机器学习笔记之线性回归
机器学习笔记之线性回归
- 目录
-
- 线性回归介绍
- 符号定义
- 最小二乘法主要思想
-
- 最小二乘法求解拟合方程的模型参数
- 模型参数 W \mathcal W W的几何解释
-
- 几何解释1
- 几何解释2
目录
从本节开始将介绍线性回归。
线性回归介绍
线性回归本质上是针对一个或者多个自变量 x x x和因变量 y y y之间的关系进行建模,通过建模得到的函数图像去拟合自变量与因变量构成的数据点。
示例:
构建一个数据点集合表示如下:
通过拟合一条线,使得各样本点到函数图像映射结果之间距离之和最短。
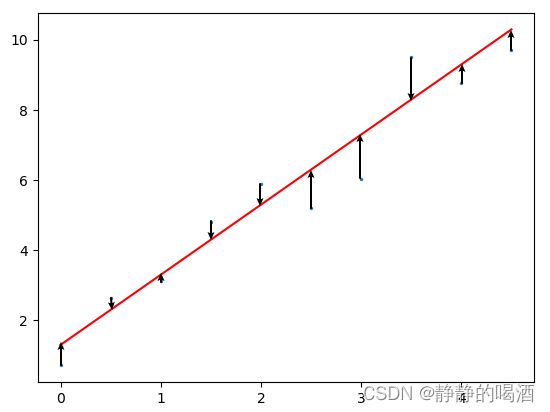
如何构建这条红色线?或者说,在已知样本(蓝色点)的条件下,如何利用样本信息,获取模型参数,从而构建模型来拟合样本?
我们将拟合自变量 x x x与因变量 y y y之间关系的函数称为拟合方程,最小二乘法是常用于求解拟合方程参数的一种工具。
下面将介绍基于自变量 x x x与因变量 y y y的条件下,使用最小二乘法求解拟合方程参数的过程。
符号定义
定义数据集合 D a t a Data Data中包含 N N N个样本,每个样本包含一个自变量 x x x和因变量 y y y:
D a t a = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ⋯ , ( x ( N ) , y ( N ) ) } = { ( x ( i ) , y ( i ) ) } ∣ i = 1 , 2 , ⋯ , N Data = \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots,(x^{(N)},y^{(N)})\} = \{(x^{(i)},y^{(i)})\}|_{i=1,2,\cdots,N} Data={(x(1),y(1)),(x(2),y(2)),⋯,(x(N),y(N))}={(x(i),y(i))}∣i=1,2,⋯,N
其中,任意自变量 x ( i ) ∈ { x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) } x^{(i)} \in \{x^{(1)},x^{(2)},\cdots,x^{(N)}\} x(i)∈{x(1),x(2),⋯,x(N)}是 p p p维随机变量,因变量 y y y是一个标量、实数:
x ( i ) = ( x 1 ( i ) x 2 ( i ) ⋮ x p ( i ) ) x^{(i)} = \begin{pmatrix}x_1^{(i)} \\ x_2^{(i)} \\ \vdots \\ x_p^{(i)}\end{pmatrix} x(i)=⎝ ⎛x1(i)x2(i)⋮xp(i)⎠ ⎞
记作: x ( i ) ∈ R p , y ( i ) ∈ R ( i = 1 , 2 , ⋯ , N ) x^{(i)} \in \mathbb R^{p},y^{(i)} \in \mathbb R(i=1,2,\cdots,N) x(i)∈Rp,y(i)∈R(i=1,2,⋯,N)
将自变量从数据集合中分离出来,用 X \mathcal X X进行表示:
X = ( x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) ) T \mathcal X = (x^{(1)},x^{(2)},\cdots,x^{(N)})^{T} X=(x(1),x(2),⋯,x(N))T
根据上面的介绍,每一个自变量 x ( i ) ( 1 = 1 , 2 , ⋯ , N ) x^{(i)}(1=1,2,\cdots,N) x(i)(1=1,2,⋯,N)都是一个 p p p维列向量。因此,对上述结果继续展开:
