output值。
截止到目前,我们将模型的数据流做了梳理,大家有什么新的认知吗?
模型细节
![]()
![]()
我们同时聊一下这一模型的一些细节:
1)Mini-batch Aware Regularization
当不使用正则化时,模型很容易会陷入过拟合,而用传统的l1,l2正则化时,在参数更新时,对每个参数都要进行一轮计算,复杂度大大提高,因此本文提出了一种高效的mini-batch aware正则化方法,只有对每个mini-batch中出现的稀疏特征进行l2正则化
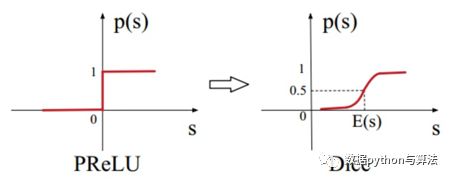
2)Data Adaptive Activation Function
PRelu的突变点在0,但是当数据分布不同时,应该让数据自适应的选择分界点,这里改进了PRelu函数,利用Dice作为激活函数。
3)评价指标GAUC
基于模型的设计,我们重新优化了评价模型,如下图:
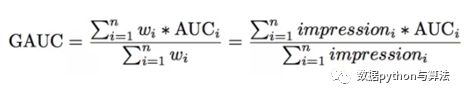
wi是候选广告影响着每个behavior id的权重,也就是Good i Weight
那么,为什么我们要做这样的调整呢?
我们首先要肯定的是,AUC是要分用户看的,我们的模型的预测结果,只要能够保证对每个用户来说,他想要的结果排在前面就好了。
假设有两个用户A和B,每个用户都有10个商品,10个商品中有5个是正样本,我们分别用TA,TB,FA,FB来表示两个用户的正样本和负样本。也就是说,20个商品中有10个是正样本。假设模型预测的结果大小排序依次为TA,FA,TB,FB。如果把两个用户的结果混起来看,AUC并不是很高,因为有5个正样本排在了后面,但是分开看的话,每个用户的正样本都排在了负样本之前,AUC应该是1。显然,分开看更容易体现模型的效果,这样消除了用户本身的差异。
但是上文中所说的差异是在用户点击数即样本数相同的情况下说的。还有一种差异是用户的展示次数或者点击数,如果一个用户有1个正样本,10个负样本,另一个用户有5个正样本,50个负样本,这种差异同样需要消除。那么GAUC的计算,不仅将每个用户的AUC分开计算,同时根据用户的展示数或者点击数来对每个用户的AUC进行加权处理。进一步消除了用户偏差对模型的影响。通过实验证明,GAUC确实是一个更加合理的评价指标。
◆ ◆ ◆ ◆ ◆
麟哥新书已经在京东上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前京东正在举行100-50活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
点击下方小程序即可进入购买页面:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 麟哥拼了!!!亲自出镜推荐自己新书《数据分析师求职面试指南》● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