阿里妈妈广告商品点击数据分析
阿里妈妈广告商品点击数据分析报告
一、分析背景与目的
数据源:[https://tianchi.aliyun.com/dataset/dataDetail?dataId=56]
阿里妈妈发展势头迅猛,营销仍存在部分盲点;
这是阿里妈妈的一份关于广告曝光次数和点击率的数据,我们希望通过分析,发现数据隐藏的增长点,为运营侧提供策略建议;
评价广告的一个关键指标是广告点击次数,点击数反应该广告对大众的吸引力,只有发生点击行为,才会发生购买;
我们对点击次数下一个公式定义:
点击次数 = 广告的曝光次数*点击率
广告的曝光次数无法干涉,那么在曝光次数一定的情况下,提升点击率是我们要关注的重点。
二、分析思路
用户在阿里平台点击广告进而发生购买行为,因此这里我们从广告、用户两个维度进行分析1、广告维度
- 分析不同广告商品品牌对点击率的影响
- 分析不同广告商品价格对点击率的影响
2、用户维度
- 结合聚类与RFM模型分析技术,分析用户群体特征,制定营销策略
三、分析过程
1 数据清洗
1.1 数据概览

raw_sample 抽取用户ID、广告ID、时间、资源位、是否点击
ad_feature 抽取广告ID、广告商品类目ID、品牌ID
user_profile 抽取用户ID、年龄、性别、购物深度
1.2 特征工程
1.2.1 异常值处理
价格字段存在异常值,采用四分位法进行处理,过程如下:
Q1 25% 分位 : 49
Q3 75% 分位 : 352
上界公式:上界 = Q3 - (Q3 - Q1) * K 其中k = 1.5(经验值)
下界公式:下界 = Q1 - (Q3 - Q1) * K 其中k = 1.5(经验值)
最终结果
上界 = 800
下界 = 0
删除上下界范围之外的记录数
##四分位计算脚本
select SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(price ORDER BY CAST(price AS DECIMAL(12,2)) SEPARATOR ','),',',25/100*count(1)),',',-1) from ad_feature;
1.2.2 衍生字段
衍生价格等级price_level字段
0~100 1级 、100~200 2级 以此类推 共8个级别
2 结合图表分析
2.1 分析不同广告商品品牌对点击率的影响
部分商品曝光次数较少,无分析价值;故选取曝光次数Top7的广告商品进行分析
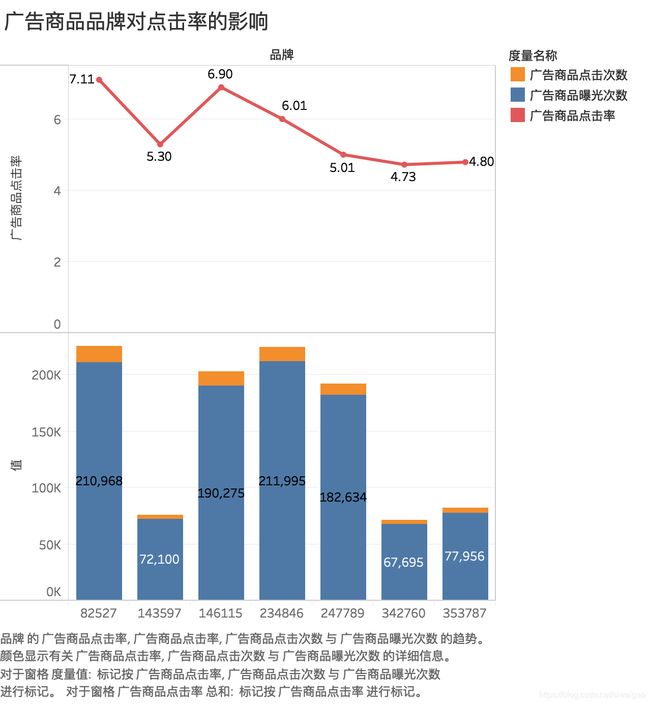
由图可知,品牌342760广告商品曝光次数6万+,但点击率只有4.73%,这里我们重点分析下该品牌
2.1.1 分析品牌342760广告商品效果差的原因
a、分析性别对该品牌点击率的影响
![]()
![]()
-
广告商品点击率不能直接下结论女性点击率高于男性;这里引入卡方检验,分析显著性差异:
观察的数据:
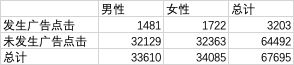
我们得出观察到数据,并且形成表格后,我们需要计算理论的数据,在上面的例子我们发现,我们发现有95.27%的用户不点击商品广告(64492除以67695),4.73%的用户会点击广告商品。 那如果,男性用户33610个人,女性用户34085个人,根据这些比例,我们可以得出的理论值是什么呢?