X = ( x ( 1 ) T x ( 2 ) T ⋮ x ( N ) T ) = ( x 1 ( 1 ) , x 2 ( 1 ) , ⋯ , x p ( 1 ) x 1 ( 2 ) , x 2 ( 2 ) , ⋯ , x p ( 2 ) ⋮ x 1 ( N ) , x 2 ( N ) , ⋯ , x p ( N ) ) N × p \mathcal X = \begin{pmatrix} {x^{(1)}}^{T} \\ {x^{(2)}}^{T} \\ \vdots \\ {x^{(N)}}^{T} \end{pmatrix} = \begin{pmatrix} x_1^{(1)},x_2^{(1)},\cdots,x_p^{(1)} \\ x_1^{(2)},x_2^{(2)},\cdots,x_p^{(2)} \\ \vdots \\ x_1^{(N)},x_2^{(N)},\cdots,x_p^{(N)} \\ \end{pmatrix}_{N \times p} X=⎝ ⎛x(1)Tx(2)T⋮x(N)T⎠ ⎞=⎝ ⎛x1(1),x2(1),⋯,xp(1)x1(2),x2(2),⋯,xp(2)⋮x1(N),x2(N),⋯,xp(N)⎠ ⎞N×p
同理,因变量 y y y的集合 Y \mathcal Y Y表示如下:
Y \mathcal Y Y是一个列向量。
Y = ( y ( 1 ) , y ( 2 ) , ⋯ , y ( N ) ) T ∣ N × 1 \mathcal Y = (y^{(1)},y^{(2)},\cdots,y^{(N)})^{T}|_{N \times 1} Y=(y(1),y(2),⋯,y(N))T∣N×1
一般情况下,将拟合方程定义为:
这里将偏置项‘归纳进’ W T x \mathcal W^{T}x WTx内部。
f ( W ) = W T x f(\mathcal W) = \mathcal W^{T}x f(W)=WTx
其中,拟合方程参数 W \mathcal W W是 p p p维列向量:
维度为p的目的是要与‘自变量’ x ( i ) ( i = 1 , 2 , ⋯ , N ) x^{(i)}(i=1,2,\cdots,N) x(i)(i=1,2,⋯,N)进行线性运算。
W = ( w 1 w 2 ⋮ w p ) \mathcal W = \begin{pmatrix} w_1 \\ w_2 \\ \vdots \\ w_p \end{pmatrix} W=⎝ ⎛w1w2⋮wp⎠ ⎞
最小二乘法主要思想
针对数据集合 D a t a = { ( x ( i ) , y ( i ) ) } i = 1 , 2 , ⋯ , N Data = \{(x^{(i)},y^{(i)})\}_{i=1,2,\cdots,N} Data={(x(i),y(i))}i=1,2,⋯,N,计算基于样本 x ( i ) x^{(i)} x(i)的拟合方程结果 W T x ( i ) \mathcal W^{T}x^{(i)} WTx(i)和因变量 y ( i ) y^{(i)} y(i)之间的 差距;对样本集合中所有样本的差距进行求和,当求和结果数值最小时,拟合方程 f ( W ) f(\mathcal W) f(W)对数据集合中样本的拟合效果最优。
最小二乘法求解拟合方程的模型参数
最小二乘法公式表达如下:
定义一个函数:该函数表示所有差距和的表现形式:
通常称这种函数为‘策略’——只是一种判别工具;也通常称它为‘损失函数’。
L ( W ) = ∑ i = 1 N ∣ ∣ W T x ( i ) − y ( i ) ∣ ∣ 2 \mathcal L(\mathcal W) = \sum_{i=1}^N ||\mathcal W^{T}x^{(i)} - y^{(i)}||^2 L(W)=i=1∑N∣∣WTx(i)−y(i)∣∣2
由于 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))是数据集合中的具体样本,是已知量;因此,最小二乘法可以看成关于拟合方程参数 W \mathcal W W的函数形式。
继续观察上式,标准式中记录的是向量模的平方。由于 x ( i ) x^{(i)} x(i)是一个 p p p维列向量,则有:
W T x ( i ) − y ( i ) = ( w 1 , w 2 , ⋯ , w p ) ( x 1 ( i ) x 2 ( i ) ⋮ x p ( i ) ) − y ( i ) = w 1 x 1 ( i ) + w 2 x 2 ( i ) + ⋯ + w p x p ( i ) − y ( i ) \mathcal W^{T}x^{(i)} -y^{(i)} = (w_1,w_2,\cdots,w_p)\begin{pmatrix}x_1^{(i)} \\ x_2^{(i)} \\ \vdots \\ x_p^{(i)}\end{pmatrix} - y^{(i)}= w_1x_1^{(i)} + w_2x_2^{(i)} + \cdots + w_p x_p^{(i)} - y^{(i)} WTx(i)−y(i)=(w1,w2,⋯,wp)⎝ ⎛x1(i)x2(i)⋮xp(i)⎠ ⎞−y(i)=w1x1(i)+w2x2(i)+⋯+wpxp(i)−y(i)
该结果就是一个 实数。因此,上面公式可直接表示为:
实际上, L ( W ) \mathcal L(\mathcal W) L(W)自身也是一个实数(标量)。
L ( W ) = ∑ i = 1 N ( W T x ( i ) − y ( i ) ) 2 \mathcal L(\mathcal W) = \sum_{i=1}^N(\mathcal W^{T}x^{(i)} - y^{(i)})^2 L(W)=i=1∑N(WTx(i)−y(i))2
将上述公式表达为符号定义中的矩阵运算格式:
- 将上述公式右侧展开,得到如下结果:
( W T x ( 1 ) − y ( 1 ) ) 2 + ( W T x ( 2 ) − y ( 2 ) ) 2 + ⋯ + ( W T x ( N ) − y ( N ) ) 2 (\mathcal W^{T}x^{(1)} - y^{(1)})^2 + (\mathcal W^{T}x^{(2)} - y^{(2)})^2 + \cdots + (\mathcal W^{T}x^{(N)} - y^{(N)})^2 (WTx(1)−y(1))2+(WTx(2)−y(2))2+⋯+(WTx(N)−y(N))2 - 将上述公式看作为两向量的乘积格式。则有:
( W T x ( 1 ) − y ( 1 ) , W T x ( 2 ) − y ( 2 ) , ⋯ , W T x ( N ) − y ( N ) ) ( W T x ( 1 ) − y ( 1 ) W T x ( 2 ) − y ( 2 ) ⋮ W T x ( N ) − y ( N ) ) \left(\mathcal W^{T}x^{(1)} - y^{(1)},\mathcal W^{T}x^{(2)} - y^{(2)},\cdots,\mathcal W^{T}x^{(N)} - y^{(N)}\right)\begin{pmatrix}\mathcal W^{T}x^{(1)} - y^{(1)} \\ \mathcal W^{T}x^{(2)} - y^{(2)} \\ \vdots \\ \mathcal W^{T}x^{(N)} - y^{(N)}\end{pmatrix} (WTx(1)−y(1),WTx(2)−y(2),⋯,WTx(N)−y(N))⎝ ⎛WTx(1)−y(1)WTx(2)−y(2)⋮WTx(N)−y(N)⎠ ⎞- 观察第一项:可以将该向量向量写成两向量相减的形式:
( W T x ( 1 ) , W T x ( 2 ) , ⋯ , W T x ( N ) ) − ( y ( 1 ) , y ( 2 ) , ⋯ , y ( N ) ) \left(\mathcal W^{T}x^{(1)},\mathcal W^{T}x^{(2)},\cdots,\mathcal W^{T}x^{(N)}\right) - (y^{(1)},y^{(2)},\cdots,y^{(N)}) (WTx(1),WTx(2),⋯,WTx(N))−(y(1),y(2),⋯,y(N)) - 继续化简,将 W T \mathcal W^{T} WT提出:
注意公式中的行向量形式,使用X T , Y T \mathcal X^{T},\mathcal Y^{T} XT,YT替换。
