【python groupby】分组聚合groupby的用法
对dataframe进行groupby之后得到的是一个groupby对象,不能直接打印输出,但可以对这个对象进行各种计算
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df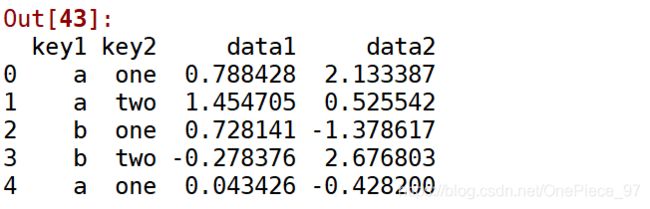
1.1 根据A列的标签取值,分组计算B列的均值、和、方差、标准差等
df['data1'].groupby(df['key1']).mean()
# 其中
df['data1'].groupby(df['key1'])
# 等价于
df.groupby(df['key1'])['data1']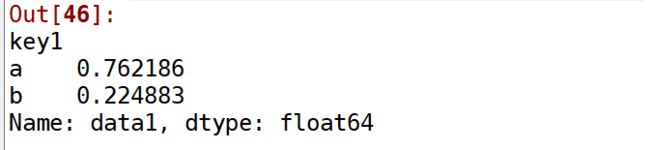
1.1.1 需要区分以下两种用法,踩过坑。。。
1.1.1-1 如果传入的是series或者是1维的ndarray,一般不会出现什么错
df['data1'].groupby([df['key1'], df['key2']]).mean()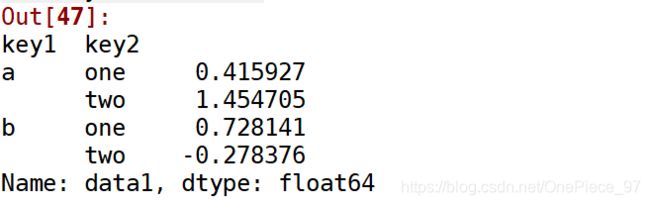
1.1.1-2 如果传入的是字符串列表,列表的取值必须是df的字段名,就是说'key1', 'key2'必须在.groupby之前这个dataframe中
df.groupby(['key1', 'key2']).mean()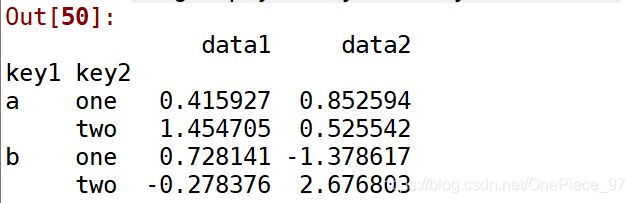
1.2 size方法
返回一个包含组大小信息的Series
df.groupby(['key1', 'key2']).size()
1.3 支持迭代遍历
groupby对象支持遍历,生成一个组名和数据块组成的元组(组名,数据块),有点类似于enumerate,单层组名为字符串,如果组名有多层的形式,组名将会以元组的形式展示。
for name,group in df.groupby(['key1', 'key2']):
print(name)
print(group, end='\n\n')
1.4 按照dataframe字段的数据类型对数据进行分块
groupby 的axis参数默认为axis=0,也可以设置为任意轴,设为1就是对列进行操作
如按照数据类型对数据进行分块
for name,group in df.groupby(df.dtypes, axis=1):
print(name)
print(group, end='\n\n')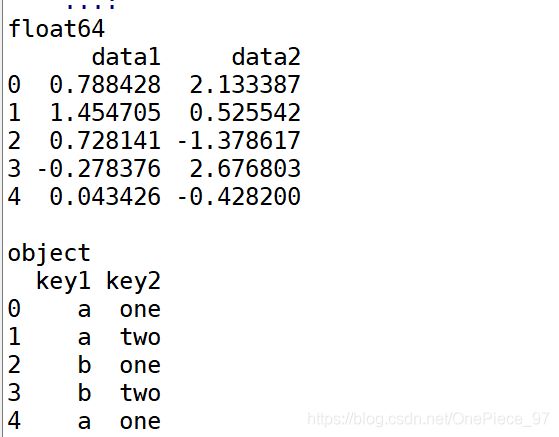
1.5 使用字典或Serise进行分组
people = pd.DataFrame(np.random.randn(5,5),
columns = ['a','b','c','d','e'],
index = ['joe','steve','wes','jim','travis'])