这里要引出卡方检验的公式:
 结果
结果
卡放值:15.58
自由度:1
置信度:95%
查表可得:因为15.58大于3.341 所以男性和女性广告点击存在显著差异;女性点击率高于男性 -
性别比例:男/女 = 377517/684251 = 1 : 1.81 ,女性用户占整体用户比例的64.44%,女性用户较多;产品曝光比例:男/女 = 33610/34085 = 1:1.01,曝光比例失衡。
总结:整体大盘女性用户数占比高于男性用户,且品牌商品更受女性用户群体喜爱,但女性用户该品牌商品广告投放比例远低于大盘女性用户整体占比,因此我们建议该商品应加大女性用户的广告投放。
b、分析年龄对该品牌商品点击率的影响
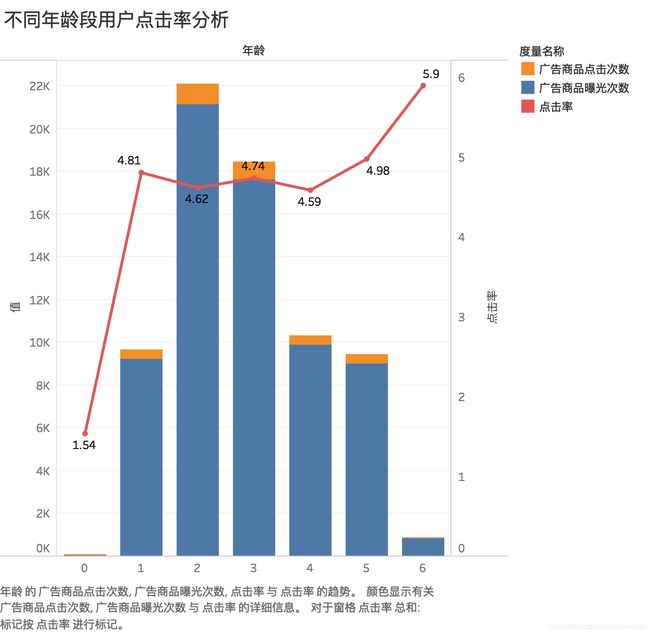
由图可知,该品牌商品主要投放用户群体年龄段为20~40岁,但此年龄段内用户点击率较低;50岁以上用户该品牌商品广告曝光次数较低,但点击率高达5.9% ;结合a,b分析我们推测该商品为50岁以上女性用户消费产品
c.大盘分年龄段用户分布
![]()
由上图可知20~50岁年龄段用户数占整体用户数比例 71.45%,占比相当高;我们分析这部分用户一般为上班族,经济收入稳定,对网购比较熟悉,是企业的核心用户。
结论:
- 由a,b可知,该品牌商品更受50岁以上女性用户青睐,对该部分用户可适当增加品牌商品的曝光次数,以获取这部分用户营收;
- 由c可知,20~50岁用户基数大,且网购消费理念较强,我们鼓励拉动这部分用户消费此类商品,故建议对该类商品增加妈妈、婆婆、父母礼物等字样关键字,引导消费者将此类商品作为礼物购买。
2.2 分析不同广告商品价位对点击率的影响
分析不同价格等级广告商品的点击率,分析哪些点击率高,哪些点击率低,影响因素是什么?