W T ( x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) ) − ( y ( 1 ) , y ( 2 ) , ⋯ , y ( N ) ) = W T X T − Y T \begin{aligned} \mathcal W^{T}(x^{(1)},x^{(2)},\cdots,x^{(N)}) - (y^{(1)},y^{(2)},\cdots,y^{(N)}) = \mathcal W^{T}\mathcal X^{T} - \mathcal Y^{T} \end{aligned} WT(x(1),x(2),⋯,x(N))−(y(1),y(2),⋯,y(N))=WTXT−YT - 观察第二项,由于第二项就是第一项的转置,直接通过第一项结果进行求解:
( W T X T − Y T ) T = X W − Y (\mathcal W^{T}\mathcal X^{T} - \mathcal Y^{T})^{T} = \mathcal X \mathcal W - \mathcal Y (WTXT−YT)T=XW−Y
- 观察第一项:可以将该向量向量写成两向量相减的形式:
至此,我们将损失函数 L ( W ) \mathcal L(\mathcal W) L(W)表示为如下形式:
展开~
L ( W ) = ( W T X T − Y T ) ( X W − Y ) = W T X T X W − Y T X W − W T X T Y + Y T Y \begin{aligned} \mathcal L(\mathcal W) & = (\mathcal W^{T}\mathcal X^{T} - \mathcal Y^{T})(\mathcal X \mathcal W - \mathcal Y) \\ & = \mathcal W^{T}\mathcal X^{T}\mathcal X \mathcal W - \mathcal Y^{T}\mathcal X \mathcal W - \mathcal W^{T}\mathcal X^{T}\mathcal Y + \mathcal Y^{T}\mathcal Y \\ \end{aligned} L(W)=(WTXT−YT)(XW−Y)=WTXTXW−YTXW−WTXTY+YTY
观察中间两项: Y T X W \mathcal Y^{T}\mathcal X \mathcal W YTXW和 W T X T Y \mathcal W^{T}\mathcal X^{T}\mathcal Y WTXTY:
- Y T X W \mathcal Y^{T}\mathcal X \mathcal W YTXW中 Y T \mathcal Y^{T} YT是 1 × p 1 \times p 1×p维向量; X \mathcal X X是 p × p p \times p p×p维向量; W \mathcal W W是 p × 1 p \times 1 p×1维向量;最终乘积结果是 1 × 1 1 \times 1 1×1维的向量,即标量、实数;
- 同理, W T X T Y \mathcal W^{T}\mathcal X^{T}\mathcal Y WTXTY中 W T \mathcal W^{T} WT是 1 × p 1 \times p 1×p维向量; X T \mathcal X^{T} XT是 p × p p \times p p×p维向量; Y \mathcal Y Y是 p × 1 p \times 1 p×1维向量;最终乘积结果同样也是标量、实数。
- 并且, Y T X W \mathcal Y^{T}\mathcal X \mathcal W YTXW和 W T X T Y \mathcal W^{T}\mathcal X^{T}\mathcal Y WTXTY之间存在如下关系:
( Y T X W ) T = W T X T Y (\mathcal Y^{T}\mathcal X \mathcal W)^{T} = \mathcal W^{T}\mathcal X^{T}\mathcal Y (YTXW)T=WTXTY
至此,我们得到结果:
W T X T Y = Y T X W \mathcal W^{T}\mathcal X^{T}\mathcal Y = \mathcal Y^{T}\mathcal X \mathcal W WTXTY=YTXW
因此, L ( W ) \mathcal L(\mathcal W) L(W)可以继续化简为:
L ( W ) = W T X T X W − 2 W T X T Y + Y T Y \mathcal L(\mathcal W) = \mathcal W^{T}\mathcal X^{T}\mathcal X \mathcal W - 2\mathcal W^{T}\mathcal X^{T}\mathcal Y + \mathcal Y^{T}\mathcal Y L(W)=WTXTXW−2WTXTY+YTY
基于最小二乘法的思想,目的是求解一个最优 W ^ \hat {\mathcal W} W^,使得:
W ^ = arg min W L ( W ) \hat{\mathcal W} = \mathop{\arg\min}\limits_{\mathcal W}\mathcal L(\mathcal W) W^=WargminL(W)
基于该思路,对 L ( W ) \mathcal L(\mathcal W) L(W)关于 W \mathcal W W求导:
这里用到了矩阵求导的相关知识,大家一起去恶补矩阵论吧。
∂ L ( W ) ∂ W = 2 X T X W − 2 X T Y \frac{\partial \mathcal L(\mathcal W)}{\partial \mathcal W} = 2\mathcal X^{T}\mathcal X\mathcal W - 2\mathcal X^{T} \mathcal Y ∂W∂L(W)=2XTXW−2XTY
令 ∂ L ( W ) ∂ W ≜ 0 \frac{\partial \mathcal L(\mathcal W)}{\partial \mathcal W} \triangleq 0 ∂W∂L(W)≜0,则有:
X T X W = X T Y W = ( X T X ) − 1 X T Y \mathcal X^{T}\mathcal X\mathcal W = \mathcal X^{T}\mathcal Y \\ \mathcal W = (\mathcal X^{T} \mathcal X)^{-1}\mathcal X^{T} \mathcal Y XTXW=XTYW=(XTX)−1XTY
至此,基于最小二乘估计算法,拟合方程 f ( W ) = W T x f(\mathcal W) = \mathcal W^{T}x f(W)=WTx的模型参数 W \mathcal W W的矩阵形式表达。
模型参数 W \mathcal W W的几何解释
几何解释1
观察 L ( W ) \mathcal L(\mathcal W) L(W)的标准式:
L ( W ) = ∑ i = 1 N ( W T x ( i ) − y ( i ) ) 2 \mathcal L(\mathcal W) = \sum_{i=1}^N(\mathcal W^{T}x^{(i)} - y^{(i)})^2 L(W)=i=1∑N(WTx(i)−y(i))2
可以将其视为一个总误差:将所有误差分散在了每一个自变量中,如上图表示的箭头,箭头的长度表示误差的具体数值,这些数值有正有负(分别位于函数图像的上方与下方)。
取平方最朴素的思想即确定误差数值的符号均为正。总误差即所有所有样本构成的误差数值的总和;
几何解释2
如果将拟合函数进行变换:
f ( W ) = W T x ( i ) = x ( i ) T β f(\mathcal W) = \mathcal W^{T}x^{(i)} ={x^{(i)}}^{T}\beta f(W)=WTx(i)=x(i)Tβ
其中 W \mathcal W W和 β \beta β向量维度相同,即 p × 1 p \times 1 p×1。
因此,将 x T β x^{T}\beta xTβ进行展开:
x ( i ) T β = ( x 1 ( i ) , x 2 ( i ) , ⋯ , x p ( i ) ) ( β 1 β 2 ⋮ β p ) = x 1 ( i ) β 1 + x 2 ( i ) β 2 + ⋯ + x p ( i ) β p \begin{aligned} {x^{(i)}}^{T}\beta & = (x_1^{(i)},x_2^{(i)},\cdots,x_p^{(i)})\begin{pmatrix}\beta_1 \\ \beta_2 \\ \vdots \\\beta_p\end{pmatrix}\\ & = x_1^{(i)}\beta_1 + x_2^{(i)}\beta_2 + \cdots + x_p^{(i)}\beta_p \end{aligned} x(i)Tβ=(x1(i),x2(i),⋯,xp(i))⎝ ⎛β1β2⋮βp⎠ ⎞=x1(i)β1+x2(i)β2+⋯+xp(i)βp
观察发现, x ( i ) T β {x^{(i)}}^{T}\beta x(i)Tβ和 W T x ( i ) \mathcal W^{T}x^{(i)} WTx(i)的格式相同,其结果都是一个标量、实数。如果 将 x ( i ) T β {x^{(i)}}^{T}\beta x(i)Tβ结果与 p p p维空间中的原点相连,构成一个向量,可以将 x 1 ( i ) β 1 , x 2 ( i ) β 2 , ⋯ , x p ( i ) β p x_1^{(i)}\beta_1,x_2^{(i)}\beta_2,\cdots,x_p^{(i)}\beta_p x1(i)β1,x2(i)β2,⋯,xp(i)βp看做 p p p维空间中每个维度空间的分量。
同理,自变量 x ( i ) x^{(i)} x(i)对应的因变量 y ( i ) y^{(i)} y(i)同样 也是一个数值,该值与 p p p维空间中的原点相连也会得到一个向量。什么时候 y ( i ) y^{(i)} y(i)对应的向量和 x ( i ) T β {x^{(i)}}^{T}\beta x(i)Tβ对应的向量是最接近的:
即 x ( i ) T β {x^{(i)}}^{T}\beta x(i)Tβ向量在各个维度的分量均在 y ( i ) y^{(i)} y(i)对应向量在 p p p维空间中,每个维度空间中的投影上。
如果满足上述条件, y ( i ) − x ( i ) T β y^{(i)} - {x^{(i)}}^{T}\beta y(i)−x(i)Tβ表示 p p p维度空间中各维度自变量的拟合方程结果与因变量之间的距离向量。如果满足上述条件,该 距离向量 应该与 自变量 x ( i ) x^{(i)} x(i)向量在各维度的分量相垂直,只有垂直情况下,两向量之间距离最近。
y ( i ) − x ( i ) T β y^{(i)} - {x^{(i)}}^{T}\beta y(i)−x(i)Tβ不仅要和 x ( i ) T β {x^{(i)}}^{T}\beta x(i)Tβ相垂直,而是和 x ( i ) T β {x^{(i)}}^{T}\beta x(i)Tβ所在 p p p维超平面相垂直,因此就要和自变量的每一个维度相垂直。
则有:
两向量夹角90,向量乘积结果为0
x ( i ) T ( y ( i ) − x ( i ) T β ) = 0 {x^{(i)}}^{T}(y^{(i)} - {x^{(i)}}^{T}\beta) = 0 x(i)T(y(i)−x(i)Tβ)=0
同理,所有自变量 x ( i ) ( i = 1 , 2 , ⋯ , N ) x^{(i)}(i=1,2,\cdots,N) x(i)(i=1,2,⋯,N)与对应的因变量 y ( i ) ( 1 = 1 , 2 , ⋯ , N ) y^{(i)}(1=1,2,\cdots,N) y(i)(1=1,2,⋯,N)都有相同关系。
因此,矩阵表达方式如下:
X T ( Y − X β ) = 0 \mathcal X^{T}(\mathcal Y - \mathcal X\beta) = 0 XT(Y−Xβ)=0
将上式展开移项:
X T Y = X T X β β = ( X T X ) − 1 X T Y \mathcal X^{T} \mathcal Y = \mathcal X^{T}\mathcal X\beta \\ \beta = (\mathcal X^{T} \mathcal X)^{-1}\mathcal X^{T} \mathcal Y XTY=XTXββ=(XTX)−1XTY
下一节将介绍从概率视角认识最小二乘法
相关参考:
机器学习-白板推导系列(三)-线性回归(Linear Regression)