# 把一些值设为空值
people.iloc[2:3, [1,2]] = np.nan
people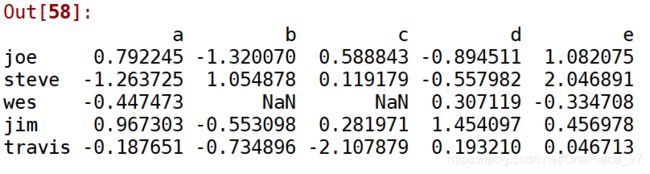
1.5-1 以字典作为分组规则
mapping = {'a':'red', 'b':'red', 'c':'blue',
'd':'blue', 'e':'red', 'f':'orange'}by_column = people.groupby(mapping, axis=1).sum()
by_column 
1.5-2 以Series作为分组规则
map_series = pd.Series(mapping)
map_series
people.groupby(mapping, axis=1).count()
1.6 使用函数进行分组
people.groupby(len, axis=1).count()
Out[67]:
1
joe 5
steve 5
wes 3
jim 5
travis 5
people.groupby(len, axis=0).count()
Out[68]:
a b c d e
3 3 2 2 3 3
5 1 1 1 1 1
6 1 1 1 1 11.7 使用索引层级进行分组
columns = pd.MultiIndex.from_arrays([['us','us','us','jp','jp'],
[1,3,5,1,3]],
names=['city', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4,5), columns=columns)
hier_df
hier_df.groupby(level='city', axis=1).count()
groupby对象常用方法

groupby高阶应用
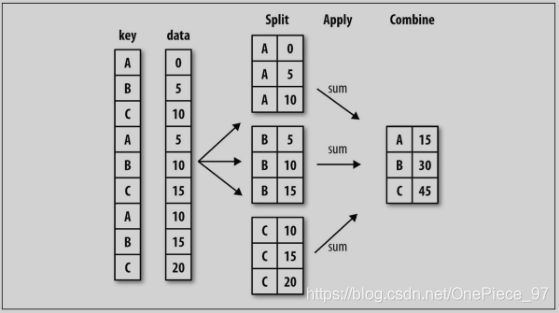
groupby.apply() 和 groupby.agg()
先分组然后对每个单独的组进行apply函数的操作,然后尝试将每一块拼接到一起
df = pd.DataFrame({'Q':['LI','ZHANG','ZHANG','LI','WANG'],
'A' : [1,1,1,2,2],
'B' : [1,-1,0,1,2],
'C' : [3,4,5,6,7]})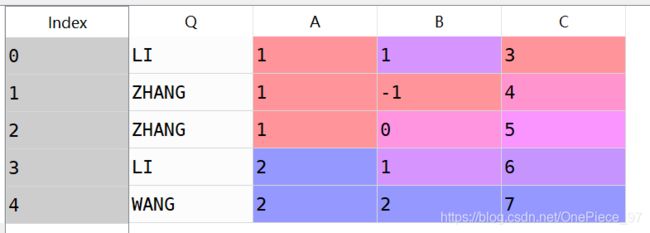
df.groupby('Q').apply(lambda x: print(x, end='\n\n'))
df.groupby('Q').agg(lambda x: print(x, end='\n\n'))
out:
0 1
3 2
Name: A, dtype: int64
4 2
Name: A, dtype: int64
1 1
2 1
Name: A, dtype: int64
0 1
3 1
Name: B, dtype: int64
4 2
