机器学习读书笔记:聚类
文章目录
- 聚类
- 性能度量
-
- 外部指标度量方法
- 内部指标度量方法
- 基本距离计算
- 无序属性距离计算
- 加权距离计算
- 典型聚类算法
-
- K-均值算法
-
-
- k-均值代码
-
- 学习向量量化(LVQ)
- 高斯混合聚类
-
- 最大似然估计(MLE:Maxmium likehood)
- EM算法
- 密度聚类
- 层次聚类
聚类
聚类算法和之前介绍的所有分类算法都不一样。之前所有的算法都是需要标记数据,也就是训练集样本的,这样的算法被称为监督算法。而聚类的相关算法是不需要训练过程的,也就是不需要训练集的,这样的算法被称为无监督算法。
聚类任务是想将已有或者新样本自动的进去划分,让“类似”的样本可以自动聚集成“簇(cluster)”。在聚集之前,算法是不知道要聚集成多少类,都有哪些类的,聚集过程的输入只有样本本身,自动的形成若干“类似”的簇。
聚类典型的应用就是“用户画像”。新来一个用户,需要对用户类型进行自动的分类。一般的做法是先使用历史的用户集进行聚类,形成若干个簇之后,对这些簇进行数据分析,给出一定的类型标签。然后再用这些标签数据进行监督学习的训练,形成模型,利用模型对新用户进行用户类型判断。
聚类算法的形式化定义为:对样本集 D = ( x 1 , x 2 . . . x m ) D=(x_1, x_2 ... x_m) D=(x1,x2...xm),每个样本 x i = ( x i 1 , x i 2 . . . x i n ) x_i=(x_{i1}, x_{i2} ... x_{in}) xi=(xi1,xi2...xin)有n个属性。聚类算法需要将m个样本集自动的划分成k个不相交的簇: C l ∣ l = 1 , 2 , 3... k C_l | l=1,2,3...k Cl∣l=1,2,3...k,其中 C l ⋂ l ′ ≠ l C l ′ = ∅ C_l\bigcap_{l\prime \neq l}C_{l\prime} = \empty Cl⋂l′=lCl′=∅, D = ⋃ l = 1 k C l D=\bigcup_{l=1}^k{C_l} D=⋃l=1kCl,也就是所有的簇互不相交,所有的簇加起来正好是样本集 D D D。
性能度量
评价一个聚类算法,不能喝监督学习中的算法一样,因为聚类算法没有测试集,也没有具体的目标,所以没法用测试集去进行判断。因此需要一些新的度量方法来判断算法性能的好坏。
评价方法主要分两类:
- 第一类是依靠“外部指标”,也就是和其他的已经证明OK了的外部参考模型的聚类结果进行比较,看看两者的差距。
- 第二类是进行 “内部指标”进行衡量,看看每个簇内部的样本集有多“类似”,而簇与簇之间的差距是不是很“明显”。
外部指标度量方法
首先定义几个值:
- 数据集 D = { x 1 , x 2 . . . x m } D=\lbrace x_1, x_2 ... x_m \rbrace D={x1,x2...xm}
- 聚类学习器划分的簇为 C = { C 1 , C 2 . . . C k } C = \lbrace C_1, C_2 ... C_k \rbrace C={C1,C2...Ck}, 用 λ \lambda λ 表示聚类学习器的簇标记向量
- 外部参考模型对同一数据集划分的簇为 C ∗ = { C 1 ∗ , C 2 ∗ . . . C s ∗ } C^*=\lbrace C_1^*, C_2^* ... C_s^* \rbrace C∗={C1∗,C2∗...Cs∗}, 用 λ ∗ \lambda^* λ∗ 表示外部参考模型的簇标记向量
- 将数据集的样本两两配对,形成4个数值:
- a = ∣ S S ∣ , S S = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ = λ j ∗ , i < j } a=|SS|, SS=\lbrace (x_i,x_j)|\lambda_i=\lambda_j, \lambda_i^*=\lambda_j^*, i
