mobileNet
mobileNetV1
1.背景
- 传统卷积神经网络,内存需求大,运算量大,导致无法在移动设备以及嵌入式设备上运行。
- MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
- 论文原文:

2.网络中的亮点
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α、β
3.传统卷积和DW卷积区别
- 1.传统卷积

卷积核channel=输入特征矩阵channel
输出特征矩阵channel=卷积核个数
- 2.DW卷积
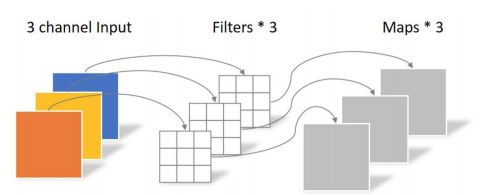
卷积核channel=1
输入特征矩阵channel=卷积核个数=输出特征矩阵channel
4.PW卷积和DW卷积
- 1.DW卷积

卷积核channel=1
输入特征矩阵channel=卷积核个数=输出特征矩阵channel
-
2.PW卷积

-
3.MobileNet中的DW卷积和PW卷积

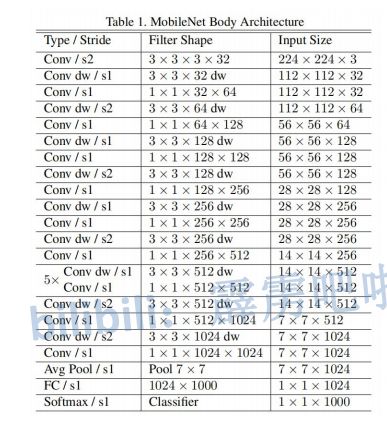
5.MobileNetV1计算量及网络结构

6.MobileNetV1局限性
- 没有残差连接
- 很多Depthwise卷积核训练出来是0:
- (1)卷积核权重数量和通道数量太少
- (2)太单薄
- (3)RELU
- (4)低精度
# MobileNetV2 # ## 1.网络背景 ## - MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网络,准确率更高,模型更小。
- 论文原文:

2.网络亮点
- Inverted Residuals(倒残差结构)
- Linear Bottlenecks

第一个1×1卷积表示升维,第二个1×1卷积表示降维
3.网络详解
-
1.残差块
-
(1)1×1卷积降维
-
(2)3×3卷积
-
(3)1×1卷积升维
-
2.倒残差块
-
(1)1×1卷积升维
-
(2)3×3卷积
-
(3)1×1卷积降维

-
3.RELU6

RELU激活函数对低维特征信息造成大量损失
4.倒残差模块

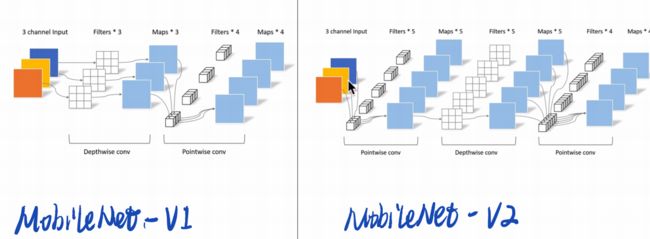
当stirde=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接。

5.MobileNetV2参数结构
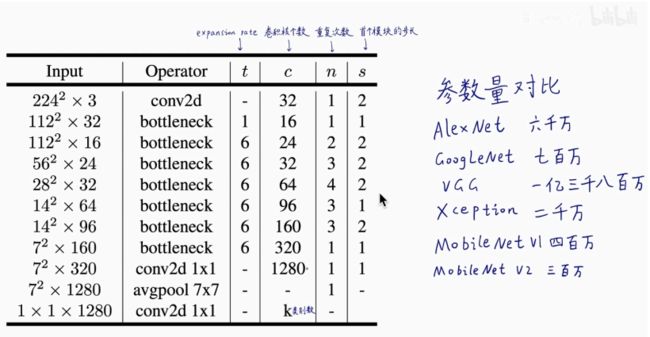
- (1)t是扩展因子
- (2)c是输出特征矩阵
- (3)n是bottleneck的重复次数
- (4)s是步距(针对第一层,其他层均为1)
6.MobileNetV2代码详解
from torch import nn
import torch
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x