动手学深度学习 (4-7章)代码
多层感知机的从零开始实现
多层感知机的简介实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std = 0.01)
net.apply(init_weights)
batch_size,lr,num_epochs = 256,0.1,10
loss = nn.CrossEntropyLoss(reduction = 'none')
trainer = torch.optim.SGD(net.parameters(),lr = lr)
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
d2l.plt.show()

多项式拟合
权重衰退从0开始
import torch
from torch import nn
from d2l import torch as d2l
n_train,n_test,num_inputs,batch_size = 20,100,200,5
true_w,true_b = torch.ones((num_inputs,1)) * 0.01,0.05
train_data = d2l.synthetic_data(true_w,true_b,n_train)
train_iter = d2l.load_array(train_data,batch_size)
test_data = d2l.synthetic_data(true_w,true_b,n_test)
test_iter = d2l.load_array(test_data,batch_size,is_train = False)
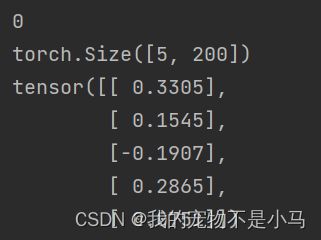
for step,(train_iter_features,train_iter_labels) in enumerate(train_iter):
print(step)
print(train_iter_features.shape)
print(train_iter_labels)
break
def init_params():
w = torch.normal(0,1,size = (num_inputs,1),requires_grad = True)
b = torch.zeros(1,requires_grad = True)
return [w,b]
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
def l1_penalty(w):
return torch.sum(torch.abs(w))
def train(lambd):
w,b = init_params()
net,loss = lambda X:d2l.linreg(X,w,b),d2l.squared_loss
num_epochs,lr = 100,0.003
animator = d2l.Animator(xlabel = 'epochs',ylabel = 'loss',yscale = 'log',xlim = [5,num_epochs],legend = ['train','test'])
for epoch in range(num_epochs):
for X,y in train_iter:
l = loss(net(X),y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w,b],lr,batch_size)
if(epoch + 1) % 5 == 0:
animator.add(epoch + 1,(d2l.evaluate_loss(net,train_iter,loss),d2l.evaluate_loss(net,test_iter,loss)))
d2l.plt.show()
print('w的L2范数是:',torch.norm(w).item())
train(lambd = 0)
train(lambd = 5)



Dropout
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X,dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
num_inputs,num_outputs,num_hiddens1,num_hiddens2 = 784,10,256,256
dropout1,dropout2 = 0.2,0.5
class Net(nn.Module):
def __init__(self,num_inputs,num_outputs,num_hiddens1,num_hiddens2,is_training = True):
super(Net,self).__init__()
self.num_inputs = num_inputs
self_training = is_training
self.lin1 = nn.Linear(num_inputs,num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1,num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2,num_outputs)
self.relu = nn.ReLU()
def forward(self,X):
H1 = self.relu(self.lin1(X.reshape((-1,self.num_inputs))))
if self.training == True:
H1 = dropout_layer(H1,dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2,dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs,num_outputs,num_hiddens1,num_hiddens2)
num_epochs,lr,batch_size = 10,0.5,256
loss = nn.CrossEntropyLoss(reduction = 'none')
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(),lr = lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
d2l.plt.show()

Lenet
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self,x):
return x.view(-1,1,28,28)
net=nn.Sequential(
Reshape(),
nn.Conv2d(1,6,kernel_size = 5,padding = 2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(6,16,kernel_size = 5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size = 2,stride = 2),
# 展平层,展平之后才能进行全连接
nn.Flatten(),
nn.Linear(16*5*5,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
X = torch.rand(size = (1,1,28,28),dtype = torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
Alexnet
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = nn.Sequential(
Reshape(),
nn.Conv2d(1, 6, kernel_size=5, padding=2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
# 展平层,展平之后才能进行全连接
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120),nn.Sigmoid(),
nn.Linear(120, 84),nn.Sigmoid(),
nn.Linear(84, 10)
)
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)VGG
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs,in_channels,out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels,out_channels,kernel_size = 3,padding = 1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size = 2,stride = 2))
return nn.Sequential(*layers)
conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs,out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs,in_channels,out_channels))
in_channels = out_channels
return nn.Sequential(*conv_blks,nn.Flatten(),
nn.Linear(out_channels * 7 * 7,4096),nn.ReLU(),nn.Dropout(0.5),
nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(0.5),
nn.Linear(4096,10))
net = vgg(conv_arch)
X = torch.randn(size = (1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)NiN
import torch
from torch import nn
from d2l import torch as d2l
def NiN_blocks(in_channels,out_channels,kernel_size,padding,stride):
return nn.Sequential(nn.Conv2d(in_channels = in_channels,out_channels = out_channels,kernel_size = kernel_size,padding = padding,stride = stride),nn.ReLU(),
nn.Conv2d(in_channels = out_channels,out_channels = out_channels,kernel_size = 1),nn.ReLU(),
nn.Conv2d(in_channels = out_channels,out_channels = out_channels,kernel_size = 1),nn.ReLU())
def NiN():
net = nn.Sequential(NiN_blocks(in_channels = 1,out_channels = 96,kernel_size = 11,padding = 0,stride = 4),
nn.MaxPool2d(kernel_size = 3,stride = 2),
NiN_blocks(in_channels = 96,out_channels = 256,kernel_size = 5,padding = 2,stride = 1),
nn.MaxPool2d(kernel_size = 3,stride = 2),
NiN_blocks(in_channels = 256,out_channels = 384,kernel_size = 3,padding = 1,stride = 1),
nn.MaxPool2d(kernel_size = 3,stride = 2),
NiN_blocks(in_channels = 384,out_channels = 10,kernel_size = 3,padding = 1,stride = 1),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
return net
NiNNet = NiN()
X = torch.randn(size=(1, 1, 224, 224))
for layer in NiNNet:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)