GPU 上的 PyTorch - 用 CUDA 训练神经网络(pytorch系列-30)
在 GPU 上运行 PyTorch 代码 - 神经网络编程指南
在本集中,我们将学习如何使用GPU与PyTorch。我们将看到如何使用GPU的一般方法,我们将看到如何应用这些一般技术来训练我们的神经网络。

使用GPU进行深度学习
如果你还没有看过关于为什么深度学习和神经网络使用 GPU 的那一集,一定要把那一集和这一集一起回顾一下,以获得对这些概念的最佳理解。
现在,我们将用一个PyTorch GPU的例子来打基础。
PyTorch GPU 例子
PyTorch 允许我们在程序内部进行计算时,将数据无缝地移入或移出 GPU。
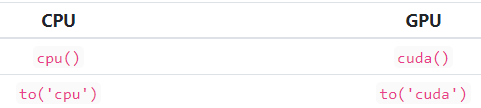
当我们进入 GPU 时,我们可以使用 cuda() 方法,当我们进入 CPU 时,我们可以使用 cpu() 方法。
我们还可以使用to()方法。去GPU的时候,我们写到('cuda'),去CPU的时候,我们写到('cpu')。to()方法是首选的方式,主要是因为它更灵活。我们将看到一个使用前两种方式的例子,然后我们将默认一直使用to()变体。
在训练过程中,要想利用我们的GPU,有两个基本要求。这些要求如下:
1、数据必须移到GPU上
2、网络必须移到GPU上。
默认情况下,在创建 PyTorch 张量或 PyTorch 神经网络模块时,会在 CPU 上初始化相应的数据。具体来说,这些数据存在于 CPU 的内存中。
现在,让我们创建一个张量和一个网络,看看我们如何从 CPU 移动到 GPU。
在这里,我们创建一个张量和一个网络:
t = torch.ones(1,1,28,28)
network = Network()
现在,我们调用 cuda ()方法,将张量和网络重新分配给复制到 GPU 上的返回值:
t = t.cuda()
network = network.cuda()
接下来,我们可以从网络中得到一个预测,并且看到预测张量的设备属性确认数据是在 cuda 上,这就是 GPU:
> gpu_pred = network(t)
> gpu_pred.device
device(type='cuda', index=0)
同样,我们也可以反其道而行之:
> t = t.cpu()
> network = network.cpu()
> cpu_pred = network(t)
> cpu_pred.device
device(type='cpu')
简而言之,这就是我们如何利用 PyTorch 的 GPU 功能。我们现在应该关注的是一些隐藏在我们刚刚看到的代码表面之下的重要细节。
例如,虽然我们已经使用了cuda()和cpu()方法,但实际上它们并不是我们最好的选择。此外,网络实例和张量实例之间的方法有什么区别呢?这些毕竟是不同的对象类型,也就是说两个方法是不同的。最后,我们要把这段代码集成到一个工作实例中,并做一个性能测试。
使用 GPU 的总体思路
目前的主要结论是,我们的网络和数据都必须存在于 GPU 上,以便使用 GPU 执行计算,这适用于任何编程语言或框架。
我们在接下来的演示中会看到,这对CPU也是如此。GPU和CPU都是在数据上进行计算的计算设备,所以任何两个在计算中直接相互使用的值,都必须存在于同一个设备上。
图形处理器(GPU)上的 PyTorch 张量计算
让我们通过演示一些张量计算来深入了解。
我们首先创建两个张量:
t1 = torch.tensor([
[1,2],
[3,4]
])
t2 = torch.tensor([
[5,6],
[7,8]
])
现在,我们将通过检查设备属性来检查这些张量被初始化在哪个设备上:
> t1.device, t2.device
(device(type='cpu'), device(type='cpu'))
正如我们所期望的,我们看到,实际上,两个张量都在同一个设备上,即 CPU。让我们把第一个张量 t1移到 GPU 上。
> t1 = t1.to('cuda')
> t1.device
device(type='cuda', index=0)
我们可以看到这个张量的设备已经改成了 cuda,即 GPU。注意 to ()方法在这里的使用。我们不调用特定的方法移动到设备,而是调用相同的方法并传递一个指定设备的参数。使用 to ()方法是在设备之间移动数据的首选方法。
此外,请注意重新分配。该操作未就位,因此需要重新分配。
让我们来做个实验。我想通过尝试在这两个张量 t1和 t2上执行计算来测试我们之前讨论的内容,我们现在知道这两个张量在不同的设备上。
因为我们预期会出现错误,所以我们将调用包装在 try 中并捕获异常:
try:
t1 + t2
except Exception as e:
print(e)
expected device cuda:0 but got device cpu
通过反转操作的顺序,我们可以看到错误也发生了变化:
try:
t2 + t1
except Exception as e:
print(e)
expected device cpu but got device cuda:0
这两个错误都告诉我们,二进制加运算期望第二个参数具有与第一个参数相同的设备。理解此错误的含义可以帮助调试这些类型的设备不匹配。
最后,为了完成,让我们将第二个张量移动到 cuda 设备,看看操作是否成功。
> t2 = t2.to('cuda')
> t1 + t2
tensor([[ 6, 8],
[10, 12]], device='cuda:0')
PyTorch nn.Module在GPU上的计算