a=∣SS∣,SS={(xi,xj)∣λi=λj,λi∗=λj∗,i<j} ,表示两个样本在聚类学习器中是划分到了同一个簇,在参考模型中也是划分到了同一个簇。 - b = ∣ S D ∣ , S D = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ ≠ λ j ∗ , i < j } b=|SD|, SD=\lbrace (x_i,x_j)|\lambda_i=\lambda_j, \lambda_i^*\neq\lambda_j^*, i
b=∣SD∣,SD={(xi,xj)∣λi=λj,λi∗=λj∗,i<j} ,表示两个样本在聚类学习器中是划分到了同一个簇,在参考模型中没有划分到同一个簇。 - c = ∣ D S ∣ , D S = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ∗ = λ j ∗ , i < j } c=|DS|, DS=\lbrace (x_i,x_j)|\lambda_i\neq\lambda_j, \lambda_i^*=\lambda_j^*, i
c=∣DS∣,DS={(xi,xj)∣λi=λj,λi∗=λj∗,i<j} ,表示两个样本在聚类学习器中没有划分到同一个簇,在参考模型中是划分到了同一个簇。 - d = ∣ D D ∣ , D D = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ∗ ≠ λ j ∗ , i < j } d=|DD|, DD=\lbrace (x_i,x_j)|\lambda_i\neq\lambda_j, \lambda_i^*\neq\lambda_j^*, i
d=∣DD∣,DD={(xi,xj)∣λi=λj,λi∗=λj∗,i<j} ,表示两个样本在聚类学习器中没有划分到同一个簇,在参考模型中也没有划分到同一个簇。 - a + b + c + d = m ( m − 1 ) 2 a+b+c+d = \frac{m(m-1)}{2} a+b+c+d=2m(m−1)
- a = ∣ S S ∣ , S S = { ( x i , x j ) ∣ λ i = λ j , λ i ∗ = λ j ∗ , i < j } a=|SS|, SS=\lbrace (x_i,x_j)|\lambda_i=\lambda_j, \lambda_i^*=\lambda_j^*, i
根据上面的几个定义,可以定义几种评价方法:
- Jaccard系数,简称JC。 J C = a a + b + c JC=\frac{a}{a+b+c} JC=a+b+ca,取值在 [ 0 , 1 ] [0, 1] [0,1]之间,越大越好。
- FM指数(Fowlkes and Mallows Index, 简称FMI)。 F M I = a a + b ∗ a a + c FMI=\sqrt{\frac{a}{a+b}*\frac{a}{a+c}} FMI=a+ba∗a+ca,取值在 [ 0 , 1 ] [0, 1] [0,1]之间,越大越好。
- Rand指数(Rand Index,简称RI)。 R I = 2 ( a + d ) m ( m − 1 ) RI=\frac{2(a+d)}{m(m-1)} RI=m(m−1)2(a+d),取值在 [ 0 , 1 ] [0, 1] [0,1]之间,越大越好。
内部指标度量方法
基本距离计算