Name: B, dtype: int64
1 -1
2 0
Name: B, dtype: int64
0 3
3 6
Name: C, dtype: int64
4 7
Name: C, dtype: int64
1 4
2 5
Name: C, dtype: int64可以看出,使用apply()处理的对象是一个个的类如DataFrame的数据表,然而agg()则每次只传入一列。
有趣的是,agg()可以同时传入多个函数:
df.groupby('Q').agg(['mean','std','count','max'])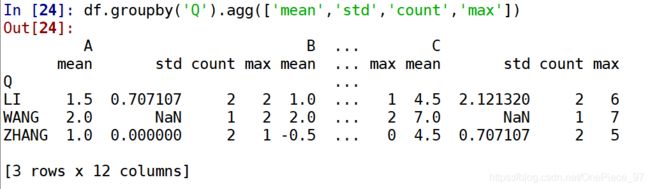
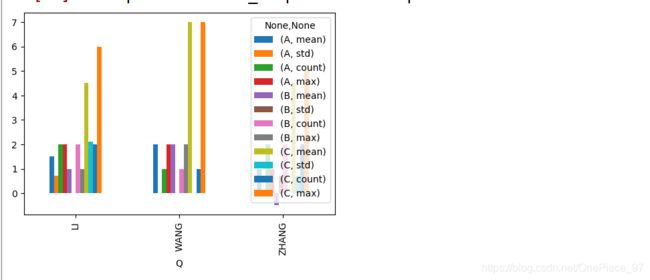
df.groupby('Q').agg(['mean','std','count','max']).plot(kind='bar')
df.groupby('Q').apply(np.mean)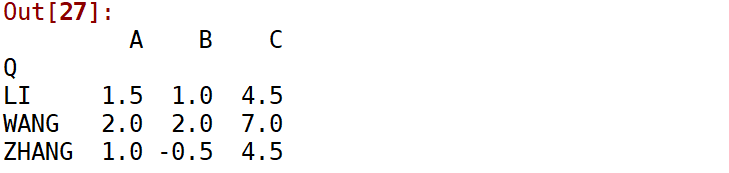
在使用apply的过程中,如果还需要传递其他参数或关键字的话,可以把这些放在函数后进行传递
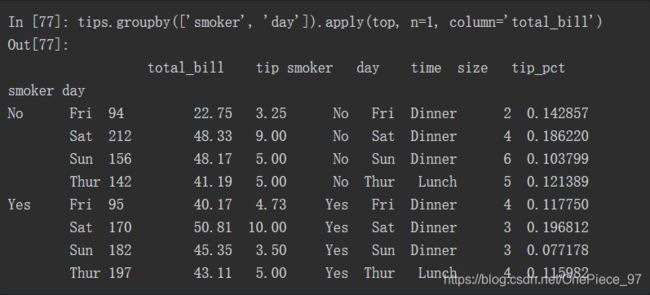
transform方法
.transform 可以产生一个标量值,并广播到各分组的尺寸数据中
.transform 可以产生一个与输入尺寸相同的对象
.transform 不可以改变它的输入
df = pd.DataFrame({'key': ['a', 'b', 'c'] * 4,
'value': np.arange(12)})
df
df.groupby('key').value.mean()
如果想要产生一个Series,它的尺寸和df['value']一样,但值都被‘key’分组后计算的值替代。可以向transform传递一个匿名函数
df.groupby('key').transform(lambda x: x.mean()) # 替换成均值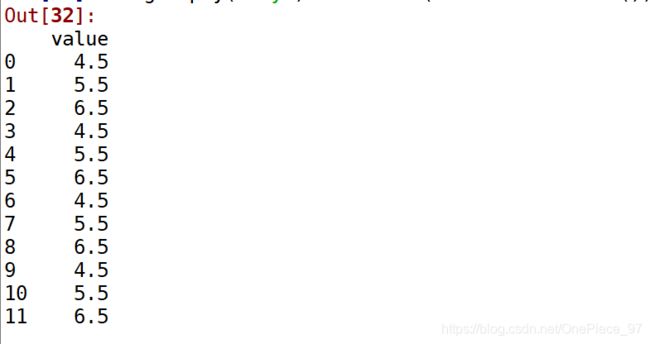
如果传递的函数是python的内建函数,可以像groupby中的agg方法一样传递一个字符串别名:
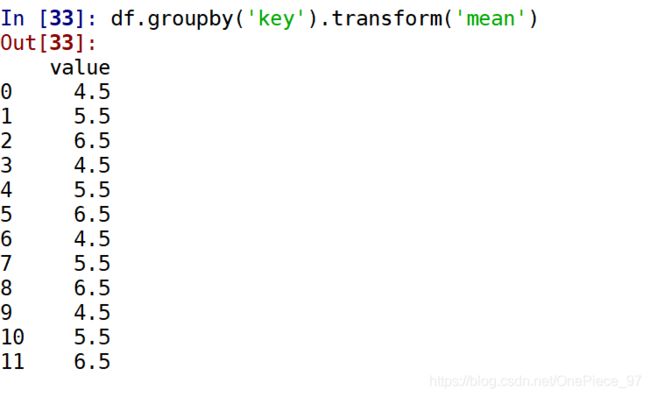
与apply相似,transform可以与返回Series的函数一起使用,但结果必须和输入有相同的大小。如使用lambda函数给每个组乘以2
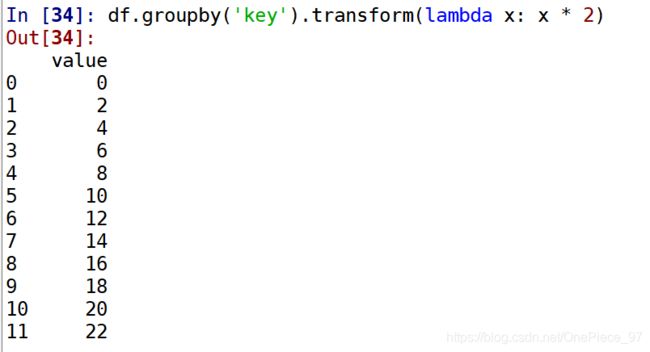
还可以按照每个组降序排序
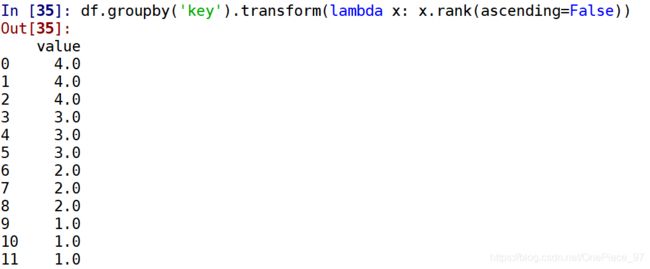
定义一个标准化的函数
def normallize(x):
return (x - x.mean()) / x.std()
df.groupby('key').transform(normallize) 