我们刚刚看到了如何将 tensors 移入和移出设备。现在,让我们看看如何通过 PyTorch nn.Module 实例来实现这一点。
简单来说,我们感兴趣的是了解在GPU或CPU等设备上运行对网络有什么意义。抛开PyTorch不谈,这是基本问题。
我们通过将网络的参数移动到所述设备上,将网络放在一个设备上。让我们创建一个网络:
network = Network()
现在,让我们看看网络的参数:
for name, param in network.named_parameters():
print(name, '\t\t', param.shape)
conv1.weight torch.Size([6, 1, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([12, 6, 5, 5])
conv2.bias torch.Size([12])
fc1.weight torch.Size([120, 192])
fc1.bias torch.Size([120])
fc2.weight torch.Size([60, 120])
fc2.bias torch.Size([60])
out.weight torch.Size([10, 60])
out.bias torch.Size([10])
在这里,我们创建了一个 PyTorch 网络,并遍历了网络的参数。正如我们所看到的,网络的参数是网络内部的权重和偏差。
换句话说,就像我们已经看到的那样,这些仅仅是存在于设备上的张量。让我们通过检查每个参数的设备来验证这一点。
for n, p in network.named_parameters():
print(p.device, '', n)
cpu conv1.weight
cpu conv1.bias
cpu conv2.weight
cpu conv2.bias
cpu fc1.weight
cpu fc1.bias
cpu fc2.weight
cpu fc2.bias
cpu out.weight
cpu out.bias
这表明网络中的所有参数默认都是在 CPU 上初始化的。
对此的一个重要考虑是,它解释了为什么。像网络这样的模块实例实际上并没有设备。它不是存在于设备上的网络,而是存在于设备上的网络内的张量。
让我们看看当我们要求一个网络移动到 GPU 上时会发生什么:
network.to('cuda')
Network(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=192, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=60, bias=True)
(out): Linear(in_features=60, out_features=10, bias=True)
)
请注意,这里不需要重新分配。这是因为就网络实例而言,该操作是在原地进行的。但是,此操作可以作为重赋值操作使用。为了使 nn.Module 实例和 PyTorch tensors 之间保持一致,最好采用这种方式。
我们可以看到,现在所有的网络参数都有cuda的设备。
for n, p in network.named_parameters():
print(p.device, '', n)
cuda:0 conv1.weight
cuda:0 conv1.bias
cuda:0 conv2.weight
cuda:0 conv2.bias
cuda:0 fc1.weight
cuda:0 fc1.bias
cuda:0 fc2.weight
cuda:0 fc2.bias
cuda:0 out.weight
cuda:0 out.bias
向网络传递样本
让我们通过向网络传递一个示例来完成这个演示。
sample = torch.ones(1,1,28,28)
sample.shape
torch.Size([1, 1, 28, 28])
这给了我们一个样本张量,我们可以这样传递:
try:
network(sample)
except Exception as e:
print(e)
Expected object of device type cuda but got device type cpu for argument #1 'self' in call to _thnn_conv2d_forward
由于我们的网络是在GPU上,而这个新创建的样本默认是在CPU上,所以我们得到了一个错误。这个错误是在告诉我们,在调用第一个卷积层的前向方法时,CPU张量被预期为GPU张量。这正是我们之前直接添加两个张量时看到的情况。
我们可以像这样把我们的样本发送到 GPU 来解决这个问题:
try:
pred = network(sample.to('cuda'))
print(pred)
except Exception as e:
print(e)
tensor([[-0.0685, 0.0201, 0.1223, 0.1075, 0.0810, 0.0686, -0.0336, -0.1088, -0.0995, 0.0639]]
, device='cuda:0'
, grad_fn=
)
最后,一切按照预期进行,我们得到了一个预测。
编写设备不可知的 PyTorch 代码
在总结之前,我们需要谈谈编写设备不可知代码的问题。这个术语(device agnostic)意味着我们的代码不依赖于底层设备。在阅读 PyTorch 文档时可能会遇到这个术语。
例如,假设我们写的代码到处使用cuda()方法,然后,我们把代码交给一个没有GPU的用户。这样做是行不通的。别担心。我们还有其他选择!