如果没有外部参考,那就只能根据自己的结果来评价。重要的一个评价标准就是同一个簇内的样本要足够“类似”,一般用样本间的距离来描述这个“类似”程度。那么怎么计算样本间的距离呢?最常用的距离计算方法是闵可夫斯基距离,假设有两个样本 x i = ( x i 1 , x i 2 . . . x i n ) x_i=(x_{i1}, x{i2} ... x_{in}) xi=(xi1,xi2...xin)、 x j = ( x j 1 , x j 2 . . . x j n ) x_j=(x_{j1}, x{j2} ... x_{jn}) xj=(xj1,xj2...xjn),那距离的计算方法为:
d i s t m k ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p , p ≥ 1 dist_{mk}(x_i,x_j)=(\sum_{u=1}^n|x_{iu}-x_{ju}|^p)^{\frac{1}{p}}, p\ge1 distmk(xi,xj)=(u=1∑n∣xiu−xju∣p)p1,p≥1
当p=2,那就是欧式距离,p=1,就是曼哈顿距离。
无序属性距离计算
这里还有一个问题,就是样本的属性一般有离散值和连续值两种,连续值就可以根据这个距离公式直接进行计算了,如果是离散值的话,还需要做一点处理。
-
假如有一个属性的定义域为 { 1 , 2 , 3 } \lbrace 1,2,3 \rbrace {1,2,3},简单的说定义域为可计算的数值,只是取值有限,不像连续值一样取值是无限的。同样可以用闵可夫斯基距离进行计算,称之为“有序属性”
-
假如有一个属性的定义域为 { 轮 船 , 飞 机 , 火 车 } \lbrace 轮船,飞机,火车 \rbrace {轮船,飞机,火车},很明显不能使用上面的公式进行计算。这种就成为“无序属性”,可以使用VDM(Value Difference Metric)方法进行处理。定义无序属性 u u u的几个关键值:
- m u , a m_{u,a} mu,a表示属性 u u u在取值为 a a a的样本数
- m u , a , i m_{u,a,i} mu,a,i表示在划分后的第 i i i个簇中,属性 u u u在取值为 a a a的样本数。
- k为划分后簇的数目。
先计算两个无序属性取值 ( a , b ) (a,b) (a,b)之间的距离:
V D M p ( a , b ) = ∑ i = 1 k ∣ m u , a , i m u , a − m u , b , i m u , b ∣ p VDM_p(a,b)=\sum_{i=1}^k|\frac{m_{u,a,i}}{m_{u,a}}-\frac{m_{u,b,i}}{m_{u,b}}|^p VDMp(a,b)=i=1∑k∣mu,amu,a,i−mu,bmu,b,i∣p
中间那一截的含义为分别计算划分后,取值为 a a a的比例与取值为 b b b的比例之差。将这个东西定义为无序属性之间的距离。也就是定义了:轮船( a a a) - 飞机( b b b)的计算方法。
假设样本集中的样本有 n c n_c nc个有序属性,闵可夫斯基的距离就可以演变为:
d i s t m k ( x i , x j ) = ( ∑ u = 1 n c ∣ x i u − x j u ∣ p + ∑ u = n c + 1 n V D M p ( a , b ) ) 1 p , p ≥ 1 dist_{mk}(x_i,x_j)=(\sum_{u=1}^{n_c}|x_{iu}-x_{ju}|^p + \sum_{u=n_c+1}^nVDM_p(a,b))^{\frac{1}{p}}, p\ge1 distmk(xi,xj)=(u=1∑nc∣xiu−xju∣p+u=nc+1∑nVDMp(a,b))p1,p≥1
当然,对于无序属性来说,可能还有一些其他的定义方式,根据业务来进行定义可能更加靠谱。
加权距离计算
如果属性之间是存在权重的: W = ( w 1 , w 2... w n ) W=(w_1,w2 ... w_n) W=(w1,w2...wn),距离可以演变为:
d i s t w m k ( x i , x j ) = ( w 1 ∣ x i 1 − x i 1 ∣ p + w 2 ∣ x i 2 − x i 2 ∣ p . . . w n ∣ x i n − x i n ∣ p ) 1 p dist_{wmk}(x_i,x_j)=(w_1|x_{i1}-x_{i1}|^p + w_2|x_{i2}-x_{i2}|^p ... w_n|x_{in}-x_{in}|^p)\frac{1}{p} distwmk(xi,xj)=(w1∣xi1−xi1∣p+w2∣xi2−xi2∣p...wn∣xin−xin∣p)p1
典型聚类算法
根据样本集不同的信息进行聚类,可以大致分成以下几种类型的聚类算法。
K-均值算法
k-均值算法的思路就是让同一个簇中的样本都是离本簇的中心较近,而离其他簇的中心较远。
k均值算法需要确认到底是分成几个簇:k。

- 算法开始时,根据输入的k值,随机挑选k个样本作为簇的中心:质心。
- 将其他的所有样本都计算与这k个质心的距离(根据上面描述的距离计算公式),选择一个最近的质心所在的簇加入。
- 计算完成后,针对这k个簇中的样本,重新计算质心。
- 将第三步计算得到的质心与当前的质心进行比较,如果不一样,则更新成第三步计算出来的结果。
- 算法的收敛或者说循环结束的条件是,k个质心都没有发生变化就结束。
- PS1:为了防止某些样本点会来回的切换,导致无法收敛,可以设置一个最大运行轮数。
- PS2:为了减少计算量,提前收敛,可以设置一个最小调整幅度阈值,一次调整小于这个值就不进行调整。
k-均值代码
摘自《机器学习实战》
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))#create centroid mat
for j in range(n):#create random cluster centers, within bounds of each dimension
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean
return centroids, clusterAssment
学习向量量化(LVQ)
LVQ算法是聚类算法中的一个另类,LVQ(Learning Vector Quantization)算法需要样本的类别标记,算是半个监督学习算法。
在K-均值算法中,生成聚类的过程是没有什么指导原则的,纯粹靠计算每个簇的质心来进行聚类,而LVQ算法试图从标记样本中学习到一组“质心“,也就是一组向量: { p 1 , p 2 . . . p q } \lbrace p_1,p_2 ... p_q \rbrace {p1,p2...pq},每个向量 p i p_i pi为一个 n n n维向量,并有一个标记 t i t_i ti, t i t_i ti就是类别的标记。
LVQ算法流程如下:

从算法过程上来看:
- 与K-均值不一样的是:LVQ是计算每个样本与向量组之间的距离,而K-均值这个是在每轮计算中产生的。
- 更新方式不一样,在LVQ中,是需要根据样本的标记来进行向量的更新的(在K-均值中是直接计算簇内新的质心)。
- 第5行步骤中获得了样本 x j x_j xj与某个与该样本距离最近的向量 p i ∗ p_{i^*} pi∗,那么需要比较样本的标记 y j y_j yj与该向量的标记 t i ∗ t_{i^*} ti∗。
- 如果相同,那么就通过 p ′ = p i ∗ + η ( x j − p i ∗ ) p\prime=p_{i^*}+\eta(x_j-p_{i^*}) p′=pi∗+η(xj−pi∗),从形式上看,计算后得到的 p ′ p\prime p′是离 x j x_j xj更近(简单推导一下可知: ∣ ∣ p ′ − x j ∣ ∣ 2 = ( 1 − η ) ∣ ∣ p i ∗ − x j ∣ ∣ 2 ||p\prime-x_j||_2=(1-\eta)||p_{i*}-x_j||_2 ∣∣p′−xj∣∣2=(1−η)∣∣pi∗−xj∣∣2)的,也就是说如果样本和向量比较最近且标记相同,就把向量的值往样本这边挪一挪。