由上图可知,曝光的广告商品价位主要集中在0~200区间范围,且该区间广告点击率最高;分析点击该部分广告商品的用户特征,我们预测这部分用户为价格敏感型用户,且消费意愿强烈,我们做进一步验证,分析如下:
2.2.1 分析0~200价格区间广告商品点击率影响因素
a、0~200价格区间内用户性别分析
统计0~200价格区间内男女广告商品曝光次数、商品点击次数、点击率数值
![]()
统计整体大盘男女用户比例
![]()
该价格区间广告商品曝光次数比例:男性/女性 = 1 : 2.85
大盘整体的性别比例:男性/女性 = 1 :1.81
由上边两图可知,此0~200价格区间内广告商品投放比例,女性用户投放比例远高于男性用户,女性用户点击率高于男性用户。
b、0~200价值区间广告商品点击用户年龄分析

c .大盘分年龄段统计用户数量
![]()
分析上图,0~10岁年龄区间用户量太少无分析价值,40岁以上用户,随着年龄的增加,0~200价位广告商品点击率逐渐上升,曝光量逐渐下降。
总结:
- 由a图表分析可得,0~200价格区间广告商品女性用户广告曝光率远高于男性,女性用户点击率高于男性用户,考虑到这是平台的营销策略,策略效果良好,应继续加大女性用户此类广告商品的投放比例。
- 由b图表分析可得,随用户年龄增加,0~200价格区间广告商品点击率逐渐升高,但曝光次数逐渐下降;结合大盘整体用户数量,50~60岁年龄段用户数占比高于20~30岁年龄段,但曝光次数却小于20~30岁年龄段,建议减少20~30岁年龄段0~200价格区间广告商品投放,增加50~60岁年龄段0~200价格区间广告商品投放。
- 结合a,b图表分析可得,50岁以上女性用户,可适当增加产品折扣力度,降低商品价格,发放商品优惠券等促销行为,促使用户点击转化为购买行为。
2.3 用户分群,针对特定用户群体,制定营销策略
对有相似消费习惯和消费价值的用户进行分群,针对不同的用户群体制定特定的广告投放策略;
这里我们选取用户广告点击率、购物深度、点击商品平均价格三个维度来衡量用户价值标准。
广告点击率——反应用户在平台的活跃程度
购物深度——体现用户在平台上的持续购物深度
点击商品价格均值——体现用户的潜在消费能力
2.3.1 用K-Means算法对用户进行聚类
示例代码如下:
import pandas as pd
import joblib
import numpy as np
#加载数据
#error_bad_lines忽略掉其中错乱行
ad_feature = pd.read_csv('ad_feature.csv') #广告商品信息
raw_sample = pd.read_csv('raw_sample.csv') #广告商品用户点击信息
user_info = pd.read_csv('user_profile.csv')#用户信息
ad_feature.describe()
#price上四分位是352 下四分位是49 由公式上界 = Q3 - (Q3 - Q1) * K 下界 = Q1 - (Q3 - Q1)* K K = 1.5得
#上界 = 806.5 下界 = -405 这里我们定义上界800 下界0
temp_ad_feature = ad_feature[(ad_feature['price']> 0) & (ad_feature['price']< 800)][['adgroup_id','cate_id','brand','price']]
temp_ad_feature['price_level'] = pd.cut(list(temp_ad_feature['price']),8, labels=[1,2,3,4,5,6,7,8])
#temp_ad_feature.head()
#a = temp_ad_feature.groupby('adgroup_id').count()>1
#b = a[a['price']== 'True']
temp_user_info = user_info[['userid','final_gender_code','age_level','shopping_level']]
temp_user_info['final_gender_code'].isnull()
temp_user_info['shopping_level'].isnull()
temp_raw_sample = raw_sample[['user','adgroup_id','clk']]
temp_001 = pd.merge(temp_raw_sample,temp_user_info,how = 'inner',left_on = 'user',right_on = 'userid')[['userid','adgroup_id','final_gender_code','age_level','shopping_level','clk']]
temp_result = pd.merge(temp_001,temp_ad_feature,how = 'inner',on = 'adgroup_id')[['userid','clk','price','shopping_level']]
temp_002 =temp_result.groupby('userid').agg({'clk':['sum','count']}).reset_index()
#tmp=tmp.groupby('serv_id').agg({'change_slot':['mean','std','min','max']}).reset_index()
#tmp.columns=['serv_id','avg_change_m','std_change_m','min_change_m','max_change_m']
temp_003 = temp_result.groupby('userid').agg({'price':['mean']}).reset_index()
temp_004 = pd.merge(temp_002,temp_003,how = 'inner',on = 'userid')
temp_004.columns = ['userid','clk_sum','clk_count','avg_price']
temp_005 = temp_result[['userid','shopping_level']].drop_duplicates()
temp_006 = pd.merge(temp_004,temp_005,how = 'inner',on = 'userid')
temp_006['clk_rate'] = round(temp_006['clk_sum']/temp_006['clk_count'] * 100,2)
temp_006['avg_price'] = round(temp_006['avg_price'],2)
Mid_result = temp_006[['userid','clk_rate','shopping_level','avg_price']]
#Mid_result['clk_rate'] = Mid_result['clk_rate'].map({1:'浅层用户',2:'中度用户',3:'深度用户'})
#Mid_result['clk_rate'] = Mid_result.loc[Mid_result['clk_rate']<'5.19','clk_rate'] = '低'
#Mid_result['clk_rate'] = Mid_result.loc[Mid_result['clk_rate']>='5.19','clk_rate'] = '高'
#Mid_result['avg_price'] = Mid_result.loc[Mid_result['avg_price']>='190.84','avg_price'] = '高'
#Mid_result['avg_price'] = Mid_result.loc[Mid_result['avg_price']<'190.84','avg_price'] = '低'
x = pd.DataFrame(Mid_result)
x.to_excel('RFM_model.xlsx')
import pandas as pd
k = 5 #聚类的类别
iteration = 500 #最大循环次数
data = pd.read_excel("RFM_model.xlsx",index_col="ID")
data = data.iloc[:,1:4] #1-3列是 R F M响应列的数据
data_zs = (data - data.mean())/data.std() #数据标准化 数据与均值的差值比上方差
from sklearn.cluster import KMeans
model = KMeans(n_clusters=k,n_jobs=4,max_iter=iteration) #并发数设为4
model.fit(data_zs) #开始聚类
#简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
r = pd.concat([r2,r1],axis=1) #1横向连接,0是纵向
r.columns = list(data.columns)+[u'聚类类别'] #重命名表头
print(r)
#详细输出原始数据及类别
r = pd.concat([data,pd.Series(model.labels_,index=data.index)],axis=1)
r.columns = list(data.columns)+[u'聚类类别']
r.to_excel("1.xlsx")
import matplotlib.pyplot as plt
#RFM模型中三种变量在空间中分布特征
ax = plt.subplot(111,projection = '3d')
ax.scatter(r.iloc[:,0],r.iloc[:,1],r.iloc[:,2],c = r.iloc[:,3]) #绘制数据点
ax.set_xlabel('R')
ax.set_ylabel('F')
ax.set_zlabel('M') #坐标轴
plt.show()
聚类结果如下:


群体特征分析如下:
群体3 ——高挽留用户,用户不太活跃,但消费水平高,对高价商品抱有极大兴趣
群体5——重要发展用户,这类用户很活跃,对广告的接受度很高
2.3.2 用RFM模型对用户进行划分
--广告表
create table temp_ad_feature as
SELECT adgroup_id,
cate_id,
brand,
CAST(price AS DECIMAL(12, 2)) price,
case
when CAST(price AS DECIMAL(12, 2)) < 100 then
1
when CAST(price AS DECIMAL(12, 2)) < 200 then
2
when CAST(price AS DECIMAL(12, 2)) < 300 then
3
when CAST(price AS DECIMAL(12, 2)) < 400 then
4
when CAST(price AS DECIMAL(12, 2)) < 500 then
5
when CAST(price AS DECIMAL(12, 2)) < 600 then
6
when CAST(price AS DECIMAL(12, 2)) < 700 then
7
when CAST(price AS DECIMAL(12, 2)) < 800 then
8
end price_level
from ad_feature
where CAST(price AS DECIMAL(12, 2)) < 800
and cate_id is not null
and price is not null;
--用户表
create table temp_user_profile as
select userid as user_id,
case
when final_gender_code = '1' then
'男'
when final_gender_code = '2' then
'女'
else
null
end gender,
age_level,
case
when pvalue_level = '1' then