还记得我们之前看到的 cuda ()和 cpu ()方法吗?
我们将首选 to ()方法的原因之一是,to ()方法是参数化的,这使得更改我们选择的设备更加容易,也就是说,它是灵活的!
例如,用户可以将 cpu 或 cuda 作为深度学习程序的参数,这将允许程序与设备无关。
允许程序的用户传递一个决定程序行为的参数,也许是使程序与设备无关的最佳方式。不过,我们也可以使用 PyTorch 来检查支持的 GPU,并以此来设置我们的设备。
torch.cuda.is_available()
True
如果 cuda 可用,那么就使用它!
PyTorch GPU 训练性能测试
现在让我们看看如何将GPU的使用添加到训练循环中。我们要用我们到目前为止在该系列中开发的代码来做这个添加。
这将使我们能够很容易地比较时间,CPU VS GPU。
重构 RunManager 类
在更新训练循环之前,我们需要更新RunManager类。在begin_run()方法里面,我们需要修改传递给add_graph方法的图像张量的设备。
它应该是这样的:
def begin_run(self, run, network, loader):
self.run_start_time = time.time()
self.run_params = run
self.run_count += 1
self.network = network
self.loader = loader
self.tb = SummaryWriter(comment=f'-{run}')
images, labels = next(iter(self.loader))
grid = torchvision.utils.make_grid(images)
self.tb.add_image('images', grid)
self.tb.add_graph(
self.network
,images.to(getattr(run, 'device', 'cpu'))
)
这里,我们使用内置的 getattr ()函数来获取运行对象上的设备的值。如果运行对象没有设备,则返回 cpu。这使得代码向后兼容。如果我们不为我们的运行指定一个设备,它仍然可以工作。
请注意,网络不需要移动到设备上,因为它的设备是在传入之前设置的。然而,图像张量是从加载器中得到的。
重构训练循环
我们将设置我们的配置参数有一个设备。这里的两个逻辑选项是 cuda 和 cpu。
params = OrderedDict(
lr = [.01]
,batch_size = [1000, 10000, 20000]
, num_workers = [0, 1]
, device = ['cuda', 'cpu']
)
随着这些设备值添加到我们的配置中,现在它们将可以在我们的培训练循环中被访问。
在我们运行的顶端,我们会创造一个设备,在运行和训练循环中传递。
device = torch.device(run.device)
我们首先要使用这个设备,就是在初始化网络的时候。
network = Network().to(device)
这将确保网络移动到适当的设备。最后,我们将更新图像和标签张量,将它们分开打包并发送到设备,如下所示:
images = batch[0].to(device)
labels = batch[1].to(device)
就是这样,我们已经准备好运行这段代码并查看结果。

在这里,我们可以看到 cuda 设备显著地超过了 cpu 的2到3倍。结果可能会有所不同。
英文原文链接是:https://deeplizard.com/learn/video/Bs1mdHZiAS8