- 如果不相同,那么就通过 p ′ = p i ∗ − η ( x j − p i ∗ ) p\prime=p_{i^*}-\eta(x_j-p_{i^*}) p′=pi∗−η(xj−pi∗),从形式上看,计算后得到的 p ′ p\prime p′是离 x j x_j xj更远(简单推导一下可知: ∣ ∣ p ′ − x j ∣ ∣ 2 = ( 1 + η ) ∣ ∣ p i ∗ − x j ∣ ∣ 2 ||p\prime-x_j||_2=(1+\eta)||p_{i*}-x_j||_2 ∣∣p′−xj∣∣2=(1+η)∣∣pi∗−xj∣∣2)的,也就是说如果样本和向量比较最近且标记相同,就把向量的值往样本的反方向挪一挪。
- 获得一组原型向量后,对新的样本就可以直接进行聚类了,离哪个向量近,这个新样本就属于哪个簇。这种原型向量的划分被称为:“Voronoi”划分。其实这个更像一种监督分类算法。
高斯混合聚类
在讲高斯混合聚类之前,必须要熟悉另外两个东西,最大似然估计和EM算法。这是之前的内容,跳过了,这里必须拿出来讲一讲。
最大似然估计(MLE:Maxmium likehood)
最大似然估计简单来说就是根据样本去估计模型中的参数,基于的理论是大数定理,出现的样本一定是概率最大的。也就是说模型中的参数一定是要让当前出现的样本的概率达到最大值。
最大似然估计有几个前提:
- 所有的样本都是基于独立采样生成
- 模型或者说分布已知,参数未知,比如二项分布里的 p p p,正太分布中的 μ \mu μ和 σ \sigma σ。
- 对于函数 p ( x ∣ θ ) p(x|\theta) p(x∣θ),如果 θ \theta θ已知,求 x x x的概率,就是计算样本 x x x的概率。如果 x x x已知,需要去求 θ \theta θ,就是似然估计了。
- 求解的方式,比如是求解二项分布的话,根据 p m ∗ ( 1 − p ) n − m p^m*(1-p)^{n-m} pm∗(1−p)n−m,根据样本代入n和m,对式子进行求导,令求导结果等于0就可以计算得到了,如果超过两个参数,需要求解偏导。
EM算法
EM算法可以解决机器学习中的“隐变量”问题,在真实数据场景中,有很多的样本会确实一些属性值,但是这些数据是有价值的,只是需要处理一下这些缺失的属性值,这些缺失的属性值就成为隐变量。
在训练学习器的过程中,我们是需要根据函数 p ( x ∣ θ ) p(x|\theta) p(x∣θ)中的 x x x去获得 θ \theta θ,这样就可以获得完整的学习器:模型+参数。但是此时 x x x是不完整的,所以我们根据上面的描述: p ( x ∣ θ ) p(x|\theta) p(x∣θ),用 θ \theta θ去估计 x x x,但是 θ \theta θ也是未知的。就会陷入到一个死循环中,EM算法就是想采用一种逐步迭代的思路去打破这个循环:
- 初始化一个 θ \theta θ,用这个初始化参数去估计 x x x中的隐变量 x c x_c xc。
- 用 x c x_c xc放入样本 x x x中,去估计下一个 θ t + 1 \theta_{t+1} θt+1
- 不停的迭代循环,知道达到某个停止条件:最大迭代次数或者说是变动量小于阈值。
基本知识点铺垫完了,可以开始看高斯混合聚类本身的东西了,先看一下什么是高斯混合:
假设样本都是服从高斯分布,随机独立采样获得,那么就会有密度函数:
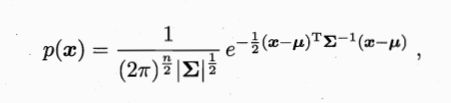
其中:
- μ \mu μ为n维均值向量
- ∑ \sum ∑为协方差矩阵
然后假设样本是服从参数不同的高斯分布,总共有 k k k个不同的高斯分布(看出来了吧,就是想往这个k上来靠)。那么就可以定义一个混合高斯分布:
p M ( x ) = ∑ i = 1 k α i ∗ p ( x ∣ μ i , Σ i ) , 其 中 ∑ i = 1 k α i = 1 p_M(x)=\sum_{i=1}^k{\alpha_i*p(x|\mu_i, \Sigma_i)}, 其中 \sum_{i=1}^k\alpha_i = 1 pM(x)=i=1∑kαi∗p(x∣μi,Σi),其中i=1∑kαi=1
这个概率公式定义了每个样本的生成概率。那么我们已经有了样本,要求样本 x j x_j xj的后验概率 p ( z j = i ∣ x j ) p(z_j=i|x_j) p(zj=i∣xj),也就是这个样本 x j x_j xj是从哪个分布中出来的概率。根据贝叶斯公式(
)可以得到:
p ( z j = i ∣ x j ) = P ( z j = i ) ∗ p M ( x j ∣ z j = i ) p M ( x j ) = α i p ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l p ( x j ∣ μ l , Σ l ) p(z_j=i|x_j)=\frac{P(z_j=i)*p_M(x_j|z_j=i)}{p_M(x_j)} \\ =\frac{\alpha_ip(x_j|\mu_i,\Sigma_i)}{\sum_{l=1}^k\alpha_lp(x_j|\mu_l,\Sigma_l)} p(zj=i∣xj)=pM(xj)P(zj=i)∗pM(xj∣zj=i)=∑l=1kαlp(xj∣μl,Σl)αip(xj∣μi,Σi)
把这个复杂的一腿的公式记为: γ i j \gamma_{ij} γij。
根据之前的聚类套路,就是计算每个样本 x j x_j xj的这个后验概率 γ i j \gamma_{ij} γij,哪个最大,就属于哪个类。但是计算这个东西的过程中,又碰到了手动增加进去的“隐变量”: α \alpha α,所以就需要采用EM算法,将隐变量 α \alpha α和模型参数 μ , Σ \mu, \Sigma μ,Σ一起计算出来。模型参数 μ , Σ \mu,\Sigma μ,Σ的推导过程大家可以去看书。
高斯混合聚类的过程如下:

密度聚类
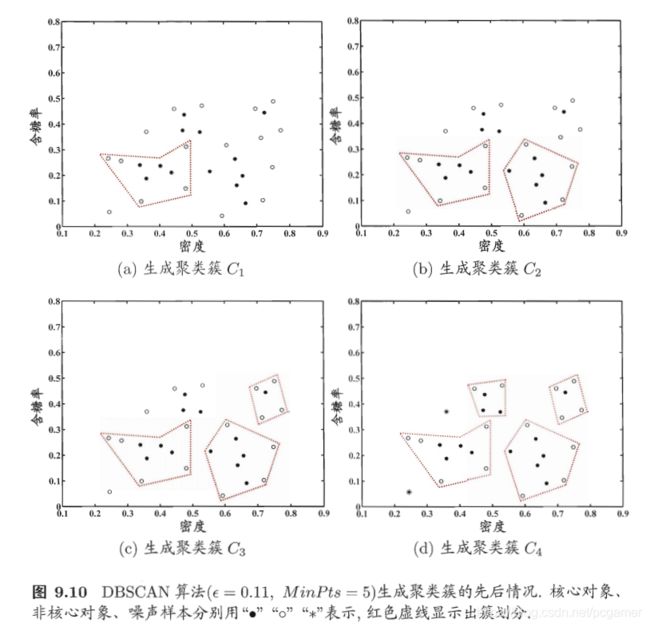
密度聚类实际上一个从某个点出发,找到自己足够近的邻居的过程,这些邻居在算法中用了一个更专业的词:邻域。一个经典的邻域算法是DBSCAN算法,算法中定义了两个邻域参数: ( ϵ , M i n P t s ) (\epsilon, MinPts) (ϵ,MinPts)。由这两个参数确定一个邻域。
- ϵ \epsilon ϵ:定义了样本集中样本与某个样本 x j x_j xj的最小距离,即如果距离不大于 ϵ \epsilon ϵ,即样本位于样本 x j x_j xj的邻域内。
- MinPts:若样本 x j x_j xj的邻域包含的样本数大于MinPts,则称 x j x_j xj为核心对象。
另外,还有几个其他的概念:
- 密度直达:若样本 x j x_j xj位于样本 x i x_i xi的邻域内,且 x i x_i xi是核心对象,则称 x j x_j xj由 x i x_i xi密度直达。
- 密度可达:若 x j x_j xj可以由一系列的中间节点 p , p 1 . . . p,p_1... p,p1...由 x i x_i xi直达,则称 x j x_j xj由 x i x_i xi密度可达。
- 密度相连:若 x i x_i xi和 x j x_j xj均通过 x k x_k xk可达,则称 x i x_i xi, x j x_j xj相连。这里两个样本是距离是相互的,但是不是每个样本点都是核心对象。
示意图:

知道了这些核心概念,算法过程就很容易理解了:

- 核心对象集合初始化为空