'低档消费'
when pvalue_level = '2' then
'中档消费'
when pvalue_level = '3' then
'高档消费'
else
null
end pvalue_level,
case
when shopping_level = '1' then
'浅层用户'
when shopping_level = '2' then
'中度用户'
when shopping_level = '3' then
'深度用户'
else
null
end shopping_level,
occupation,
new_user_class_level
from user_profile;
#点击率均值、价格均值
create table temp_avg_clk_info as
select round(sum(clk ::numeric) / count(1) * 100, 2) avg_clk_rate,
round(avg(case
when clk = '1' then
price
else
null
end),
2) avg_price
from raw_sample t
inner join temp_ad_feature a
on t.adgroup_id = a.adgroup_id
inner join temp_user_profile b
on t.user_id = b.user_id;
#用户的均值(点击率、价格)
create table temp_user_clk_info as
select t.user_id,
shopping_level,
round(sum(clk ::numeric) / count(1) * 100, 2) avg_clk_rate,
round(avg(case
when clk = '1' then
price
else
null
end),
2) avg_price
from raw_sample t
inner join temp_ad_feature a
on t.adgroup_id = a.adgroup_id
inner join temp_user_profile b
on t.user_id = b.user_id
group by t.user_id, shopping_level;
create table temp_user_clk_info_01 as
select user_id,
shopping_level,
case
when avg_clk_rate > 5.19 then
'高'
else
'低'
end clk_rate,
case
when avg_price > 190.84 then
'高'
else
'低'
end price
from temp_user_clk_info t;
drop table temp_user_clk_info_02 ;
create table temp_user_clk_info_02 as
select user_id,
case
when clk_rate = '高' and price = '高' then
'重要价值用户'
when clk_rate = '低' and shopping_level in ('深度用户') and price = '高' then
'重要发展用户'
when clk_rate = '低' and shopping_level in ('中度用户', '浅层用户') and
price = '高' then
'重要挽留用户'
when clk_rate = '高' and price = '低' then
'一般价值用户'
when clk_rate = '低' and price = '低' then
'一般挽留用户'
end pattern
from temp_user_clk_info_01;
RFM模型聚类结果如下:
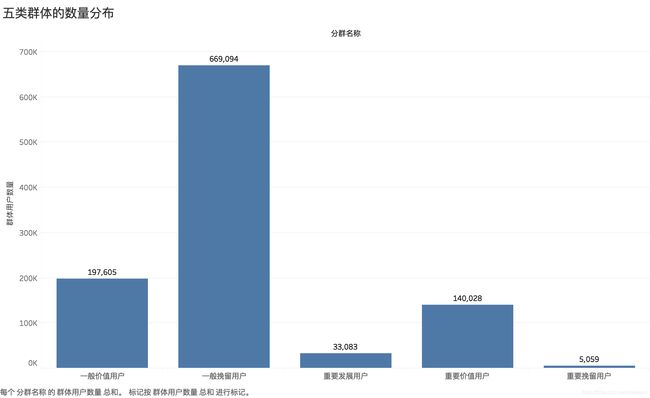
由上图分析,重要价值用户、重要发展用户、重要挽留用户三部分占总体用户的17.05%,这部分用户属于潜在高价值用户;一般价值用户、一般挽留用户两部分占总体用户的82.92%,这部分用户贡献了绝大部分广告点击;
总结:
重要价值用户——用户活跃度高、点击广告商品价位高,这部分用户对企业的潜在贡献价值很高,属于企业的优质用户
重要发展用户——用户活跃度较低,与企业交易很频繁,点击广告商品价位高,但存在一定的流失风险,该类高价值用户是企业利润的潜在来源
重要挽留用户——用户活跃度较低,与企业的交易频率较低,点击广告商品价位较高,这类用户有很高的潜在价值,可采取针对性营销手段吸引他们,提高其广告商品点击率
一般价值用户——用户活跃度高,点击广告商品价位低,购买能力有限,属于价格敏感型用户
一般挽留用户——用户活跃度低,点击广告商品价位低,该部分用户已无法立刻为企业产生价值
四、结论与建议
-
品牌342760广告商品50岁以上女性用户点击率最高,建议增加50岁以上用户商品曝光次数
-
20~50岁年龄段用户占整体用户71.45%,占比相当高,且这部分用户收入稳定,有较强网购理念,建议品牌342760商品增加妈妈、婆婆、父母礼物等关键字样,引导消费者购买
-
0~200价格区间商品女性用户广告曝光次数相较于男性用户,远高于女性用户人数占比;女性用户广告点击率高于男性,考虑到这可能是平台的营销策略,策略效果良好,应继续加大女性用户此类广告商品的投放比例。
-
随用户年龄增加,0~200价格区间广告商品点击率逐渐升高,但曝光次数逐渐下降;50~60岁年龄段用户数占比高于20~30岁年龄段,但曝光次数却小于20~30岁年龄段,建议减少20~30岁年龄段0~200价格区间广告商品投放,增加50~60岁年龄段0~200价格区间广告商品投放,由于该部分用户为价值敏感型用户,可适当发放红包,优惠券等,鼓励消费者购买商品
-
kmeans算法下的群体3点击广告商品价格高、交易频率适中,但该部分用户不太活跃;属于高挽留用户,运营应重点营销该部分潜在高价值用户
-
RFM模型下占比3.7%的重要发展、重要挽留用户属于潜在高价值用户,但存在一定的流失风险,可通过加大产品折扣力度或消息提醒,引导用户点击;