《Learning Selective Self-Mutual Attention for RGB-D》论文阅读笔记
Learning Selective Self-Mutual Attention for RGB-D Saliency Detection–RGB-D
显著性检测的学习选择性自相互注意,来自CVPR2020。
1 Motivation
-
相比于传统的RGB显著性检测方法,包含深度信息的RGB-D检测可以更好地识别出图像的阳性区域。
-
以往的RGB-D检测使用的融合策略(如早期融合、结果融合)作用有限。
2 Contribution
-
基于Non-Local,提出一种新的中间融合策略,通过融合深度注意,准确定位出对象的主体。
-
将注意力机制应用于双流CNN模型,并引入新的残差融合模块,提高了显著性检测的性能,优于所有现存方法。
3 Approach
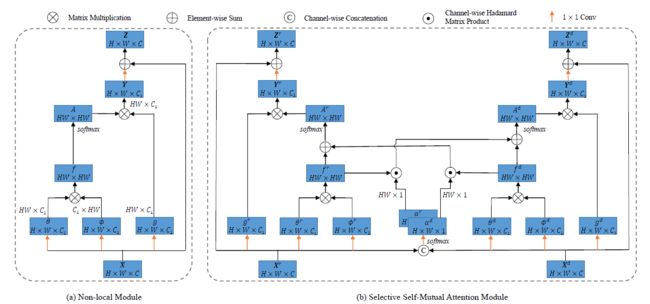
本文使用的注意力模型基于Non Local,是在此基础上进行的改进。整个模型框架如下图右侧图像所示:
 如上图所示,不包含深度信息的RGB方法的检测结果含有很严重的假阳性高亮区域。
如上图所示,不包含深度信息的RGB方法的检测结果含有很严重的假阳性高亮区域。
3.1 Non Local模块
首先简要介绍一种non local模块,如上图左侧部分所示,Non Local模型首先将输入的feature map X \boldsymbol{X} X用三个不同权值的1×1卷积层嵌入到三个通道数均为 C 1 C_1 C1的特征空间中。
之后,计算经过 W θ W_{\theta} Wθ与 W ϕ W_{\phi} Wϕ嵌入之后的 X \boldsymbol{X} X两个不同视图每个像素点之间的相关性。此处的计算方法是简单的矩阵乘法:
f ( X ) = θ ( X ) ϕ ( X ) ⊤ f(\boldsymbol{X})=\theta(\boldsymbol{X}) \phi(\boldsymbol{X})^{\top} f(X)=θ(X)ϕ(X)⊤
然后,使用softmax对 f ( X ) f(\boldsymbol{X}) f(X)进行行归一化处理得到 X \boldsymbol{X} X的注意力矩阵,第 i i i一行即表示像素点 i i i与其他点之间的注意力权重情况。
A ( X ) = s o f t m a x ( f ( X ) ) A(\boldsymbol{X})=softmax(f(\boldsymbol{X})) A(X)=softmax(f(X))
再将得到的注意力矩阵与 X \boldsymbol{X} X的另一个嵌入视图 g ( X ) g(\boldsymbol{X}) g(X)相乘,即得到最终的包含注意力信息的特征 Y \boldsymbol{Y} Y
Y = A ( X ) g ( X ) \boldsymbol{Y}=A(\boldsymbol{X})g(\boldsymbol{X}) Y=A(X)g(X)
最后,引入一个残差模块,得到最终的输出特征:
Z = Y W Z + X \boldsymbol{Z}=\boldsymbol{Y}W_\boldsymbol{Z}+\boldsymbol{X} Z=YWZ+X
3.2 自-互注意力
Non Local模块本质上是对自身特征的双线性投影,属于self-attention的范畴,在此基础上,作者提出引入相互注意力,以提升RGB-D任务定义多模态特征的显著性检测水平,因此提出了如上图所示右侧的网络架构,称为SMA(Self-Mutual Attention)。SMA的思路如下:
对于给定的图像在RGB模态与D模态下的feature map X r \boldsymbol{X}^r Xr与 X d \boldsymbol{X}^d Xd,基于NL模型,计算二者各自的相关性矩阵 f ( X r ) f(\boldsymbol{X}^r) f(Xr)与 f ( X d ) f(\boldsymbol{X}^d) f(Xd),将二者通过简单相加的方法进行融合,得到一个新的注意力矩阵:
A f ( X r , X d ) = s o f t m a x ( f r ( X r ) + f d ( X d ) ) A^f(\boldsymbol{\boldsymbol{X}^r,\boldsymbol{X}^d})=softmax(f^r(\boldsymbol{X}^r)+f^d(\boldsymbol{X}^d)) Af(Xr,Xd)=softmax(fr(Xr)+fd(Xd))
使用融合注意力矩阵代替各自的注意力矩阵计算 X r \boldsymbol{X}^r Xr与 X d \boldsymbol{X}^d Xd各自的注意力特征,得到最终的输出特征 Z r \boldsymbol{Z}^r Zr与 Z d \boldsymbol{Z}^d Zd。
作者认为融合注意力矩阵相比于各自独立的注意力矩阵包含了RGD与D模态下的注意力信息,使得学习到的注意力更加准确,并且在实验中切实提高了模型表现。
3.3 选择性自-互注意力
SMA模型对于RGB模态与Deep模态之间的自注意力与相互注意力的选择是平等的,然而作者认为相互注意力并不总是在所有位置都可靠,可能会产生负面干扰。因此作者引入了一个选择机制,对相互注意力的引入程度进行了一定控制。
具体来说,首先将RGB模态与D模态下的feature map X r \boldsymbol{X}^r Xr与 X d \boldsymbol{X}^d Xd拼接成一个张量,维度是[H, W, 2C],之后经过一个1×1的矩阵进行embedding处理之后,经过softmax处理得到选择注意力矩阵,维度是[H, W, 2]:
α = s o f t m a x ( Conv ( [ X r , X d ] ) ) \alpha=softmax\left(\operatorname{Conv}\left(\left[\boldsymbol{X}^{r}, \boldsymbol{X}^{d}\right]\right)\right) α=softmax(Conv([Xr,Xd]))
将 α \alpha α进行拆分,得到模态RGD与D各自的 α r \alpha^r αr与 α d \alpha^d αd,维度是[H, W, 1],代表每个模态在所有位置上对应的可靠性,即在进行注意力融合时选择的权重,将其带入SMA的注意力矩阵计算公式,得到最终的注意力计算法则:
A r ( X r , X d ) = s o f t m a x ( f r ( X r ) + α d ⊙ f d ( X d ) ) A d ( X r , X d ) = s o f t m a x ( f d ( X d ) + α r ⊙ f r ( X r ) ) A^r(\boldsymbol{\boldsymbol{X}^r,\boldsymbol{X}^d})=softmax(f^r(\boldsymbol{X}^r)+\alpha^d{\odot}f^d(\boldsymbol{X}^d)) \\ A^d(\boldsymbol{\boldsymbol{X}^r,\boldsymbol{X}^d})=softmax(f^d(\boldsymbol{X}^d)+\alpha^r{\odot}f^r(\boldsymbol{X}^r)) Ar(Xr,Xd)=softmax(fr(Xr)+αd⊙fd(Xd))Ad(Xr,Xd)=softmax(fd(Xd)+αr⊙fr(Xr))
⊙ {\odot} ⊙代表通道间的点乘操作,这个模型称为 S 2 M A S^2MA S2MA
4 RGD-D显著性检测网络

本文的网络架构采用的是Unet的架构,首先提取RGB图与Deep图各自的特征,再经过一个Dense ASPP模块,分别提取到512个通道的张量,送入本文所提出的 S 2 M A S^2MA S2MA模块获取注意力特征,之后经过一个Unet网络,得到最终的显著性结果。
5 实验
本文使用了七个RGB-D的数据集进行模型能力的评估,分别是:
- NJUD:拥有1985张从互联网上搜集到的、从3D电影图片和立体照片中获取的图片;
- NLPR和RGBD135:分别包含1000和135张由微软Kinect采集到的图片;
- LFSD:包含100张由Lytro光场相机捕获的图片;
- STERE:包含1000对从互联网上下载的双目图像;
- SSD:包含八十张立体电影帧;
- DUT-RGBD:包含1200张Lytro2相机捕获的图片。
本文使用了四个评价指标评估模型的性能,分别是:
- maxF:最大F测量,评价二值化显著性图的精度和召回率,是精度和召回率的加权平均;
- S m S_m Sm:结构度量,评价显著性图与ground truth之间区域感知和目标感知的结构相似性;
- E ξ E_{\xi} Eξ:测量显著性图的全局统计信息与局部像素匹配信息;
- MAE:平均绝对误差,测量显著性图与ground truth之间每个像素差值绝对值得平均水平。
5.1 消融实验
设置了本文不同网络组成结构的组合下模型的表现结果,如下图所示:

蓝色表示最佳水平,可以发现,本文方法比NL和SMA都要更好一些。
作者还可视化了他们在红色查询点下,RGB自注意、Depth自注意与他们的方法获得的自-互注意图的注意力图。

5.2 显著性模型有效性评估
作者比较了他们的方法与其他先进方法(前三种是传统模型方法,后八种是深度学习模型方法)之间的显著性检测水平,红色是最好的表现,蓝色是第二好的表现。

此外,作者同时进行了定性评价,可视化了不同方法的显著性检测结果。