- 第2行到第7行是确定每个样本 x j x_j xj的邻域 N c ( x j ) N_c(x_j) Nc(xj),并从中挑出核心对象。
- 从第10行开始到第24行,就是由核心对象来往外扩展生成簇的过程。
- 从核心对象集合 Ω \Omega Ω中随机挑选一个核型对象,通过14-21行的代码将该核型对象的所有密度可达(注意密度可达的定义是需要对方也是核心对象)的样本全部加入到同一个簇内。在整个过程中,使用 Γ = D \Gamma = D Γ=D不停的去减去这些簇中的样本点,最后再第22行的时候,用 Γ o l d − Γ \Gamma_{old}-\Gamma Γold−Γ就是这些样本点了,有点负负得正的意思。
- 刚开始 Γ = D , Γ o l d = Γ \Gamma = D, \Gamma_{old} = \Gamma Γ=D,Γold=Γ
- 选出一个核心对象样本点 x j x_j xj后, Γ = Γ − x j \Gamma = \Gamma-x_j Γ=Γ−xj
- 将核心对象样本点 x j x_j xj的邻域(比如有 x 1 , x 4 , x 9 x_1,x_4,x_9 x1,x4,x9)保存到 Δ \Delta Δ中,然后 Γ = Γ − Δ \Gamma = \Gamma-\Delta Γ=Γ−Δ
- 最后用 Γ o l d − Γ \Gamma_{old} - \Gamma Γold−Γ就等于( x j , x 1 , x 4 , x 9 x_j,x_1,x_4,x_9 xj,x1,x4,x9)了。
- 形成完一个簇后,再重新从 Ω \Omega Ω中挑选核心对象进行扩展,直到 Ω \Omega Ω为空
- 基于密度聚类算法会存在一些样本点没法成为核心对象,就会在算法结束之后成为一些孤立的样本点,成为噪声样本。
《机器学习》一书中的例子:
层次聚类
层次聚类是将样本点分拆或者合并成类似树的结构,树的每一个分支就是一个簇。书中提到的AGNES是基于合并的自底向上的方法。用的思路也比较简单:
-
首先所有的样本都单独成为一个簇。
-
计算簇和簇之间的距离,距离足够近的形成一个新的簇,最终形成一个类似树的结构:
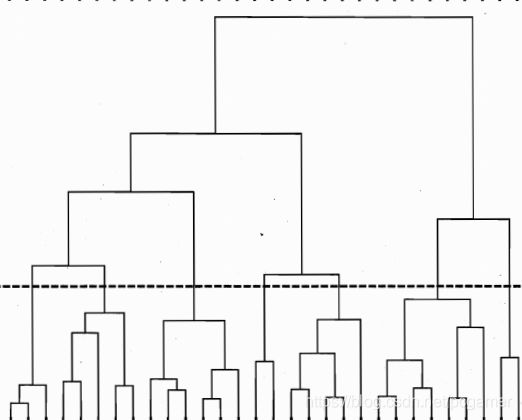
- 通过控制簇的个数k来控制树分支的合并情况。
这里就有一个问题,之前计算的距离是样本之间的距离,在层次聚类里需要计算簇之间的距离,所以需要定义簇的距离如何进行计算。簇实际上就是一个样本集合,所以定义一下关于集合的某种运算即可:
- 最小距离: d i s t ( C i , C j ) = min x ∈ C i , z ∈ C j d i s t ( x , z ) dist(C_i,C_j) = \min_{x\in C_i, z \in C_j}{dist(x,z)} dist(Ci,Cj)=minx∈Ci,z∈Cjdist(x,z),将两个簇内样本之间的最小距离作为簇之间的距离。
- 最大距离: d i s t ( C i , C j ) = max x ∈ C i , z ∈ C j d i s t ( x , z ) dist(C_i,C_j) = \max_{x\in C_i, z \in C_j}{dist(x,z)} dist(Ci,Cj)=maxx∈Ci,z∈Cjdist(x,z),将两个簇内样本之间的最大距离作为簇之间的距离。
- 平均距离: d i s t ( C i , C j ) = 1 ∣ C i ∣ ∣ C j ∣ ∑ x ∈ C i ∑ z ∈ C j d i s t ( x , z ) dist(C_i,C_j) = \frac{1}{|C_i||C_j|}\sum_{x\in C_i}\sum_{z\in C_j}{dist(x,z)} dist(Ci,Cj)=∣Ci∣∣Cj∣1∑x∈Ci∑z∈Cjdist(x,z),将两个簇内样本之间的平均距离作为簇之间的距离。
定义好距离的计算方法之后,算法过程就比较清楚了:
